LLaMA 2 (2023) 논문 리뷰
LLaMA 2의 논문 이름은 Llama 2: Open Foundation and Fine-Tuned Chat Models다. (링크)
저자는 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom다.
LLaMA 의 두 번째 모델이다.
Abstract
Llama2는 7B 부터 70B 까지의 스케일을 지니는 pretrained and fine-tuned LLM의 모음이다.
파인 튜닝된 모델 중 하나인 LLAMA 2-CHAT은 대화에 최적화된 모델이다.
1. Introduction
Llama 2는 Llama 1의 개선된 버젼으로 새로운 공개된 데이터들의 혼합으로 학습했다. 학습 토큰을 40% 증가시켰으며 grouped-query attention을 도입했다. Llama2의 모델 사이즈는 7B, 13B, 34B, 70B가 있다. 34B는 논문에서는 언급되지만 공개하지는 않았다.
Llama 2-Chat은 7N, 13B, 70B 사이즈의 대화에 최적화된 모델이다.


Lllama 2는 사람에게 더 안전하며 유용한 모델임을 Figure 1, 2, 3을 통해서 보여주고 있다.

위 Figure 4에서는 Llama 2-Chat의 학습 과정을 보여준다.
우선 Pretraining 데이터를 이용해서 self-supervised learning으로 Llama 2를 학습시킨다.
그 다음 supervised fine-tuning과 RLHF를 통해서 Llama 2-Chat을 파인튜닝한다.
2. Pretraining
Pretraining data
