Xception의 논문 이름은 Xception: Deep Learning with Depthwise Separable Convolutions다. (링크)
저자는 François Chollet다.
Inception 구조를 조금 더 수정한 모델이다. 따라서 간단하게만 짚고 넘어간다.
그리고 해당 논문에서 Depthwise convolution도 중요하게 다뤄서 이를 포함한다.
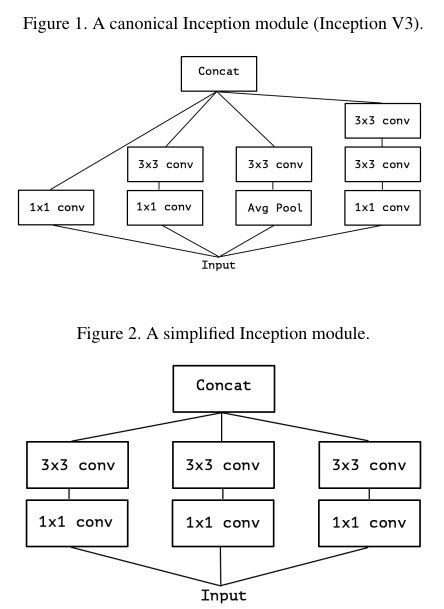
Figure 1과 2는 전통적인 Inception 모델이다.
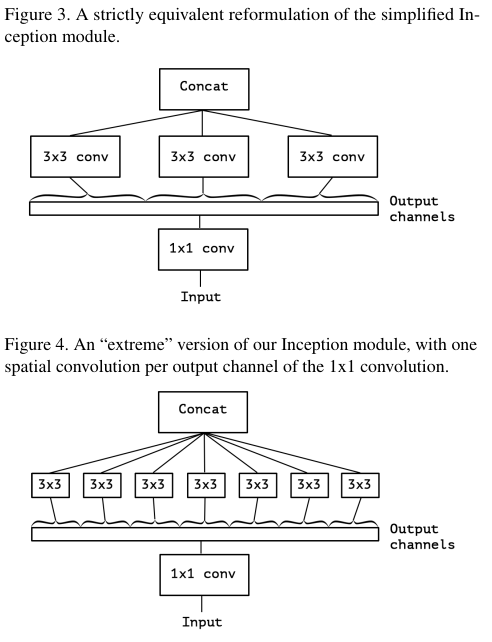
Figure 3와 4에서는 1 x 1을 극단적으로 변경한 모델이다.
이는 곧 depthwise separable convolution과 동일한 연산이다.
아래 references에서 가져온 그림을 이용해서 설명하고자 한다.

일반적인 pointwise conv는 위 그림처럼 모든 channel (depth)의 값들에 대해서 컨볼루션을 한 다음 하나의 값을 리턴한다.

반면에 depthwise conv는 개별 channel (depth)의 값들을 가지고 컨볼루션을 계산한다.
또 아래와 그림으로도 이해할 수 있다.
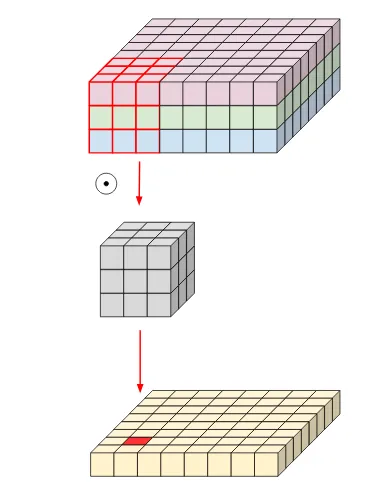
위 그림이 Normal conv다. 모든 channel (depth)의 값들에 대해서 컨볼루션을 한다.

