YOLO v4 (2020) 논문 리뷰
YOLO v4의 논문 이름은 YOLOv4: Optimal Speed and Accuracy of Object Detection다. (링크)
저자는 Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao다.
YOLO의 경우 v4 부터는 처음 접하는 논문이다.
SK devcon의 글 (링크)를 보니 기존의 저자가 아닌 새로운 저자들이 YOLO라는 이름을 썼지만 잘 이야기가 되어서 써도 되는 모양이다.
YOLO가 지금 v11까지 나왔는데 아직 v4니까 모든 YOLO 시리즈 리뷰의 갈 길이 멀다.
Abstract
CNN에는 정확도를 향상시키기 위한 features의 조합들에 대한 실질적인 테스트를 수행해야 한다. 어떤 features를 일부 모델, 혹은 일부 문제에 대해서만 작동하거나 일부 작은 규모의 데이터에 대해서만 적용된다. 하지만 Batch normalzation이나 residual connections은 대부분의 모델, 태스크, 데이터셋에서 작동한다. 저자들은 이러한 universal features가 Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Sefl-adversarial-training (SAT), 그리고 Mish-activation을 포함한다고 본다. 추가적으로 Mosaic data augmentation, DropBlock regularization, CIoU loss를 혼합해서 MS COCO 데이터에 대해서 SOTA를 달성했으로 Tesla V100에 대해서 real time speed로 ~65 FPS를 달성했다.
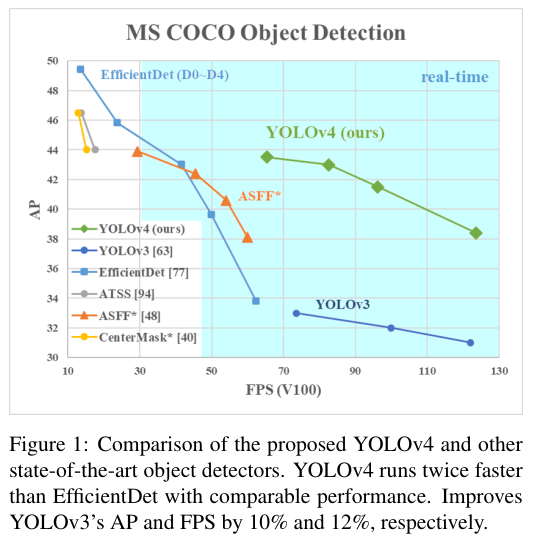
위 Figure 1는 YOLOv4와 다른 방법들의 AP와 FPS의 비교표다.
2. Related Work
2.1. Object detection models
보통의 object detector는 다음의 부분들로 구성된다.
- Input: Image, Patches, Image Pyramid
- Backbones: VGG16, ResNet-50, SpineNet, EfficientNet-B0/B7, CSPResNeXt50, CSPDarknet53
- Neck:
Additional blocks: SPP, ASPP, RFB, SAM
Path-aggregation blocks: FPN, PAN, NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM - Heads:
Dense Prediction (one-stage):
RPN, SSD, YOLO, RetinaNet - Anchor based
CornerNet, CenterNet, MatrixNet, FCOS - Anchor free
Sparse Prediction (two-stage):
Faster R-CNN, R-FCN, Mask R-CNN - Anchor based
RepPoints - Anchor free
위 내용을 그림으로 표기하면 아래 Figure 2와 같다.
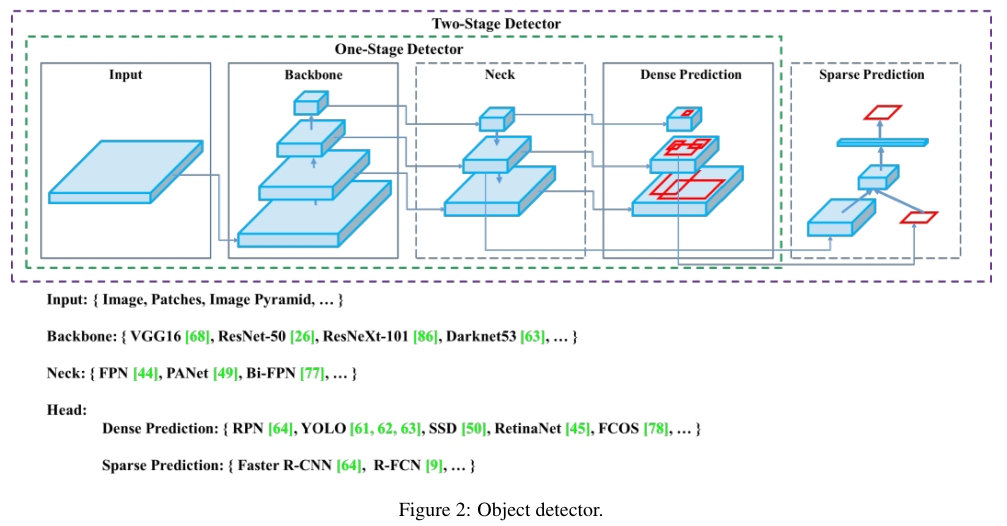
Anchor free 방법들인 CornetNet이나 RepPoints는 초록도 본 적이 없어서 나중에 한 번 알아봐야겠다.
