A Survey of Large Language Model - Wayne Xin Zhao et al (2024)
LLM에 대해서 공부할 때 전체적인 흐름을 파악하기 위해서 본 서베이 페이퍼다.
구글 스칼라에서 인용수가 2025년 3월 18일 기준 4000이 넘으며 2023년 이후 지속적으로 업데이트 되고 있는 논문이다.
특정 분야에 대해서 처음 접하거나 이미 공부한 다음 큰 틀에서 흐름을 정리하고자 할 때 유용한 것이 서베이 논문이라고 생각한다.
상기한 이유와 레퍼런스를 제외하고도 90페이지가 넘는 분량이기도 해서 전체적인 개요와 키워드, 그림 및 표 몇가지만 정리하고자 한다.
자세한 내용은 서베이 논문과 레퍼런스를 참고하면 좋겠다.
논문 목차 정리
1. Introduction:
Statistical Language Model (SLM), Pre-trained LM, Large LM
2. Overview:
Scaling Law, Instruction, In-Context Learning (ICL), Chain-of-Thought (CoT), Human Alignment, GPT series
3. Resources:
Checkpoints, API of LLMs, Data for Pre-Training, Fine-Tuning, and, Alignment Learning, Libraries
4. Pre-Training:
Model Architectures, Data, Preprocessing, Normalization Methods, Positional Embeddings, Various Attentions,
Decoding Strategies - including top k sampling
5. Post-Training
Instruction Tuning, In-Context Learning, Alignment Learning, Reinforcement Learning from Human Feedback (RLHF),
Proximal Policy Optimization (PPO), Supervised fine-tuning (SFT), Prefix Tuning, Adapter Tuning (including LoRA)
6. Utilization
Prompting, In-Context Learning (ICL), Chain-of-Thought (CoT) Prompting, Planning
7. Capacity and Evaluation
8. Applications:
Tasks, Domains, Multimodal Model, etc
9. Advanced Topics:
RAG, Hallucination, etc
10. Conclusion and Future Directions
1. Introduction