위 그림이 depthwise conv다. 개별 channel (depth)에 대해서 컨볼루션을 계산한다.
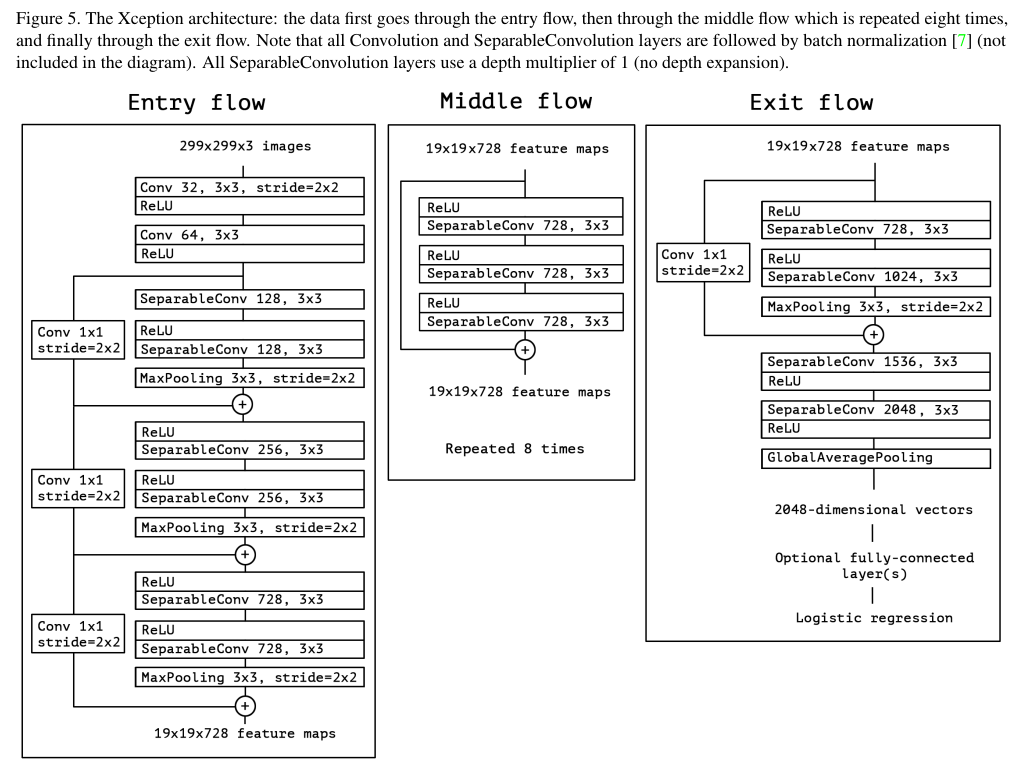
전체적인 Xception의 구조는 위 Figure 5와 같다. Residual connection 구조도 포함한다.
여기에서 말하는 separable conv는 depthwise separable conv다.
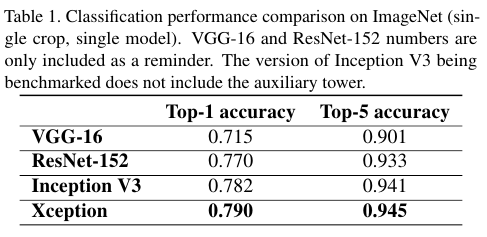
ImageNet에 대해서 Xception이 SOTA를 달성했음을 확인할 수 있다.
References:
https://coding-yoon.tistory.com/122
https://machinelearningmastery.com/using-depthwise-separable-convolutions-in-tensorflow/
'Computer Vision' 카테고리의 다른 글
| EfficientNetV2 (2021) 논문 리뷰 (0) | 2025.04.28 |
|---|---|
| MobileNet V3 (2019) 논문 리뷰 (0) | 2025.04.28 |
| Inception v4 (2016) 논문 리뷰 (0) | 2025.04.28 |
| MobileNet V2 (2018) 논문 리뷰 (0) | 2025.04.28 |
| Squeeze-and-Excitation (2018) 논문 리뷰 (0) | 2025.04.28 |



