GRU 모델 설명
GRU 설명
GRU는 Gated Recurrent Units의 약자로 Recurrent Neural Network (RNN)의 하나다.
GRU가 소개된 논문 이름은 Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation이다.
저자는 Cho, Kyunghyun; van Merrienboer, Bart; Bahdanau, DZmitry; Bougares, Fethi; Schwenk, Holger; Bengio, Yoshua이다.
전체적인 내용은 LSTM과 유사하여 간략하게 설명하고 구현도 비슷하므로 생략한다.
GRU의 가장 특징은 LSTM의 Cell을 다소 단순화했다는 사실이다.
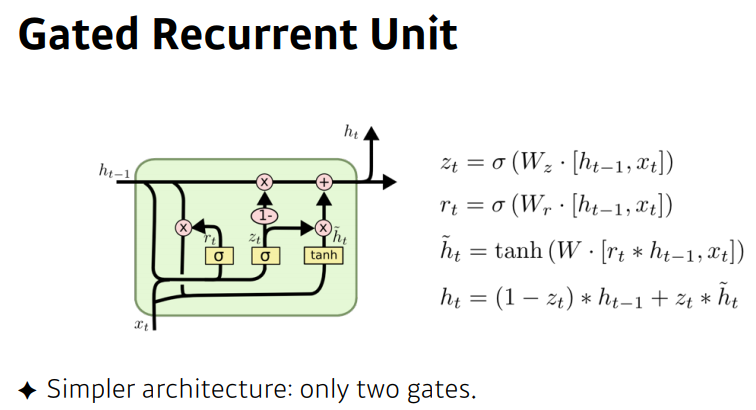
Update gate vector
$ z_t $ = $\sigma ( W_z \cdot [ h_{t-1}, x_t ]) $
Reset gate vector
$ r_t = \sigma ( W_r \cdot [ h_{t-1}, x_t ]) $
Candidate activation vector
$ \tilde{h_t} $ = $tanh ( W \cdot [ r_t \odot h_{t-1}, x_t ]) $
Output vector
$ {h}_{t} = ( 1- {z}_{t} ) \odot h_{t-1} + {z_t} \odot \tilde{h_t} $.
이때 $ \odot $은 Hadamard product = Element-wise product다.
Reset은 LSTM의 forget gate와 유사하게 이전의 정보를 잊을지 말지를 결정하고,
Update는 state $t$에 들어온 $x_t$와 $h_{t-1}$의 정보를 업데이트 하고,
Candidate에서는 다음으로 보낼 잠재적 $h_t$를 만들고,
Output에서 최종적으로 다음에 보낼, 최종적으로 업데이트된 state $t$에서의 hidden state $h_t$를 생성한다.
LSTM의 forget, input, output gate 보다 하나 줄어든 gate의 수가 GRU의 특징이다.
References:
고려대학교 XAI506: Deep Learning
https://en.wikipedia.org/wiki/Gated_recurrent_unit#cite_note-1