공개적으로 사용 가능한 새로운 데이터를 포함하며 메타의 제품이나 서비스는 포함하지 않았다.
총 2 T 개의 토큰으로 학습을 진행했다.

Table 10에 보면 대부분의 데이터가 영어임을 알 수 있다.
Architecture
모델의 구조는 Llama 1의 구조와 유사하다. 표준적인 transformer 구조, pre-normalization을 RMSnorm으로 수행하고, SwiGLU를 activation function으로 사용하고, rotary positional embedding을 사용한다. 추가적으로 grouped-query attention (GQA)를 적용했다. Context length는 4k = 4096이다.
Hyperparameters
AdamW 옵티마이저, $\beta_1$은 0.9, $\beta_2$는 0.95, eps = 1e-5, cosine learning rate schedule을 사용했다.
Warmup steps는 2000이다. Final learning rate는 피크 학습률의 10%까지 줄인다.
Weight decay는 0.1, gradient clipping은 1.0으로 설정한다.
Tokenizer
BPE를 이용한 SentencePiece를 사용했다. UTF-8 인코딩을 사용했으며 Vocab size는 32 K다.
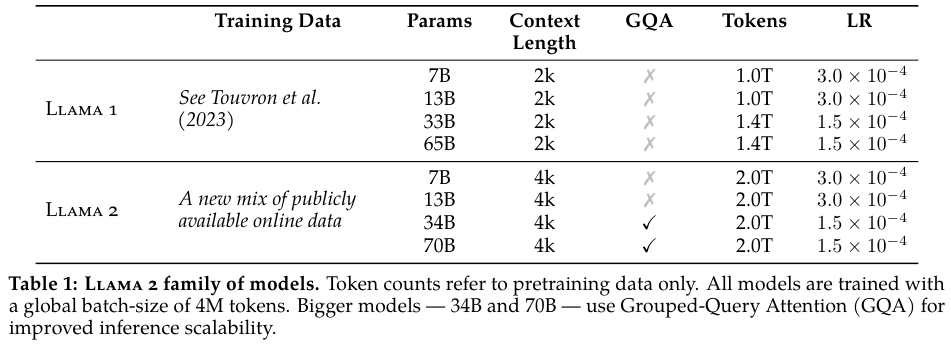
Table 1에서는 Llama 1과 Llama 2의 파라미터 수, 토큰 수, context length 수, LR을 보여준다.
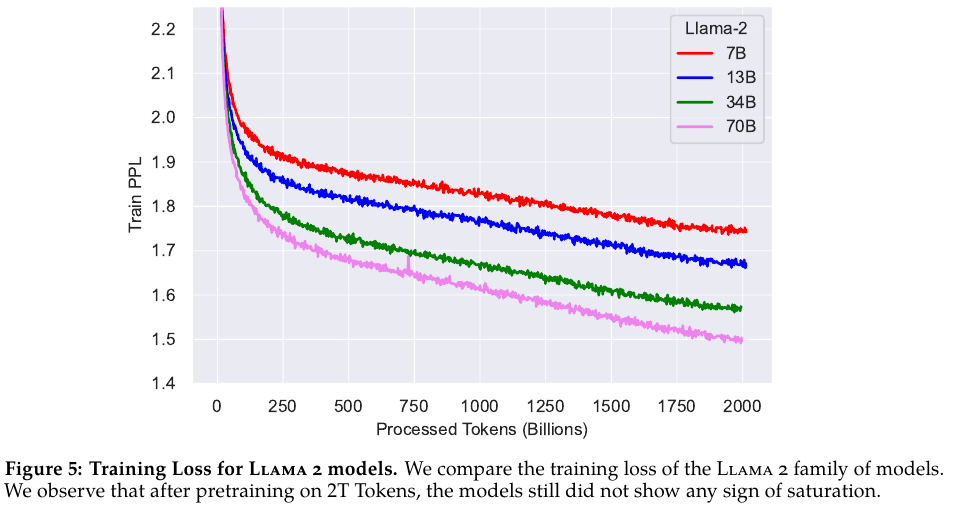
Figure 5에서는 학습 PPL의 추이를 보여준다.


