Mixtral이 제시된 논문 제목은 Mixtral of Experts다. (링크)
저자들은 Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed다.
Github: 링크
브런치 글 (링크)과 A Visual Guide to Mixture of Experts (MoE) 글 (링크)을 참조해서 Mixtral에서 사용한 Sparse Mixture of Experts를 더 잘 이해할 수 있었다.
Abstract
Mixtral 8x7B를 소개한다. 이는 Sparse Mixture of Experts (SMoE) 언어 모델이다. Mixtral은 Mistral 7B와 같은 아키텍처를 갖지만, 차이는 각각의 레이어가 8개의 feedforward blocks (i.e., experts)로 구성된다는 점이다. 각각의 레이어에서 모든 토큰들은 router network에 의해서 2개의 experts가 선택되고 현재의 state를 진행하고 그 결과들을 결합한다. 각 timestep 마다 선택되는 두 experts는 서로 다를 수 있다. 결과적으로 각각의 토큰은 47B 파라미터에 접근하지만, 오직 13B의 활성화된 파라미터를 추론 과정에서 거치게 된다. Mixtral은 32k tokens 크기의 context size로 학습되며 Llama 2 70B와 GPT-3.5 보다 좋은 성능이거나 같은 성능을 달성했다. Instruction을 따르는 fine-tuning도 수행하여, Mixtral 8x7B - Instruct로 GPT-3.5 Turbo, Claude 2.1, Gemini Pro, Llama 2 70B - chat을 Human benchmark에서 앞섰다. Base와 instruct 모델 모두 Apache 2.0 라이센스 하에서 공개되었다.
2. Architectural details
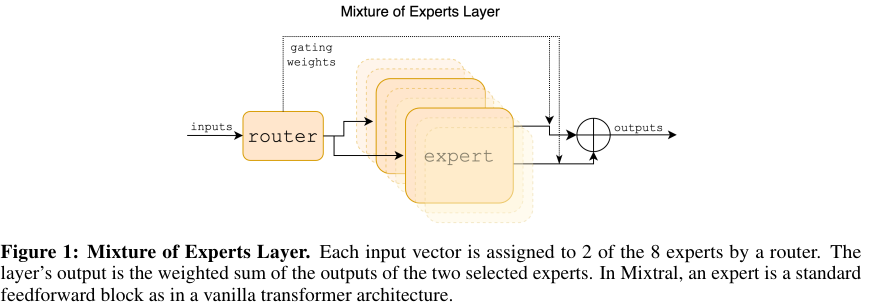
Mixtral은 transformer 아키텍처에 기초하며 Mistral 7B을 그대로 따른다. Context length는 총 32 k tokens다. Figure 1에서처럼 feedforward network와 Mixture-of-Expert layers에 의해서 대체된다. 구체적인 모델 파라미터는 Table 1에 나와있다.

2.1. Sparse Mixture of Experts
저자들은 MoE layers를 Figure 1에서 제시했으며 자세한 내용은 리뷰 논문 A Review of Sparse Expert Models in Deep Learning (링크)를 참조하길 바란다. Given input $x$에 대한 MoE 모듈의 output을 expert networks의 outputs의 weighted sum에 의해서 결정된다. 이 weights는 gating network에 의해서 주어진다. $n$ expert networks { $ E_0, ..., E_i, .., E_{n - 1} $ }에 대해서, expert layer의 출력은 다음과 같다.
$ \sum_{i=0}^{n-1} G(x)_i \cdot E_i (x) $
$G(x)_i $은 $i$ 번째 expert를 위한 gating network의 $n$-dimensional 출력이다. $E_i (x)$은 $i$ 번째 expert의 출력이다. Gating vector가 sparse기 때문에 gate의 결과가 0인 experts의 출력의 계싼을 피한다. $G(x)$는 linear layer의 Top-K logits에 softmax를 취한 값이다.
$ G(x)_i := \text{Softmax(TopK} (x \cdot W_g) ) $.
$(\text{TopK}(l))_i := l_i$인데, 만약 $l_i$가 Top-k coordinates of logits $l \in \mathbb{R}^n$이고,
그 외의 $l_i$에 대해서는 $(\text{TopK}(l))_i = - \infty$의 값을 갖는다.
MoE의 Top-2 결과에 대해서는 아래의 gating 연산을 적용한다. SwiGLU를 적용한다.
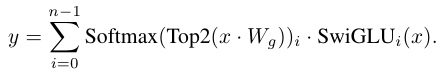
이는 GShard 아키텍처와 유사하다. GShard는 모든 블록을 대체하지만, 여기서는 MoE 레이어의 FFN sub-blocks만을 대체한다.
A Visual Guide to Mixture of Experts
A Visual Guide to Mixture of Experts (MoE) 글 (링크)에 나온 Sparse MoE 구조를 살펴본다.


위 Dense model와 다르게 Sparse MoE에서는 특정 expert 만을 이용한다.

