CLIP 모델의 논문 제목은 Learning Transferable Visual Models From Natural Language Supervision이다. (링크)
저자는 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever다.
Abstract
Pre-training 후에 자연어 Natural Language를 이용해서 학습된 시각적인 컨셉을 인용한다. 이를 zero-shot transfer learning의 측면에서 downstream tasks에 적용한다. OCR, 비디오 내부의 action recognition, geo-localization, fine-grained object classification을 포함한다.
2. Approach
CLIP (Contrastive Language-Image Pre-traininig) 모델의 학습과 추론 방법은 아래 Figure 1에 나와있다.
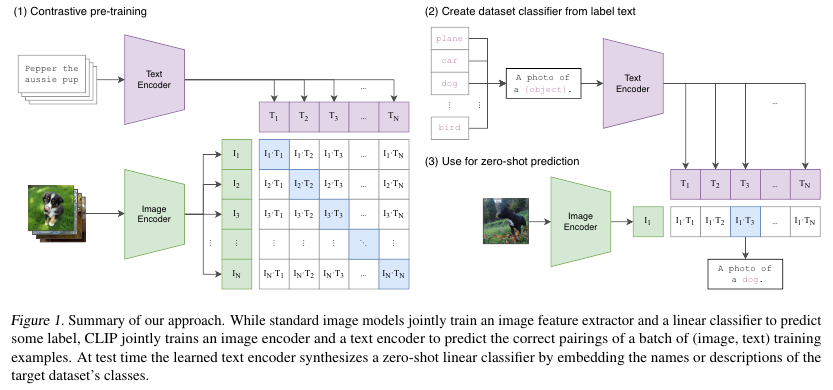
이미지와 텍스트의 embedding pairs 임베딩 쌍를 contrastive learning의 측면으로 학습한다.
Encoders
Image Encoder
Image Encoder로는 ResNet-50과 ViT 모델을 사용한다. ResNet의 경우 원본 모델이 아니라 ResNet-D 모델 (링크) 에다가 antialiased rect-2 blur pooling (링크)을 사용한다. 그리고 global average pooling을 attention pooling 메커니즘으로 변경한다. Global average-pooled representation of learning에 conditioned 된 query를 기반으로 multi-head QKV attention을 single layer로 사용했다고 한다.
Text Encoder
Text Encoder로는 다소 변형된 GPT-2 모델, 63 M 파라미터 짜리를 사용했다. 12-layer, 512-wide model, 8 heads를 사용했으며 BP를 사용했다. Vocab 사이즈는 49,152이고 maxmimum sequence length는 76으로 설정했다. 모든 시퀀스들은 [SOS]와 [EOS] 토큰들로 감싸져있다.
Contastive Learning
텍스트 인코더와 이미지 인코더를 통해서 생성된 임베딩들은 각각 N개다.
CLIP은 총 N x N 개의 쌍을 다루는데 N 쌍만 서로 관련이 있고 N x (N-1) 쌍은 서로 관련이 없다.
텍스트 임베딩과 이미지 임베딩의 코사인 유사도를 구한 다음 이를 logits로 해석해서 cross entropy를 계산한다.
Pseudocode 슈도 코드는 Figure 3에 나와있다.

Training
다양한 크기의 RestNet와 ViT 모델들에 대해서 모두 32 epochs 만큼 학습하고 Adam을 사용했다.
Weight decay는 사용하지 않았으며 하이퍼파라미터는 grid search로 탐색했다.
Learnable temperature parameter $\tau$는 맨 처음 0.07로 설정된 다음 100 이상이면 clip한다.
32,768의 굉장히 큰 크기의 배치 사이즈를 사용하였으며 mixed-precision을 사용했다.
Datasets
MS-COCO (2014)와 Visual Genome, YFCC100M을 사용했다.
3. Experiments
Inference
Prompt Engineering and Ensemling
이미지 분류를 수행할 때 다음의 prompt template 프롬프트 템플릿을 사용한다.