Table 3와 4에서는 pretrained Llama 2의 성능을 보여준다.
상식 추론, MMLU, BBH, AGI Eval, Math 등 다양한 지표를 사용해서 평가했다.
MMLU, TriviaQA, Natural Questions에 대해서는 괜찮은 성능을 보여주지만 GPT-4나 PaLM-2-L에 비하면 다른 지표들에 대해서는 다소 부족하다.
하지만 GPT-3.5나 PaLM과는 견줄만하다.
3. Fine-tuning
Supervised fine-tuning, iterative reward modeling, RLHF, Ghost Attention (GAtt)을 사용해서 수행한다.
GAtt은 멀티 턴 대화의 흐름을 제어하기 위해서 도입했다.
3.1. Supervised Fine-Tuning (SFT)

Getting Started
SFT를 공개적으로 사용 가능한 instruction tuning data로 시작한다.
Quality Is All You Need
벤더 업체를 통해서 고품질의 annotations에 집중했다.
많은 수의 데이터 보다는 품질에 집중해서 27,540 annotations까지만 수집했다.
Fine-Tuning Details
For supervised fine-tuning, we use a cosine learning rate schedule with an initial learning rate of 2 × 10 −5 , a weight decay of 0.1, a batch size of 64, and a sequence length of 4096 tokens.
3.2. Reinforcement Learning with Human Feedback (RLHF)
3.2.1 Human Preference Data Collection
- Annotators에게 프롬프트 작성 요청
- 모델의 답변들 중에서 두 개를 샘플 후 평가 기준을 준 다음 선택 요청
- Diversity 다양성을 극대화하기 위해, 주어진 프롬프트에 대한 두개의 답변은 두 개의 서로 다른 모델 variants 변형에서 샘플링되고, temperature hyper-parameter 온도 하이퍼파라미터 역시 변화시킴.
- 참가자들에게 무조건 선택하게 하는 것 외에도, Annotators에게 선택한 응답을 다른 응답보다 선호하는 정도를 표시하도록 요청. 선택은 significantly better, better, slightly better, or negligibly better/ unsure 중 하나.
Preference annotations 수집에서 helpfulness와 safety에 집중했다.
Helpfulness는 답변이 유저의 요청에 얼마나 충실한 정보를 충족하는지를 평가한다.
Safety는 폭탄 만드는 법을 알려줘 같은 요청에 대한 적절한 답변을 하는지를 평가한다.
Safety 단계에서 safety label을 추가로 수집한다.
모델의 답변을 세 가지 범주로 분류한다.
1) the preferred response is safe and the other response is not
2) both responses are safe
3) both responses are unsafe
safety dataset 데이터의 18%, 47%, 35%가 1), 2), 3)의 범주에 속합니다.
선택된 답변이 안전하지 않고 선택되지 않은 답변이 안전한 경우의 사례는 포함하지 않는다.
이는 안전한 반응이 인간에게도 더 좋거나 선호될 것이라고 생각하기 때문이다.
Human anotations는 배치 단위로 1주일 단위로 수집했다.
기존의 공개 데이터와 비교할 때 메타가 수집한 데이터가 평균적으로 대화의 턴이 더 많고 길다고 한다.
3.2.2 Reward Modeling
Reward model 보상 모델은 모델의 답변과 그에 상응하는 프롬프트(이전 턴의 맥락 포함)를 입력으로 받고, 모델 생성의 품질(e.g., helpfulness와 safety)을 나타내는 스칼라 점수를 출력한다. 이러한 응답 점수를 보상으로 활용하여, RLHF 동안 Llama 2-Chat을 최적화하여 human preference aligment 인간의 선호도 정렬을 개선하고 helpfulness와 safety를 향상시킬 수 있다.
Helpfulness와 safety 서로 상충되는 현상을 발견되었기에 단일 보상 모델이 두 가지 모두에서 좋은 성능을 발휘하기 어려울 수 있다고 봤다. 이를 해결하기 위해 helpfulness와 safety에 대해서 각각 별개의 보상 모델을 학습합니다. 하나는 helpfulness에 최적화된 모델(helpfulness RM)이고, 다른 하나는 safety에 최적화된 모델(safety RM)입니다.
Training Objectives
prompt $x$, completion $y$, reward score $r_{\theta}(x, y)$, preferred response $y_c$, rejected counterpart $y_r$.
$L_{ranking} = - log ( \sigma( r_{\theta} (x, y_c ) - r_{\theta} (x, y_r ) )$
위 loss는 binary ranking loss다.
reward score를 더 크게 반영하기 위해서 margin $m(r)$을 추가한다. 이는 preference rating의 이산화 함수다.
$L_{ranking} = - log ( \sigma( r_{\theta} (x, y_c ) -r_{\theta} (x, y_r ) - m(r) )$

Training Details.
베이스 모델을 학습할 때와 동일한 optimizer parameters를 사용했다.
The maximum learning rate is 5 × 10 −6 for the 70B parameter Llama 2-Chat and 1 × 10 −5 for the rest.
The learning rate is decreased on a cosine learning rate schedule, down to 10% of the maximum learning rate.
We use a warmup of 3% of the total number of steps, with a minimum of 5. The effective batch size is kept fixed at 512 pairs, or 1024 rows per batch.