위의 MoE Layer 그림을 보면 이해가 쉬운데, 각각의 expert에 대한 softmax 값을 구해서 Top K 만을 선택해서 활성화한다.
K = 1일때, 이 과정을 n개의 레이어를 거치면서 n번 반복하면 아래 그림처럼 나온다.
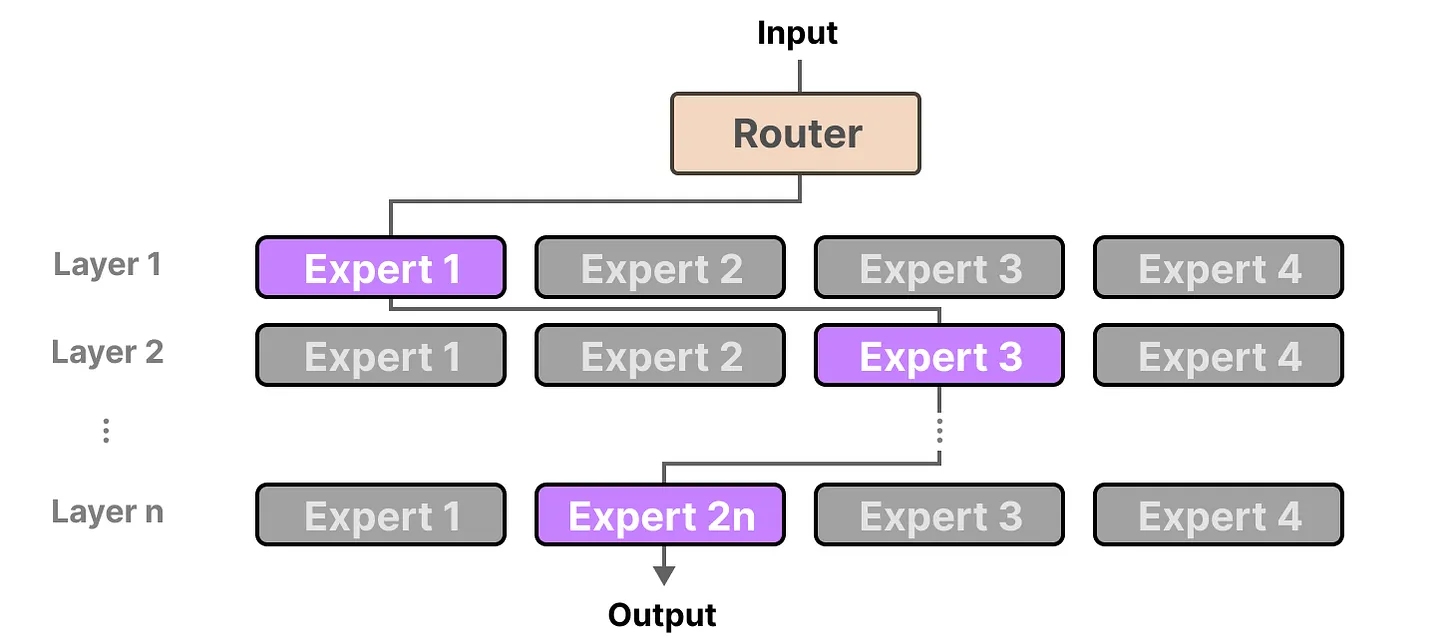
이렇게 레이어 마다 서로 다른 expert를 선택해서 최종 결과를 도출하게 된다.
3. Results
다음의 벤치마크들에 대해서 Mixtral의 성능을 평가한다.

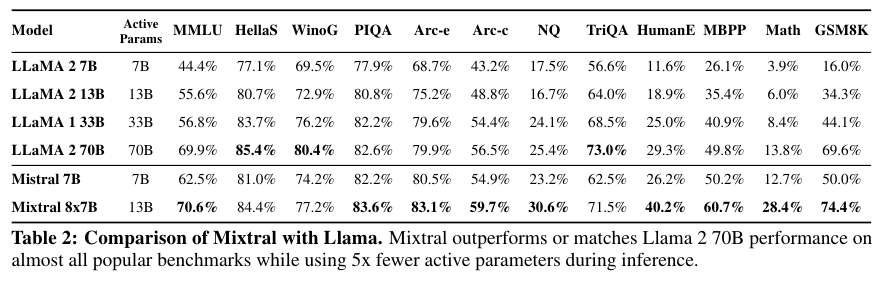
성능은 위 Table 2에 나와있다. 대체로 Mixtral 8x7B가 가장 성능을 달성했다.
References:
https://developer.nvidia.com/ko-kr/blog/applying-mixture-of-experts-in-llm-architectures/
https://brunch.co.kr/@leadbreak/23
https://pytorch.org/blog/training-moes/
https://github.com/microsoft/Swin-Transformer/blob/main/get_started.md#mixture-of-experts-support
https://huggingface.co/blog/moe
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
'NLP > LLM' 카테고리의 다른 글
| 도메인 특화 LLM 리서치 (4) | 2025.08.12 |
|---|---|
| MUVERA와 Mercury 리서치 (1) | 2025.07.15 |
| Codex (2021) 논문 리뷰 (1) | 2025.06.24 |
| LLM에서의 temperature, Top-k, Top-p, Penalties (0) | 2025.05.11 |
| LLM 서빙 관련 글 모음 (0) | 2025.04.27 |