"A photo of a {label}."
간단한 프롬프트의 사용만으로 ImageNet에서 accuracy가 1.3% 향상되었다.
또한 여러개의 프롬프트를 여러개의 zero-shot classifiers에 적용해서 앙상블 하는 방법도 실험했다.
"A photo of a {label}, a type of pet.", "a satellite photo of a {label}." 처럼 컨텍스트를 제공하는 프롬프트와
"A photo of a big {label}"이나 "A photo of a small {label}" 같은 프롬프트를 사용했다.

Figure 4를 보면 프롬프트 엔지니어링과 앙상블을 수행한 결과가 더 좋았음을 알 수 있다.
Zero-shot Performances
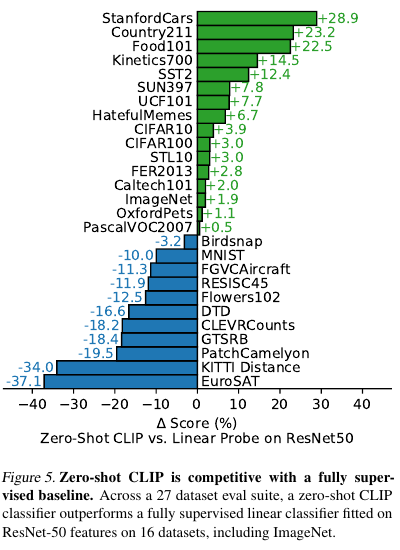
Fine-grained 이미지 분류에 있어서 CLIP은 대체로 ResNet-features에 기반한 logistic regression과 같은 기존 방법보다 좋은 성능을 보이지만 예외가 있다.
Figure 5에서 아래 부분의 파란색으로 표시된 벤치마크들이 CLIP의 성능이 안 좋게 나온 내용들이다.
저자들은 specialized, complex and abstract tasks에 대해서 약점이 있다고 한다.
Satellite image를 다룬 EuroSAT나 RESISC45나, lymph node tumor detection과 같은 의료 데이터는 PatchCamelyon, counting objects in synthetic scenes CELVRCounts, self-driving related tasks German traffic sign recognition GTSRB, recognizing distance to the nearest car KITTI Distance와 같은 데이터들이 그렇다.

Representation learing에서 CLIP은 대체로 EfficientNet에 기반한 기존 방법보다 좋은 성능을 보이지만 예외가 있다.
여기서 실험한 representation learning은 geo-localization, OCR (optical character recognition), facial emotion recognition, and action recognition이다.
Figure 11에서 아래 부분의 파란색으로 표시된 벤치마크들이 CLIP의 성능이 안 좋게 나온 내용들이다.
OxfordPets, CIFAR10, PatchCamelyon, CIFAR100, CLEVRCounts, ImageNet에 대해서는 성능이 EfficientNet 보다 못하다.
Robustness to Natural Disbribution Shift
트레이닝 데이터가 없는 생소한 데이터에 대한 실험 결과로 여기서 로버스트하다는 뜻은 보다 일반화를 잘 할 수 있는 모델이라는 뜻이다.
ImageNet-C, Stylized ImageNet, Youtube-BB, ImageNet-Vid 등의 데이터에 대해서 실험을 수행했다.
기본적으로 ImageNet에 대해서 학습한 다음 로버스트를 비교한다.
