
GPT 3 (2020) 논문 리뷰
GPT-3의 논문 이름은 Language Models are Few-Shot Learners다. (링크)
저자는 Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei다.
Unsupervised pre-train 이후 fine-tuning이 아닌 pre-train 만으로 충분히 좋은 성능을 낼 수 있는 가능성을 보여준 논문이다.
GPT3에는 여러가지 모델 사이즈가 있지만 가장 큰 모델은 175B로 본격적인 LLM의 시대를 개막했다고 생각한다.
GPT3 부터 OpenAI는 모델의 소스 코드를 공개하지 않는다.
GPT-3에서는 In-Context Learning (ICL)이라는 개념의 본격적으로 사용한 프롬프트 엔지니어링을 적극적으로 사용했다.
Abstract
최근 연구에서도 pre-train 후 fine-tune하는 방법이 대부분이다. 하지만 사람은 새로운 언어를 배울 때 몇개의 예제와 간단한 지도 (instructions)만으로도 충분히 배운다. 본 논문에서 저자들은 언어 모델의 규모를 키움으로써 굉장히 좋은 성능의 task-agnostic, and few-shot 성능을 보일 수 있다고 한다. GPT-3는 모든 태스크에 대해서 그라디언트 업데이트나 파인 튜닝 없이 few-shot demonstrations만으로 해결한다. 번역, 문답 (QA), 그리고 빈칸 채우기 (cloze test) 등의 여러가지 NLP 태스크를 포함한다.
Introduction

현재까지의 방법은 대규모 레이블된 데이터가 필요해서 제한적이다.
파인 튜닝은 매우 좁은 학습 분포 (training distribution)을 학습하므로 일반화의 가능성이 낮아진다.
마지막으로 인간은 몇개의 예시만으로도 충분히 학습이 가능하다.
이를 위해서 우리는 In-context Learning (ICL)의 개념을 도입한다.
Figure 1.1에서 볼 수 있듯이 ICL이란 특정한 예시를 하나의 시퀀스로 만들어서 모델에게 알려주는 방식이다.
ICL의 종류
ICL은 예시의 개수로 3가지로 나눌 수 있다.
(a): few-show learning으로 여러개의 예시를 context로 보여준다. Context의 개수는 context window라고 하며 보통 10개에서 100개다.
(b): one-shot learning은 오직 하나의 예시만을 컨텍스트로 보여준다.
(c): zero-shot learning은 예시 없이 instruction (지시)만을 포함한다.
Figure 1.2과 Figure 1.3을 보면 Few-shot이 One shot이나 Zero shot보다 좋은 성능임을 알 수 있다
2. Approach
Pre-training에서 모델의 사이즈, 데이터의 사이즈와 다양성 그리고 학습 길이를 직접적으로 증가시킨 것 외에는 GPT2와 동일하다.
특정한 태스크에 대한 데이터에 대해서는 Fine-Tuning (FT), Few-Shot (FS), One-Shot (1S), Zero-Shot (0S)를 수행하고 이를 비교한다.
자세한 내용은 Figure 2.1에 나와 있다.

Zero, One, Few-shot은 앞에서 언급했듯이 예시의 개수로 나눈다.
2.1. Model and Architectures

GPT3는 Small의 125M 부터 가장 대표적인 모델인 175B짜리 모델까지 다양한 파라미터를 지닌다.
Sparse Transformer (논문 링크) 와 같은 alternating dense and locally banded sparse attention을 사용한다.
Sparse Transformer는 Longformer에서 살펴본 바와 같이 Full-attention과 Dilated attention을 비교하는데 이를 encoder가 아닌 causal decoder의 측면에서 살펴본 논문이다. 그리고 이미지와 텍스트 양쪽 모두에 적용한 논문이다.

