OPT (2022) 논문 리뷰
OPT의 논문 이름은 OPT: Open Pre-trained Transformer Language Models다. (링크)
저자는 Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, Luke Zettlemoyer다.
메타 (페이스북)에서 공개한 오픈 소스 Decoder LLM 모델이다.
Abstract
OPT는 GPT3처럼 125M 부터 175B의 파라미터의 모델을 만들고 성능을 비교한다.
2. Method

레이어, 헤드, 모델의 차원, 학습률, 배치사이즈는 Table 1와 같다.
Megatron-LM의 코드베이스에서 사용한 weight initilization을 사용했다.
정규분포 N(0, 0.006)에서 랜덤하게 뽑는다.
Output layer의 standard deviation은 1.0 / $\sqrt{2L}$로 스케일링 된다.
모든 bias는 0으로 시작한다.
Activation은 ReLU이며 sequence length는 모두 2048이다.
AdamW optimizer를 사용하며 ($\beta_1, \beta_2$) = (0.9, 0.95)이며 weight decay는 0.1이다.
Linear learning schedule을 사용한다.
Warm up steps는 2000이다.
Dropout은 0.1이며 embeddings에는 적용하지 않는다.
Gradient clip은 1.0으로 설정했다.
Pre-training Corpus
RoBERTa에서 사용한 BookCorpus와 Stories, CCNews V2
The Pile
PushShift.io Reddit
위 데이터들을 모두 사용했다.
The Pile은 800GB의 대용량 데이터로 여러가지 데이터를 한 군데 모은 데이터다.
자세한 내용은 논문 (링크)를 참조하면 된다.
3. Evaluations
Prompting and Few-shot
총 16개의 NLP 태스크에 대해서 평가를 수행한다.
HellaSwag, StoryCloze, PIQA, ARC Easy and Challenge, OpenBookQA, WinoGrad, WinoGrande, SuperGLUE다.
Zero, One, Few-shot을 수행한다.

GPT-3처럼 Few-shot이 Zero나 One-shot 보다 좋은 성능임을 알 수 있다.
Dialogue
ConvAI2, Wizard of Wikipedia, Empathetic Dialogues, Blended Skill Talk 데이터를 이용해서 대화에 대한 평가를 수행한다.

Reddit 2.7B나 BlenderBot 1, R2C2 BlenderBot 등 기존 모델에 근접한 성능을 보여준다.
4. Bias & Toxicity Evaluations
Hate Speech Detection
ETHOS 데이터 셋을 통해서 racist나 sexist 적인 대화인지를 평가한다.
CrowS-Pairs
Gender, religion, race/color, sexual orientation, age, nationality, disability, physical appearance, and socioeconomic status의 편견들을 포함한 데이터셋이다.
StereoSet
Profession, gender, religion and race에 대한 편견을 다룬 데이터다.


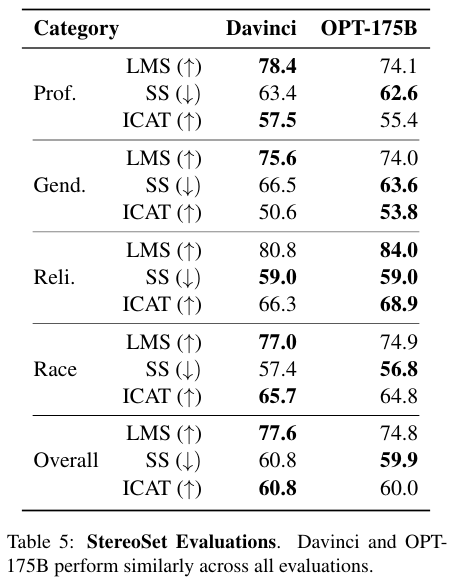
전체적으로 GPT3 보다는 약간 못하고, Davinci 모델 보다는 좋은 성능임을 확인할 수 있다.
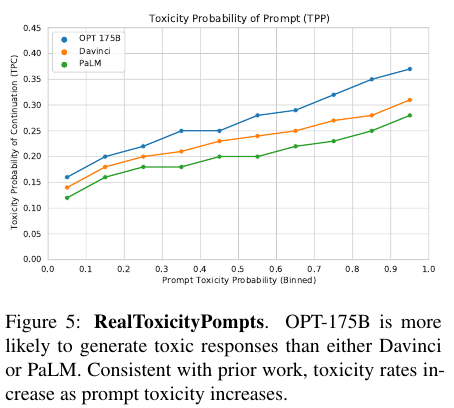
OPT는 Davinci에 비해서 좋은 성능을 보이지만 보다 toxic한 언어 프롬프트에 대해서 toxic한 답변을 더 잘 생성하는 경향을 보이는 단점이 존재한다. 이는 RealToxicityPrompts 데이터 셋을 사용해서 평가했다.