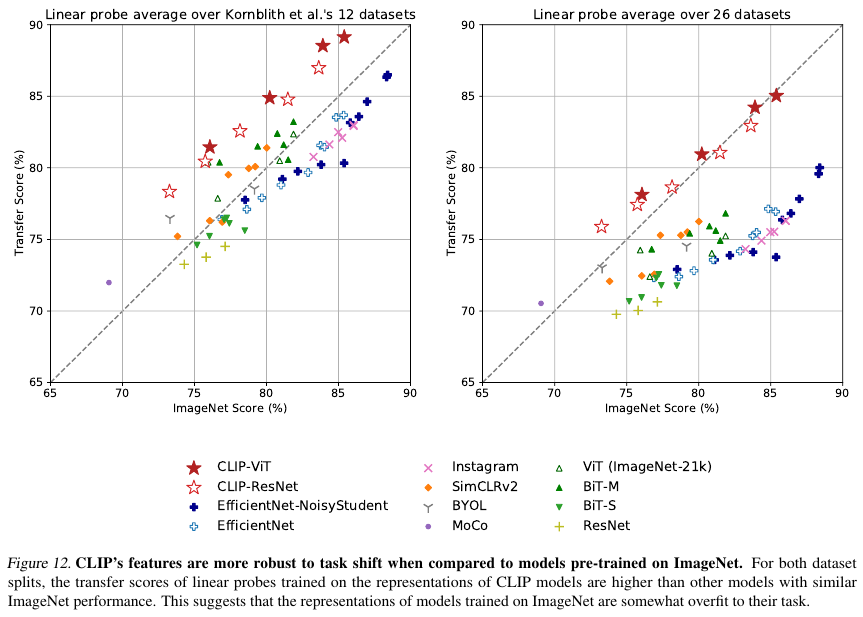
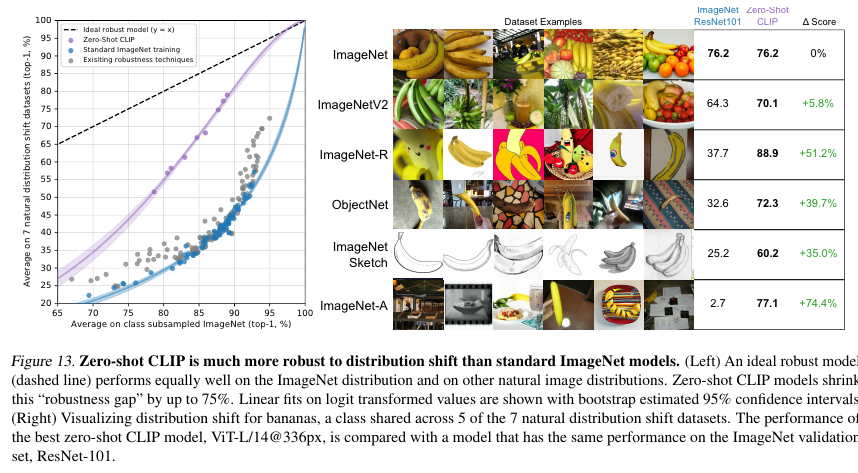
Figure 12와 13을 보면 CLIP이 보다 로버스트한 성능을 보여준다.
CLIP의 피쳐에 기반해서 ImageNet의 데이터 분포에 맞는 L2 regularized logistic regression classifier를 학습한 다음 원본 CLIP과 비교한다.

Figure 14 보면 ImageNet에 대한 성능은 향상되었지만 나머지 데이터들에 대해서는 로버스트한 성능이 하락했음을 알 수 있다.
오른쪽 상단의 Adap to ImageNet을 보면 된다.
반면에 이번에는 class shift 방식에 적응하기 위해서 저자들은 기존에 학습하지 않은 class name에 근거해서 생성한 custom zero-shot classifier를 이용해서 실험을 했다.
이 결과는 Figure 14의 오른쪽 하단의 보라색으로 표기된 Adap to class shift의 결과다.
3개의 데이터에서 성능이 향상되었고 나머지 데이터들에 대해서는 성능의 하락이 없었다.
종합적으로 보면 CLIP의 방법이 OOD에 더 강건한 방법임을 알 수 있다.
'Multimodal' 카테고리의 다른 글
| LayoutLM v1 (2019) 논문 리뷰 (0) | 2025.04.16 |
|---|---|
| Show and Tell = Neural Image Caption (NIC) (2014) 모델 간단 리뷰 (0) | 2024.04.13 |