Statistical language models (SLM)
Natural language models (NLM)
Pre-trained language models (PLM)
Large language models (LLM)
2. Overview
2.1. Background or LLMs
KM scaling law
Chincilla scaling law
Predictable scaling
Task-level predictability
Emergent abilities of LLMs
- In-context learning (ICL)
- Instruction folowing
- Step-by-step reasoning
- Chain-of-thought (CoT)
Key Techniques for LLMs
- Scaling
- Training
- Ability eliciting
- Alignment learning
- Tools manipulation
2.2. Techinal evolution of GPT-series Models
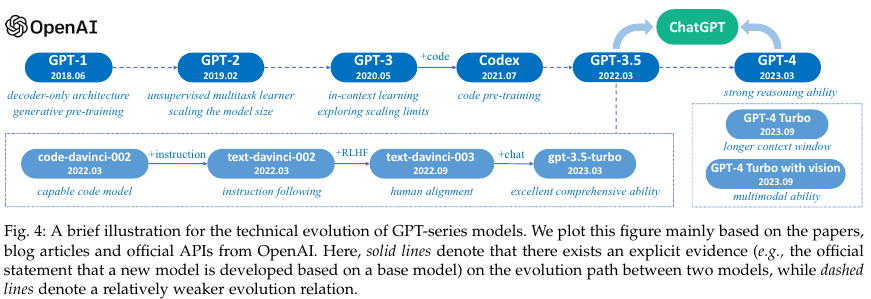
GPT-1
GPT-2
GPT-3
- Capacity Enhancement
- Training on code data
- Human alignment
- The Milestones of Language Models
ChatGPT
GPT-4 and beyond
3. Resources of LLMs
3.1. Publicaly Available Model Checkpoints of APIs
Publicaly Available Model Checkpoints
- LLaMA
- Mistral
- Gemma
- Qwen
- GLM
- Baichuan
LLaMA Model Family
Alpaca, Alpaca-LoRA, Koala, BELLE, Vicuna, LLaVA, MiniGPT-4, InstructBLIP, PandaGPT
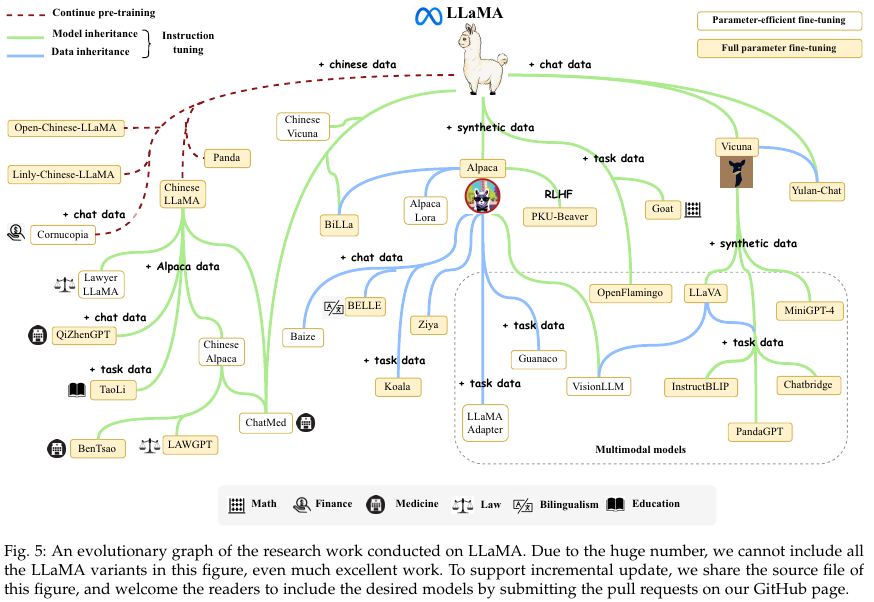
Public API of LLMs
GPT-series
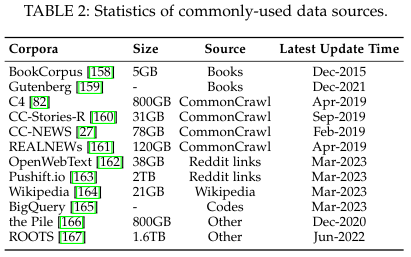
3.2. Commonly Used Corpora for Pre-training
Web pages
- CommonCrawl
- C4, The Colossal Clean Crawled Corpus
- RedPajama-Data
- RefinedWeb
- WebText
Books & Academic Data
- Book Data - Book Corpus
- Academic Data - arXiv Dataset, S2ORC
Wikipedia
Code
Mixed Data
