MobileNet V2 (2018) 논문 리뷰
MobileNet V2의 논문 이름은 MobileNetV2: Inverted Residuals and Linear Bottlenecks다. (링크)
저자는 Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen다.
MobileNet의 두 번째 버젼으로 object detection에 적용해서 SSDLite라는 새로운 프레임워크를 소개한 논문이다.
torchvision의 사전 학습 모델 중에서 SSDLite가 있는데 여기서 만나게 되었다.
또한 semantic segmentation 문제를 풀기 위해서 DeepLabv3 모델에 적용한 MobileDeepLabv3를 소개한다
Abstract
새로운 Mobile net 네트워크 구조를 탐구한 논문이다. Object deteciton에 대해 적용해서 SSDLite라는 새로운 프레임워크를 제시했으며, semantic segmentation 문제를 풀기 위해서 DeepLabv3 모델에 적용한 MobileDeepLabv3 또한 소개한다.
Inverted residual 구조를 새로 도움히여 thin bottleneck layers 사이를 연결한다. Intermediate expansion layer는 가벼운 depthwise convlution을 사용하며 피쳐를 filter하여 비선형성의 근원으로 사용한다. 추가적으로 representational power를 유지하기 위해서 중요한 사실은 narraw layers 내에서의 비선형성을 제거임을 발견했다.
ImageNet classification, COCO object detection, VOC image segmentation에 대해서 multiply-adds (MAdd)로 명명된 연산량과 accurcy 사이의 트레이드오프, 그리고 actual latency와 파라미터 수를 특정하였다.
3. Preliminaries, discussion and intuition
3.1. Depthwise Separable Convolutions
Depthwise separable convolution은 Xception 논문 리뷰 (링크)에서 다뤘으니 자세한 내용은 생략한다.
요약하자면 depthwise conv를 함께 사용하면 연산량을 급격하게 줄일 수 있다.
아래 그림 Figure 2의 (b)를 보면 알겠지만 depthwise separable conv는 channel-wise로 컨볼루션을 수행하는 컨볼루션이다.

3.2. Linear Bottlenecks
Activation tensor of dimenstion $h_i \times w_i \times d_i$ in $i$ 번째 레이어 $L_i$, 그리고 레이어는 총 $n$개가 있다.
실제 이미지에 대해서 layer activations 의 집합을 manifold of interes라고 부른다.
이 매니폴드를 저차원에 임베딩 시킬 수 있다고 assumed 가정되어 왔다.
Manifold라는 개념 자체는 수학과에서 rigorous하게 정의하는걸로 알아보려면 그 깊이가 한도 끝도 없다.
본인도 완전하게 (수학과 학부 이상 수준)으로 이해하는게 아니라서 대략적으로 아는 바를 적어보자면 geometric topological 기하학적 위상학적 개념과 mapping의 개념이 필요한데 한 manifold 위의 어떤 점 p를 포함하는 open set을 euclidean space (혹은 euclidean coordinates)로 mapping이 가능하다는 뜻이다.
이 mapping function을 chart라고 부른다. 좌표간의 변환은 선형대수와 미분적분학에서의 coordinate transformations를 생각하면 이해가 쉬우리라 생각한다.

dim-n이 낮을 수록 matrix T로 인해서 transform한 다음 다시 projected back을 하면 manifold가 collapse하는데, n가 15, 30처럼 커지면 그런 현상이 발생하지 않지만 highly non-convex다.
Layer transformation 레이어 변환 ReLU($Bx$)의 결과가 0이 아닌 부피 S를 가지면, 내부 S로 매핑된 점들은 입력의 linear transformation 선형 변환 $B$를 통해 얻어진다. 따라서 전체 차원 출력에 해당하는 입력 공간의 부분이 선형 변환으로 제한된다는 것을 쉽게 알 수 있다.
요약하자면, 저자들은 manifold of interest가 더 높은 차원의 활성화 공간의 저차원 subspace 부분공간에 놓여야 함을 나타내는 두 가지 속성을 강조한다.
1. Manifold of interest가 ReLU 변환 후에도 0이 아닌 volumn 부피를 유지하면 이는 선형 변환에 해당한다.
2. ReLU는 manifold of interest가가 입력 공간의 저차원 부분 공간에 놓여 있는 경우에만 입manifold of interest에 대한 완전한 정보를 보존할 수 있다.
이러한 두 가지 통찰력은 기존 신경망 구조를 최적화하기 위한 경험적 힌트를 제공한다. Manifold of interest가 저차원이라고 가정하면 컨볼루션 블록에 선형 병목 계층을 삽입하여 이를 포착할 수 있다. 섹션 6에서 설명될 실험적 증거에 따르면 선형 계층을 사용하는 것이 비선형성이 너무 많은 정보를 파괴하는 것을 방지하므로 중요하다.
3.3. Inverted residuals

Figure 3을 보면 알 수 있듯이 기존의 residual block와 inverted residual block의 차이점은 채널의 수 조절에 있다.
일반 residual은 채널의 수를 줄였다가 다시 확장하지만, inverted residual은 채널의 수를 늘렸다가 다시 축소한다.
4. Model Architecture

구체적인 블록의 구조는 Table 1에 나와있다.
MobileNetV2의 시작 레이어는 fully conv layer with 32 filters다.
뒤로는 Table 2에 나온 19 residual bottleneck layers가 온다.
ReLU6를 non-linearity function으로 사용한다.
항상 3 x 3 kernel을 사용하며 dropout과 batch normalization을 학습에서 사용한다.
추가적으로 expansion factor를 6으로 설정한다.
예를 들어서 bottleneck layer가 64-channel의 input tensor를 입력으로 받는다면,
이를 128 channels로 변환하고 intermediate expansion layer를 64 * 6 = 384 channels를 가지게 된다.
아래는 19 residual bottlenectk layers를 설명한 Table 2다.