Scaling Laws for Neural Language Models 논문 (링크)에서 언급한 바와 같이 충분한 양의 학습 데이터에 의해서 validation loss의 스케일은 smooth power law를 따른다.
2.2. Training Dataset
Common Crawl은 굉장히 크기가 크고 많이 사용되는 데이터지만 낮은 퀄리티를 지닌다.
이를 해결하기 위해서 3 단계를 거쳐서 평균적인 퀄리티를 향상시킨다.
1) Common Crawl을 다운로드한 다음 고품질의 레퍼런스가 되는 말뭉치들 (corpora)와 유사도를 비교하여 필터한다.
2) Fuzzy dedupliation을 문서 레벨에서 수행하는데 모든 데이터셋을 같이 참조해서 수행한다. 이는 redundancy (불필요한 반복)과 integrity (온전함? 완전성?) of our held-out validation을 위해서다. 즉 학습과 발리데이션 데이터의 중복을 방지하여, 단순한 암기가 아닌 진정한 오버피팅에 대한 정확한 측정을 가능하게 한다.
3) 고품질의 레퍼런스 말뭉치들을 필터링한 Common Crawl에 추가하여 다양성을 높인다.
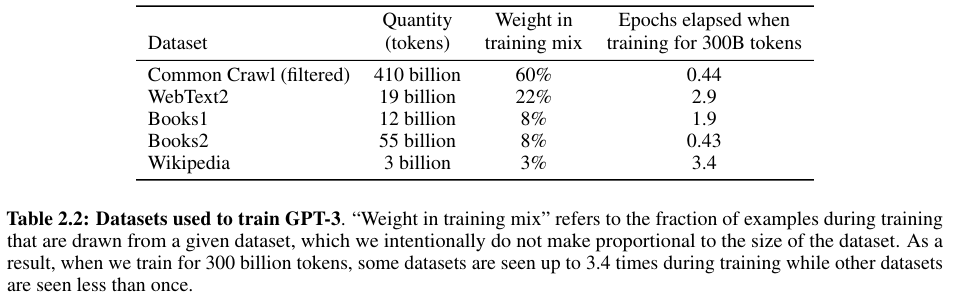
WebText2, Books1, Book2, Wikipedia의 4가지 사용한다.
2.3. Training Process
An empirical model of large-batch training 논문 (링크)와 Scaling Laws for Neural Language Models 논문 (링크)에서 이미 밝혔듯이 더 큰 배치 사이즈를 사용할 때는 더 작은 학습 률 (learning rate)가 요구된다.
더 큰 배치 사이즈는 더 다양한 데이터를 포함하며 더 많은 그라디언트가 누적된다. 따라서 lr이 작아야 너무 많이 업데이트를 하는 상황을 방지하여 로컬 옵티마에 빠지는 오류를 피할 수 있다.
다음의 Figure 2.2는 파라미터의 크기와 필요한 연산량을 보여준다.

자세한 내용은 Appendix B에 나와있다.
2.4. Evaluation
Few-shot의 경우 랜덤하게 K개의 예시를 뽑아서 학습할 때 사용한다. 이는 1 혹은 2의 새로운 라인이며 구분된다.
LAMBADA놔 Storycloze의 경우 supervised 학습 데이터가 없으므로 development set에서 예시를 뽑은 다음 test set에 대해서 평가했다.
K는 0부터 모델의 context window 사이즈까지의 값을 갖는다. 모든 모델에 대해서 $n_ctx - 2048$이므로 보통 10부터 100까지의 예시를 갖는다. K가 클수록 보통은 더 좋지만 항상 그렇지는 않다. 자세한 내용은 Appendix G에 나와있다.
Multiple choice 문제의 경우는 아래와 같이 처리한다. 설명이 어려워서 Appendix의 예시를 가져왔다.