Anchor free면 bounding box가 없이 예측한다는건데 어떤 방법인지 궁금하다.
2.2. Bag of freebies (BoF)
전통적인 obejct detector는 offline 방식으로 학스뵈기 때문에 inference cost를 늘리지 않으면서 모델을 향상시키는 방법을 고안한다. 학습 전략을 변경하거나 학습 비용만을 증가시키는 방법을 "bag of freebies"라고 부른다.
여기에는 입력 데이터의 variability 변동성을 늘리는 data augmentation 데이터 증강, 데이터의 bias 편향을 다루는 semantic distribution, 그리고 Bounding Box (BBox) regression의 objective function 목적 함수가 있다.
Data Augmenation
Photometric distortion
brightness, conrast, hue, satiration, noise
Geometric distortion
random scaling, cropping, flipping, and rotating
Simulating object occulation
random erase, CutOut, hide-and-seek, grid mask,
DropOut, DropConnect, DropBlock
Mulltiple Images
MixUp, CutMix
Style transfer GAN
Semantic Distribution
데이터 셋에서의 분포의 편항이란 곧 서로 다른 클래스 사이에서의 data imbalance다.
Two-stage:
Hard negative exampling mining, Online hard example mining 사용.
이 방법은 one-stage에는 불가능.
One-stage:
Focal loss 도입
Bounding Box (BBox) regression의 objective function
보통 MSE (Mean Square Error)를 목적 함수로 사용한다.
이때 BBox의 좌표를 예측하는데 두 가지 경우가 있다.
1. Center point 좌표와 길이와 너비를 예측한다. { $ x_{center}, y_{center}, w, h $ }.
2. Upper left point와 lower right point 예측. { $ x_{top\_left}, y_{top\_left}, x_{bottom\_right}, y_{bottom\_right} $ }.
이때 anchor-based 방법에서는 corresponding offset 상응하는 오프셋을 예측한다.
{ $ x_{center\_offset}, y_{center\_offset}, w_{offset}, h_{offset} $ }과 { $ x_{top\_left\_offset}, y_{top\_left\_offset}, x_{bottom\_right\_offset}, y_{bottom\_right\_offset} $ }다.
하지만 이는 Bbox의 각각의 포인트를 서로 독립된 변수로 취급하는데 객체 자체를 하나의 통합된 형태로 고려하지 못한다. 이 이슈를 해결하기 위해서 어떤 연구자들이 IoU loss를 고안하여 Bbox의 area와 ground truth Bbox의 area의 coverage 범위를 고려하도록 만든다. GIoU loss라는 진보된 방법도 등장하여 객체의 coverage area뿐만 아니라 shape와 orientation도 고려하는 방법이 제시되었다. DIoU loss에서는 추가적으로 객체의 중심부터에서의 거리를 고려하며, CIoU loss는 overlapping area를 고려함과 동시에 center points 간의 거리를 동시에 고려한다. CIoU가 더 빠른 수렴 속도와 Bbox regression 문제에서의 더 좋은 정확성을 달성하였다.
2.3. Bag of specials (BoS)
Plugin modules이나 post-processing을 도입하여 약간의 추론 비용을 증가시킴으로써 의미 있는 성능의 증가를 향상시키는 방법을 "bag of specials"라고 부른다.
Receptive field를 향상시키기 위한 공통적인 모듈은 다음과 같다. SSP, ASPP, RFB다.
Attention 모듈은 object detection에서 channel-wise attention과 point-wise attention의 두 가지 측면에서 주로 많이 쓰인다.