Table 7과 8은 reward model의 결과다.
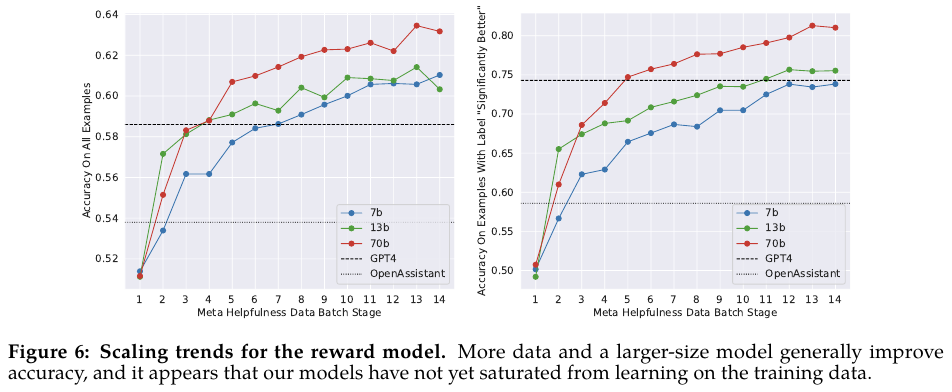
Figure 6에서는 모델의 크기를 키우면서 어떻게 helpfulness의 성능이 변하는지를 보여준다.
3.2.3 Iterative Fine-Tuning
연속적인 버젼의 RLHF 모델을 만들고 이를 갱신해 나간다. RLHF-V1, ..., RLHF-V5
Proximal Policy Optimization (PPO)와 Rejection Sampling fine-tuning을 사용해서 수행한다.
PPO는 InstructGPT (링크)를 리뷰하면서 살펴보았으므로 생략한다.
PPO의 핵심은 두 개의 policy의 차이 정보를 활용하는데 KLD를 사용한다는 데 있다.
Rejection Sampling fine-tuning
다음의 절차를 따른다.
- K개의 출력을 모델로 부터 생성한다.
- 보상 모델로 가장 좋은 답변을 뽑는다.
- 이렇게 가장 좋은 답변들에 대해서만 SFT를 적용한다.
For all models, we use the AdamW optimizer (Loshchilov and Hutter, 2017), with β 1 = 0.9, β 2 = 0.95, eps = 10 −5 . We use a weight decay of 0.1, gradient clipping of 1.0, and a constant learning rate of $10^{−6}$ . For each PPO iteration we use a batch size of 512, a PPO clip threshold of 0.2, a mini-batch size of 64, and take one gradient step per mini-batch. For the 7B and 13B models, we set β = 0.01 (KL penalty), and for the 34B and 70B models, we set β = 0.005.
3.3. System Message for Multi-Turn Consistency
아래 Figure 9처럼 멀티턴 대화를 진행하다 보면 처음 받았던 지시를 잊어버리는 현상이 있다.
이를 해결하기 위해서 Ghost Attention을 도입한다.
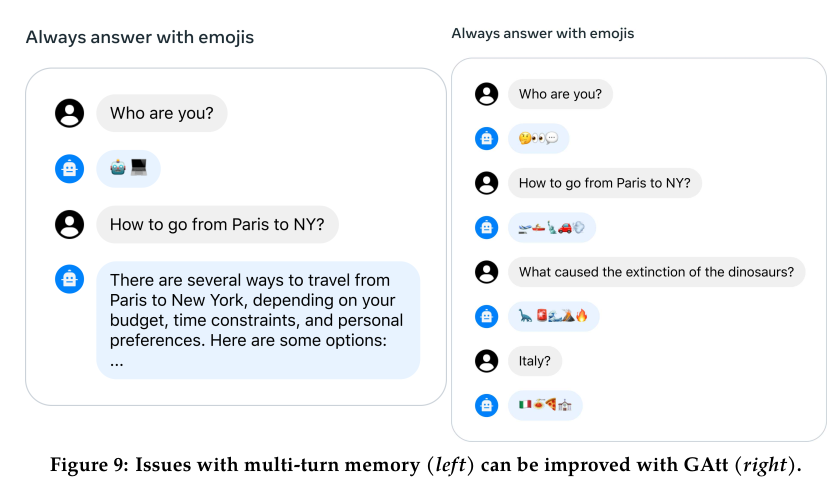
Ghost Attention (GAtt)
Ghost attention은 Context Distillation에서 영감을 얻은 방법이다.
$i$번째 턴의 대화에서의 유저의 메시지가 $u_i$, LLM의 메시지가 $a_i$ 일 때, 중간중간 instruciton을 삽입한다.
$\left[ u_1, a_1, u_2, a_2, ..., u_n, a_n \right]$ 을
$\left[ u_1 + inst, a_1, u_2 + inst, a_2, ..., u_n + inst, a_n \right]$ 의 형태로 붙여넣는 것 같다.