Free-form completion (주관식)의 경우 beam search with widdth 4와 length penalty of $\alpha = 0.6$을 사용한다.
그리고 F1 similarity score, BLEU, Exact Match 등 데이터셋에 따라서 수행한다.
Beam Search
Beam Search는 매번 가장 확률이 높은 토큰을 고르는 방식과 다르게 Top-K개를 남기는 방식을 말한다.
- 1단계에서는 1개로 이루어진 토큰들의 확률의 곱을 토대로 Top-K만을 남긴다.
- 2단계에서는 1단계에서 남긴 K개의 토큰들을 토대로 다음 토큰들을 예측한다.
그렇다면 2단계에서는 2개로 이루어진 토큰들의 확률의 곱을 토대로 가장 확률이 큰 K개만 남긴다. - 위 과정을 거쳐서 <eos> 문장의 끝을 나타내는 특수한 토큰을 만나는 토큰들의 시퀀스의 개수가 K개 남을 때 까지 반복한다.
3. Results

Smooth scaling of performance with compute 결과다.
GPT3에서 워낙 많은 데이터를 다루어서 피규어나 테이블을 다 가져오는 것은 과한것 같아서 생략한다.
살펴 보면 대부분 Few-shot의 성능이 One이나 Zero shot 보다 좋다는 사실을 확인할 수 있다.
그리고 전체 성능표 대신 평가의 종류와 그에 사용한 데이터셋의 리스트를 적는다.
1. Language Modeling, Cloze and Completion Tasks
빈칸을 채우는 문제 혹은 이어지는 문장으로 옳은 것을 고르는 문제다.
LAMBADA
StoryCloze
HellaSwag (뒤에 오는 문장 다지선다 선택)
2. Closed Book Question Answering
질의 응답 데이터다
TriviaQA
WebQs
3. Translation
WMT En → Fr, Fr → En, En → De, De → En, En → Ro, Ro → En
4. Winograd-Style Tasks
상황에 따른 대명사 (pronoun)을 선택하는 문제다.
Winograd
4. Common Sense Reasoning
상식 추론 문제다.
PIQA (물리 추론)
ARC (3에서 9학년 과학 문제)
OpenBookQA
5. Reading Comprehension
추상적 문제, 다지선다 문제, 범위 기반 답변을 포함한 문제다.
CoQA
QuAC
DROP
SQuAD 2.0
RACE
6. SuperGLUE
GLUE 보다 어려운 문제의 집합으로 QA, NLI, RC 등 다양한 문제를 포함한다.
BoolQ
CB
COPA
RTE
WiC
WSC
MultiRC
ReCoRD
7. NLI (Natural Language Inference)
RTE in SuperGLUE
ANLI
8. Synthetic and Qualitative Tasks
GPT의 few-shot 능력을 알아보기 위한 쉬운 문제들이다.
Arithmetic (사칙연산)
2자리 덧셈, 뺄셈
3자리 덧셈, 뺄셈
등등 을 포함한다.
9. Word Scrambling and Manipulation Tasks
문자의 철자를 일부 변형하고 이를 고칠 수 있는지를 살펴본다.
10. SAT Analogies
2005년 이전의 374개의 SAT 문제다. Multiple choice다.
11. News Article Generation
뉴스 기사를 생성하는 능력 평가.
GPT3가 생성한 기사를 사람이 직접 평가한다.
총 5개의 척도로 평가한다.
12. Learning and Using Novel Words
현재 존재하지 않는 단어를 few-shot으로 예시로 주고 이를 통해서 문장을 생성하도록 하고 얼마나 적절한지 평가한다.
13. Correct English Grammar
영어 문법 교정
6. Broader Impacts
오용이나 남용을 경계해야 한다고 적은 섹션이다.
Bias, Fairness 등을 고려해야 한다.
특히 Gender, Race, Religion을 잘 고려해야 한다고 말한다.
References:
https://velog.io/@wkshin89/Paper-Review-Scaling-Laws-for-Neural-Language-Models
https://medium.com/deep-learning-experiments/effect-of-batch-size-on-neural-net-training-c5ae8516e57
https://blog.naver.com/sooftware/221809101199
https://littlefoxdiary.tistory.com/4
https://medium.com/@jiangmen28/next-token-prediction-task-with-bff7e7aa8e38