이러한 대표적인 예시는 Squeeze-and-Excitation (SE)와 Spatial attention Module (SAM)이다.
Feature integration의 측면에서는 skip connection 혹은 hyper-column을 사용하는데 FPN 보다 경량화된 모듈을 사용한다. 이에 해당하는 모듈들이 SFAM, ASFF, BiFPN이다.
Activation function들도 많이 연구되었다. ReLU 이후 LReLU, PReLU, ReLU6, caled Exponential Linear Unit (SELU), Swish, hard-Swish, Mish 등이 연구되었다.
Post-processing의 경우 딥러닝 베이스로는 NMS가 많이 쓰인다. Greedy NMS, soft NMS, DIoU NMS가 있다.
BoF와 BoS의 내용을 자세하게 번역하거나 추가해서 적기 보다는 궁금한 개별 논문을 리뷰하는게 나을 것 같아서 지금은 간단하게만 짚고 넘어간다.
3. Methodology
GPU에 대해서는 (1 - 8)의 작은 conv layers의 그룹을 사용한다.
CSPResNeXt50과 CSPDarknet53이다.
VPU에 대해서는 grouped-convolution을 사용하는데 Squeeze-and-excitement (SE) 블락을 사용한다.
EfficientNet-lite / MixNet / GhostNet / MobileNetV3가 이에 해당한다.
3.1. Selection of architecture
CSPResNeXt50은 ILSVRC2012 (ImageNet) object detection에 대해서 CSPDarknet53보다 성능이 좋지만,
반대로 CSPDarknet53은 MS COCO의 object detection에 대해서 CSPResNeXt50 보다 좋은 성능을 지닌다.
다음으로는 리셉티브 필드를 증가시킬 추가 블록을 골라야 한다. FPN, PAN, ASFF, BiFPN 등이 있다.
Classifier와 다르게 detector는 다음의 요구사항을 만족해야 한다.
- Higher input network size (resolution)은 여러개의 작은 크기의 객체 탐지를 위해 필요하다.
- More layers - 더 큰 크기의 입력 네트워크를 보장 하기위해서 higher receptive fields가 필요하다.
- More parameters - 모델의 greater capacity; 단일 이미지에서의 다양한 크기의 객체를 탐지하기 위해서 필요하다.

Table 1에서 비교한 바와 같이 여러가지 모델들이 있는데 CSPResNeXt50는 레이어의 개수가 16, CSPDarknet53은 레이어의 개수가 29다. CSPDarknet53이 파라미터의 수, 리셉티브 필드, 레이어의 수가 더 많이 때문에 이를 채택했다.
CSPDarknet53에 SPP 블락을 더했으며 PANet을 파라미터 aggregation으로 사용했다. Cross-GPU Batch Normalization (CGBN or SyncBN)을 사용하지 않았다.
3.2. Selection of BoF and BoS
• Activations: ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
• Bounding box regression loss: MSE, IoU, GIoU, CIoU, DIoU
• Data augmentation: CutOut, MixUp, CutMix
• Regularization method: DropOut, DropPath, Spatial DropOut, or DropBlock
• Normalization of the network activations by their mean and variance: Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), or Cross-Iteration Batch Normalization (CBN)
• Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
3.3. Additional improvements
- Self-Adversarial Training (SAT)
- Genetic 알고리즘을 통한 하이퍼 파라미터 선택
- Modified SAM, modified PAN, Cross mini-Batch Normalization (CmBN)

CmBN은 CBN의 수정된 버젼으로 Figure 4에서와 같이 statistics를 mini-batches 사이의 single batch에서만 모은다.

SAM을 spatial-wise attention에서 point-wise attention으로 수정하고, PAN의 shortcut connection을 concatenation으로 교체했다. 위 Figure 5와 6에 그림으로 표기되어 있다.
최종적인 YOLOv4의 아키텍처는 아래와 같다.
