허깅페이스에 있는 데이터를 받아서 사용할 일이 있다.
이때 데이터가 작은 경우는 바로 모든 데이터를 다운 받으면 되지만,
일부 데이터만 다운받고 싶거나 데이터가 너무 커서 순차적으로 다운 받는 경우가 있다.
이런 경우에는 파일의 목록을 불러와서 일부만 선택하거나, 순차적으로 일부만 다운 받는 식으로 처리할 수 있다.
일반적인 다운로드 방법
한번에 전체 데이터 다운로드.
1. Pandas에 huggingface의 데이터셋을 직접 연결
from datasets import Dataset
import pandas as pd
df = pd.read_csv("https://huggingface.co/datasets/imodels/credit-card/raw/main/train.csv")
df = pd.DataFrame(df)

from datasets import Dataset
dataset = Dataset.from_pandas(df)
dataset

위 데이터 형식은 허깅페이스의 Dataset 객체다.
2. Huggingface에서 직접 다운로드
Anthropic의 HH-RLHF (링크)를 예시 데이터로 선정해서 다운로드 한다.
import datasets
data = datasets.load_dataset("Anthropic/hh-rlhf")
data
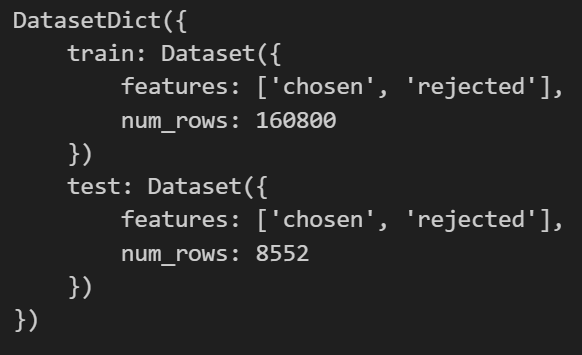
링크에 나온 데이터를 보면 아래 스크린샷에 나온것처럼 Split에 train과 test가 있다.
데이터를 불러올 때 Split를 선정해서 다운로드할 수 있다.

data = datasets.load_dataset("Anthropic/hh-rlhf", split="train")
data
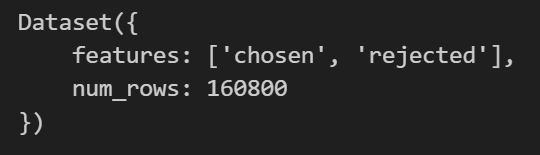
이렇게 train에 속하는 데이터만 다운받을 수 있다.
데이터의 파일 목록을 살펴보고 다운로드 하는 방법
Huggingface의 Wikimedia가 제공하는 Wikipedia 데이터 (링크)를 보면 다양한 언어를 지원함을 알 수 있다.

이렇게 다양한 데이터 중에서 원하는게 있거나, 데이터의 양이 Refined Web처럼 1.6 TB 이렇게 큰 경우에는 전체를 한 번에 다운 받으면 안되고 일부씩만 다운로드 받아야 한다.
이때 필요한게 다음의 파일 및 폴더의 목록을 받아오는 코드다.
from huggingface_hub import list_repo_files
# Hugging Face Hub에 있는 데이터셋 이름입니다.
repo_id = "wikimedia/wikipedia"
# list_repo_files 함수를 사용하여 저장소의 모든 파일과 폴더 목록을 가져옵니다.
# repo_type="dataset"을 명시하여 데이터셋 저장소임을 알려줍니다.
file_list = list_repo_files(repo_id=repo_id, repo_type="dataset")
# 가져온 파일 목록을 출력.
print(f"'{repo_id}' 데이터셋의 파일 및 폴더 목록:")
for file_path in file_list:
print(file_path)
# 파일의 개수 확인
print(f"\n총 파일 개수: {len(file_list)}")

선택한 파일을 다운로드
import os
from huggingface_hub import hf_hub_download
repo_id = "wikimedia/wikipedia"
file_to_download = file_list[1]
print(f"선택한 파일: {file_to_download}")
# 2. hf_hub_download 함수를 사용하여 파일을 다운로드합니다.
# 다운로드된 파일이 저장될 로컬 경로를 지정합니다.
# './downloaded_files' 폴더에 저장됩니다.
local_dir = "./downloaded_files"
if not os.path.exists(local_dir):
os.makedirs(local_dir)
print(f"'{local_dir}' 폴더가 없어 새로 생성합니다.")
print(f"'{file_to_download}' 파일을 다운로드하는 중...")
# downloaded_file_path는 다운로드된 파일의 로컬 경로를 반환합니다.
downloaded_file_path = hf_hub_download(
repo_id=repo_id,
filename=file_to_download,
repo_type="dataset",
cache_dir=local_dir
)
print(f"'{file_to_download}' 파일 다운로드 완료!")
print(f"파일이 저장된 경로: {downloaded_file_path}")

위와 같이 일부 데이터만 다운받을 수 있다.
원래 huggigface에서 받는 모델과 데이터는 .cache 폴더 아래의 huggingface 폴더에 저장되는데 이렇게 local_dir로 지정할 수 있다.
다만 huggingface에서 데이터나 모델이 이미 다운 받아져있는지 검사하거나 불러올 때는 .cache 폴더에서 가져오므로 이런 설정을 바꿔줘야한다.
본인은 그 과정이 번거로워서 기본 .cache 폴더를 그대로 사용하고 있다.
'AI Codes > Huggingface' 카테고리의 다른 글
| Hugging Face 개요 (0) | 2025.04.18 |
|---|---|
| Hugging Face Hub 설명 (0) | 2025.04.18 |