아래 Table 3에서는 channel의 수와 필요 메모리양을 나타냈다.

아래 Figure 4에서는 ShuffleNe, NasNet, MobileNet V1과 V2의 아키텍쳐 구조를 비교한다.

6. Experiments
6.1. ImageNet Classificaiton
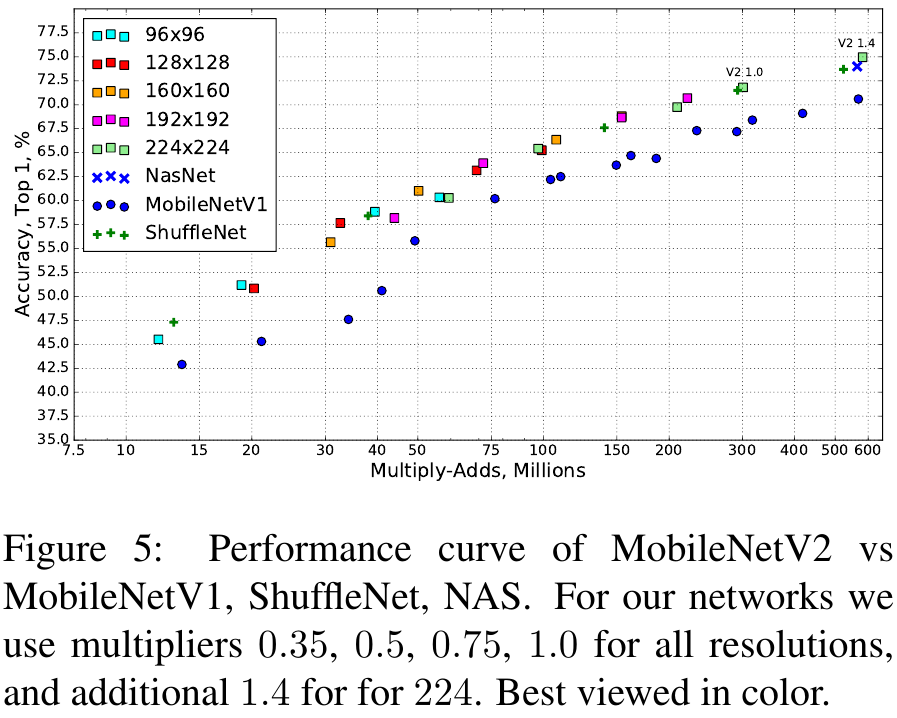

Figure 5와 Table 4를 보면 다른 경량화 모델들과 비교해서 파라미터 수가 적으면서 Top 1 정확도도 comparable하며 속도도 빠른걸 확인할 수 있다.
6.2. Object Detection

MNet V1과 V2를 적용한 SSDLite가 기존 SSD나 YOLOv2보다 훨씬 적은 파라미터 수로 견줄만한 성능을 달성했음을 보여준다.
YOLOv2에 비하면 20배 효율적이다.
6.3. Semantic Segmentation
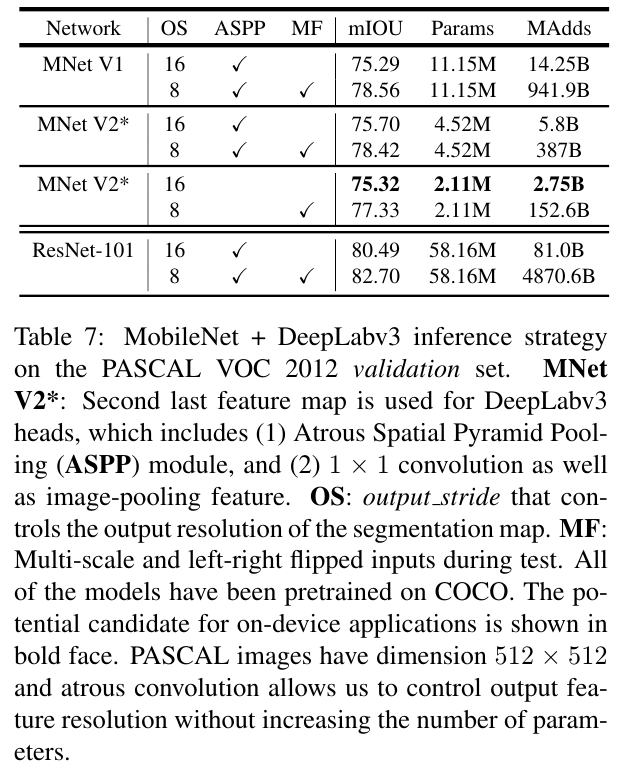
PASCAL VOC 2012 validation set에 대한 성능 평가에서 ResNet-101에 기반한 DeepLab V3보다 훨씬 적은 파라미터로 약간 더 낮은 성능을 달성했음을 보인다. 성능은 다소 떨어지지만 기존에 비해서 29배 효율적이다.
References:
Mathematics for Physicists: Introductory Concepts and Methods - Alexander Altland, and Janvon Delft