3.4. YOLOv4
• Backbone: CSPDarknet53
• Neck: SPP , PAN
• Head: YOLOv3
• Bag of Freebies (BoF) for backbone:
CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
• Bag of Specials (BoS) for backbone:
Mish activation, Cross-stage partial connections (CSP), Multiinput weighted residual connections (MiWRC)
• Bag of Freebies (BoF) for detector:
CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler , Optimal hyperparameters, Random training shapes
• Bag of Specials (BoS) for detector:
Mish activation, SPP-block, SAM
4. Experiments
Ablation Study
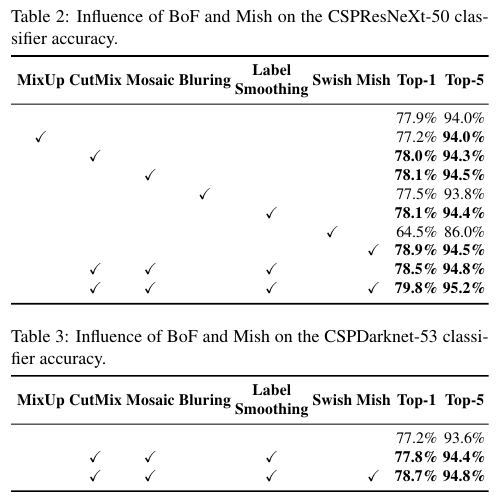


BoF와 BoS가 모델에 미치는 영향을 실험한 결과가 Table 2, 3, 4, 5에 나와있다.

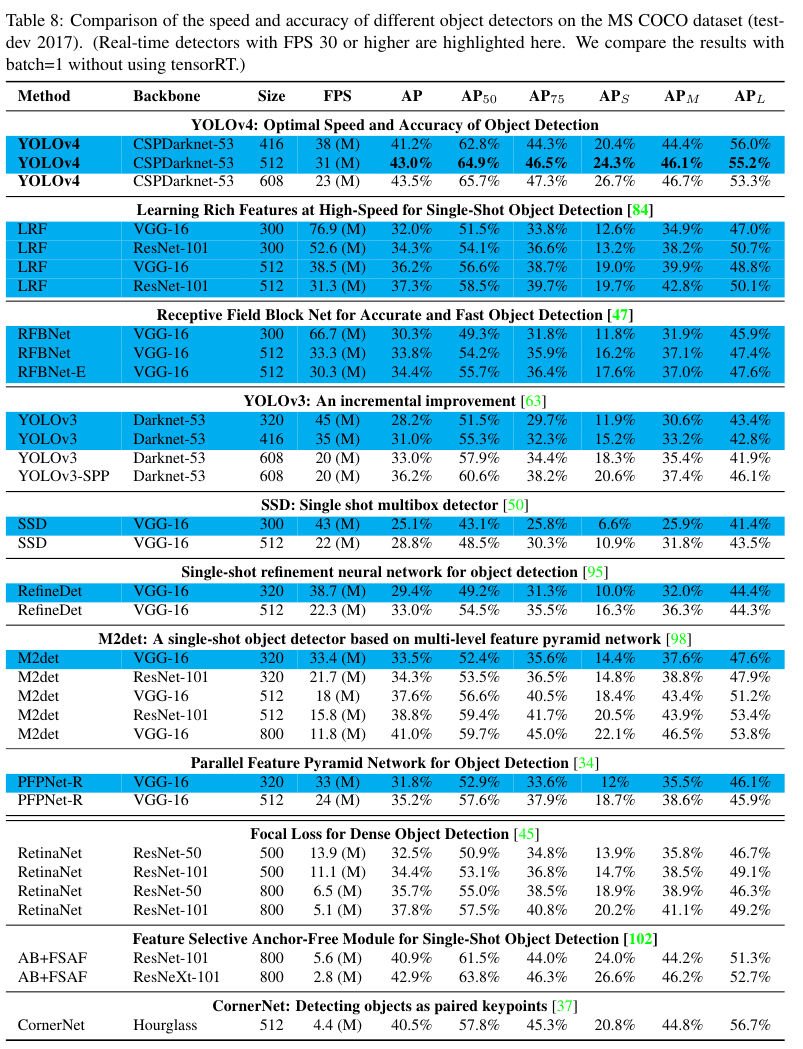


Figure 8, Table 8, 9, 10은 모두 MS COCO에 대한 object detection 결과를 보여준다.
여담
BoS와 BoF의 분량을 보면 거의 서베이 논문에 버금가는 분량이라 레퍼런스 논문들을 찾기 좋지 않나 싶다.
추가적으로 철저한 ablation study가 인상적이다.
NMS 참고자료: 링크
References:
https://devocean.sk.com/blog/techBoardDetail.do?ID=166976&boardType=techBlog
https://herbwood.tistory.com/24