Iterative RL이 효과가 있음을 Figure 11에서 보여준다.
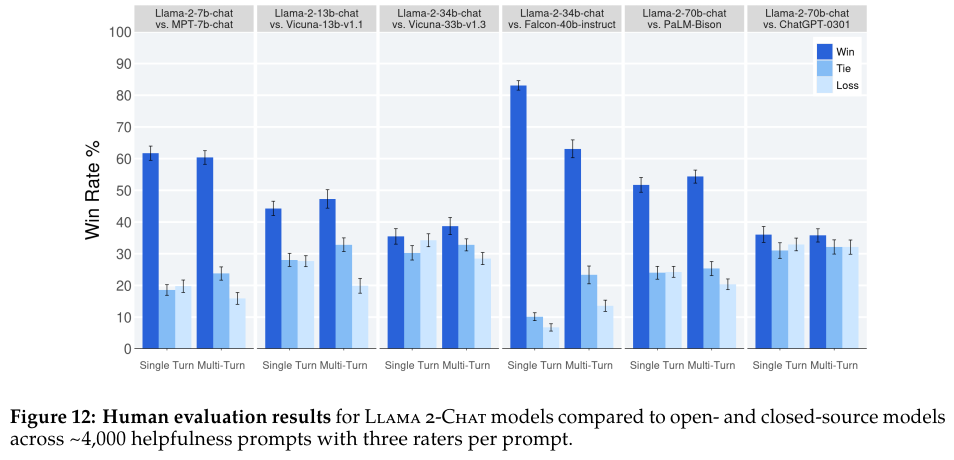
Figure 12에서는 Llama 2-Chat의 helpfulness의 지표 평가를 보여준다
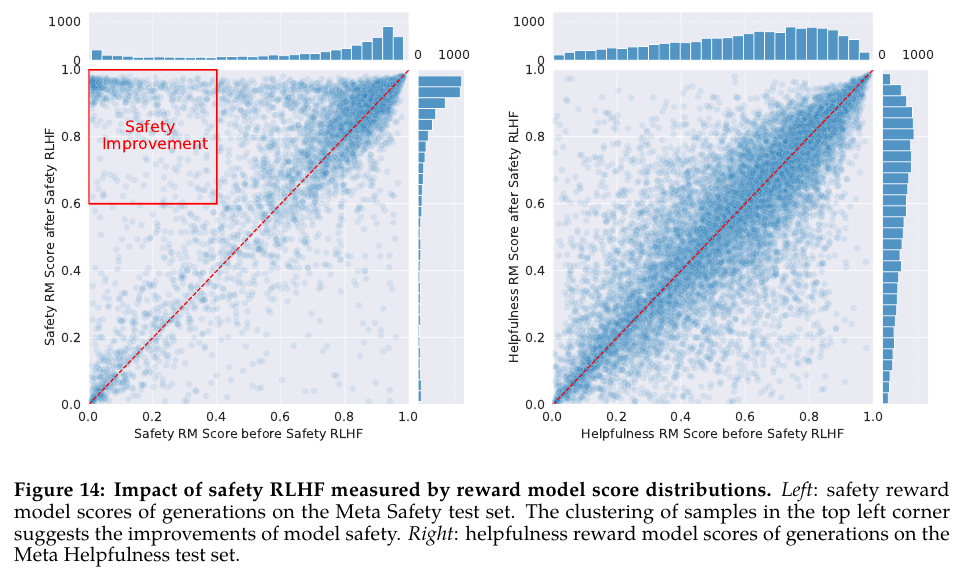

safety RLHF를 적용한 결과를 Figure 14와 Table 12를 보여준다.
Toxicity에 대한 내용을 다룬 Figure나 Table도 있는데 너무 양이 방대하게 많아서 직접 논문을 보는걸 추천한다.
References:
https://github.com/ggml-org/llama.cpp/discussions/2541
https://medium.com/%40shahip2016/llama-2-explained-in-simple-step-by-step-process-5076e072cb69
https://devocean.sk.com/blog/techBoardDetail.do?ID=165192
https://verticalserve.medium.com/group-query-attention-58283b337c65