- The Pile
- Dolma
3.3. Commonly Used Datasets for Fine-tuning
Instruction Tuning Datasets
NLP Task Datasets
P3
FLAN
Daily Chat Datasets
ShareGPT
OpenAssistant
Dolly
Sythetic Datasets
Self-Instruct-52K
Alpaca
Baize
3.3.2. Alignment Datasets
HH-RLHF
SHP
PKU-SafeRLHF
Stack Exchange Preferences
Sandbox Alingment Data
Library Resourse
- Transformers
- DeepSpeed
- Megatron-LM
- JAX
- Colossal-AI
- BMTrain
- FastMoE
- vLLM
- DeepSpeed-MII
- DeepSpeed-Chat
4. Pre-Training
4.1. Data Collection and Preparation
Data Source
Webpage
Converstaion text
Books
Multilingual text
Scientific text
Code
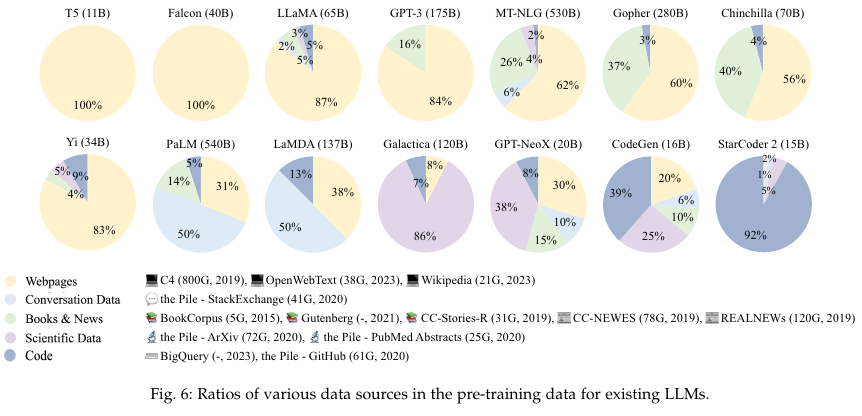
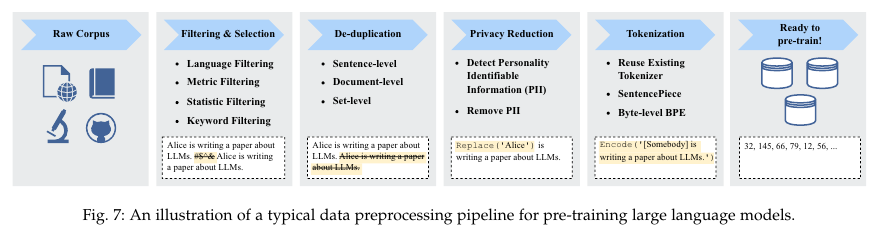
4.1.2. Data preprocessing
Filtering and selection
Privacy reduction
Tokenization
BPE (Byte-Pari Encoding)
WordPiece
Unigram tokenization
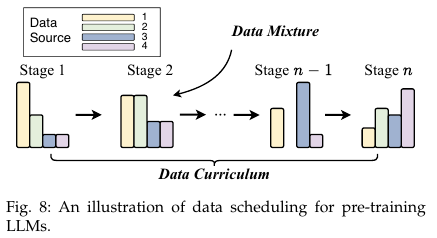
4.1.3. Data Scheduling
Data Mixture
Increasing the diversity of data sources
Optimizing data mixtures
Specializing the targeted abilities
Data curriculum
Coding
Mathematics
Long context
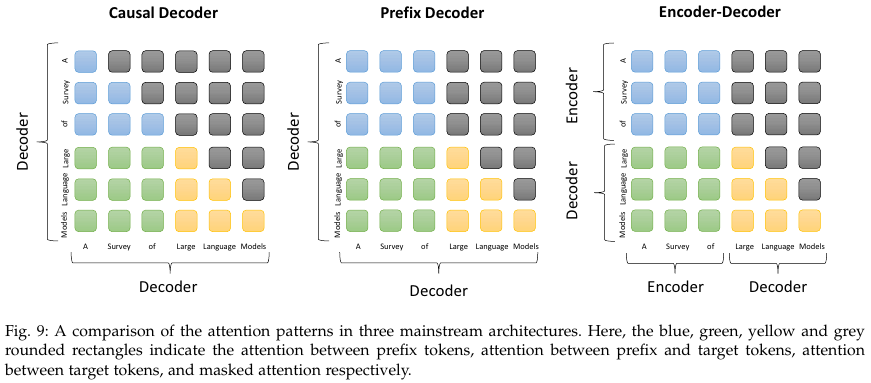
4.2. Architecture
Encoder-Decoder Architecture
T5, BART, Flan-T5
Causal Decode Architecture
GPT-series
OPT, BLOOM, Gopther
Prefix Decoder Architecture
U-PaLM
GLM
Mixture-of-Experts (MoE)
Switch-Transformer
GLaM
Mixtral
Emergent Architectures
SSM (State-space Model) - Mamba, RetNet, RWKV

