ELECTRA 논문의 이름은 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators다. (링크)
저자들은 Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning다.
Abstract
BERT와 같은 Mask Lanauge Modeling (MLM) 사전 학습 방법은 일부 토큰을 [MASK]로 대체하여 입력을 손상시킨 후, 원래 토큰을 재구성하는 방법으로 모델을 학습한다. 다운스트림 NLP 작업에 적용하면 좋은 결과를 도출하지만, 일반적으로 효과를 발휘하려면 많은 양의 컴퓨팅 리소스가 필요하다. 대안으로, 본 연구에서는 Replaced Token Detection라는 샘플 효율성이 더 높은 사전 학습 작업을 제안한다. 입력을 마스크하는 대신 일부 토큰을 small generator network 작은 생성 네트워크에서 샘플링된 유효한 대안으로 대체하여 입력을 손상시킨다. 그런 다음, corrupted token 손상된 토큰의 원래 토큰을 예측하는 방식으로 학습하는 대신, 손상된 입력의 각 토큰이 생성된 샘플로 대체되었는지의 여부를 예측하는 판별 모델을 학습시킨다. 철저한 실험을 통해 이 새로운 사전 학습 작업이 마스크된 작은 부분집합이 아닌 모든 입력 토큰에 대해 정의되기 때문에 MLM보다 효율적임을 입증합니다. 결과적으로 동일한 모델 크기, 데이터, 그리고 연산량을 고려할 때, RTD 접근법을 통해 학습된 문맥 표현은 BERT를 통해 학습된 표현보다 상당히 우수한 성능을 보인다. 특히 작은 모델에서 이러한 성능 향상은 두드러진다. 예를 들어, 본 논문의 방법은 GLUE 자연어 이해 벤치마크에서 단일 GPU에서 4일 동안 모델을 학습시켰는데, 이 모델은 GPT (30배 더 많은 연산량을 사용하여 학습)보다 우수한 성능을 보였다. 대규모 환경에서도 잘 작동하며, RoBERTa 및 XLNet과 비슷한 성능을 보이면서도 기존 모델의 1/4 미만의 연산량을 사용하고, 동일한 양의 연산량을 사용할 때에도 기존 모델보다 우수한 성능을 보인다.
2. Method

초록에 나와있듯이 ELECTRA 모델의 아이디어는 간단하다. 작은 규모의 LM 모델을 generator G로 삼아서 MLM을 수행한다. 이 LM을 통해서 replacement token을 생성하는 generator로 이용한다. 원래의 토큰 시퀀스를 통해서 generator가 [MASK] 토큰의 자리를 몇개 생성한 다음 이를 토대로 임의의 토큰을 뽑아서 그 자리에 할당한다.
Discrimintor D, ELECTRA 모델은 이 replaced token이 원래 토큰 real, 인지 아니면 replaced token인 fake인지 판별한다.
G에 대한 loss는 일반적인 masked token의 원래 token의 예측 entropy고, D에 대한 loss는 Binary Cross Entropy다.
위 2 loss의 weighted sum이 total loss고 이를 최소화한다.
3. Experiments
ELECTRA 모델의 G와 D 모두 BERT-base를 그대로 사용한다. 그리고 BERT 자체를 사전학습하거나 하지 않고 다운스트림 파인 튜닝만을 수행한다. 다만 GLUE 데이터에 대해서는 ELECTRA의 top 부분에 simple linear classifiers와 SQuAD에 대해서는 XLNet 모듈을 덧붙였다.


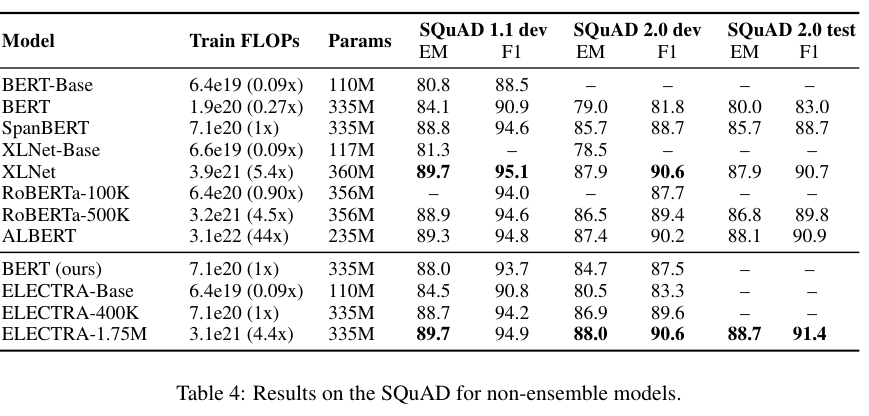
Table 1, 2, 3, 4를 보면 ELECTRA가 대체로 가장 좋은 성능임을 알 수 있다.
'NLP' 카테고리의 다른 글
| Embedding Models (0) | 2025.05.04 |
|---|---|
| Tokenizer 간단하게 정리 (0) | 2025.04.15 |
| Longformer (2020) 논문 리뷰 (0) | 2025.04.09 |
| GLU variants (2020) 논문 리뷰 (0) | 2025.04.09 |
| MQA (Multi-Query Attention) (2019) 논문 리뷰 (0) | 2025.04.09 |