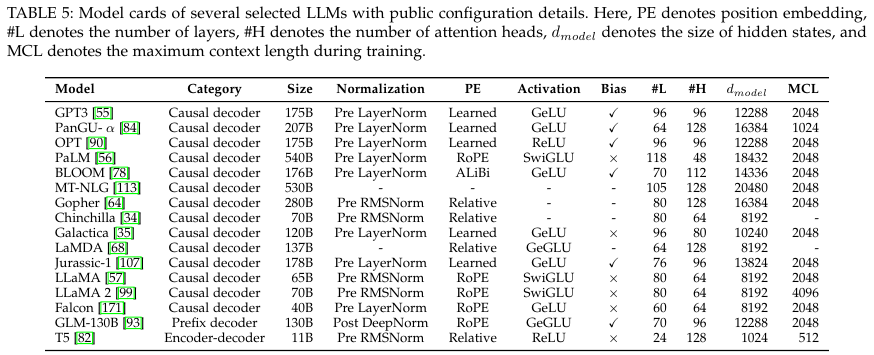
4.2.2. Detailed Configuration
Normalization Methods
- LayerNorm
- RMSNorm
- DeepNorm

Normalization position
- Post-LN
- Pre-LN
- Sandwich-LN
Position Embeddings
- Absolute position embedding
- Relative position embdding
- Rotary position embedding (RoPE)
- ALiBi
Attention
- Full Attention
- Sparse Attention
- Multi-query / grouped-query attention
- FlashAttention
- PagedAttention
4.2.3. Pre-training Tasks
Denoising Autoencoding
Mixture-of-Denoisers (MoD)
4.2.4. Decoding Strategy
Improvement for Greedy Search
- Beam Search
- Lenght penality
Improvement for Random Sampling
- Temperature sampling
- Top-k sampling
- Top-p sampling
4.3. Model Training
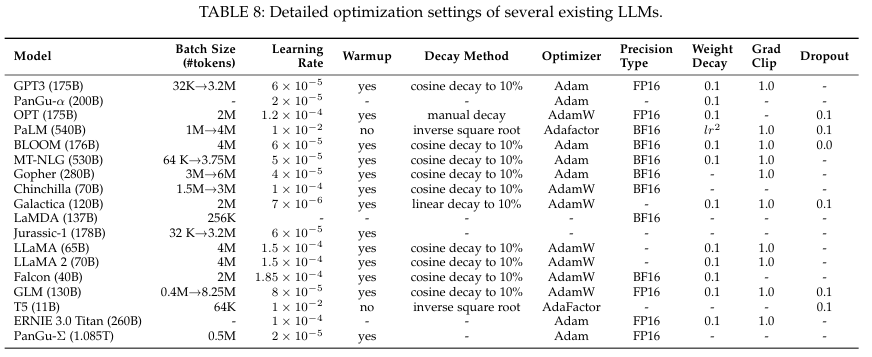
4.3.1. Optimization Setting
Batch Training
2048 examples or 4M tokens
dynamic schedule of batch size
Learning Rate
from 5 x 10^-5 to 1 x 10^-4.
Optimizer
Adam, AdamW, AdaFactor
Stabilizaing the Training
Gradient clpping to 1.0 and weight decay to 0.1
4.3.2. Scalable Training Techniques
Data paralleism
Pipeline parallelsim
Tensor parallelism
Mixed Precision Training
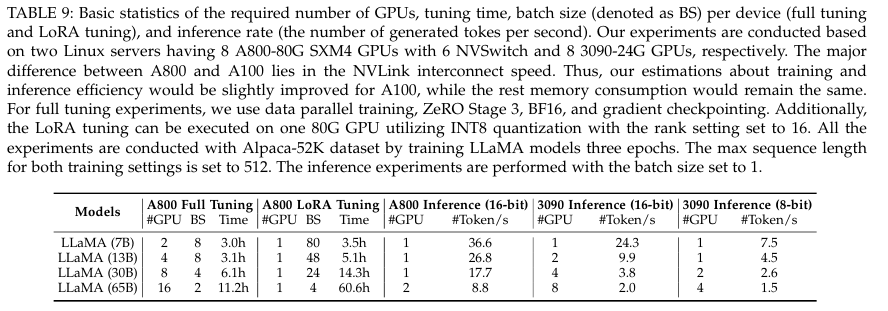
5. Post-Training of LLMs
5.1. Instruction Tuning
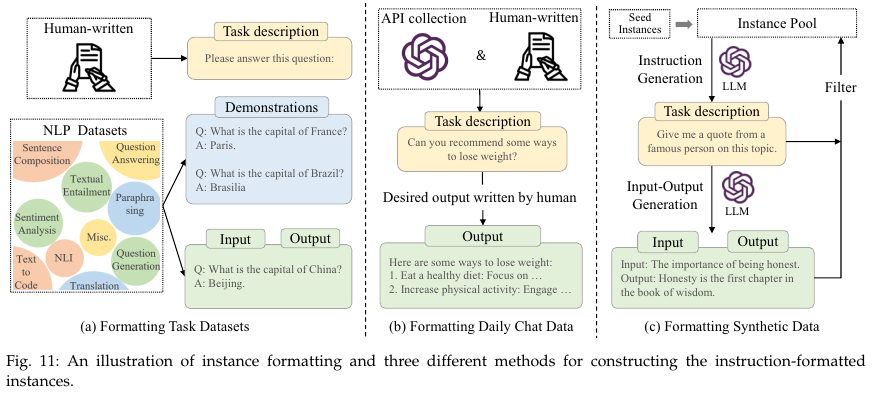
5.1.1. Formatted Instance Construction
Formatting Daily Chat Data
Formatting Synthetic Data
Formatting design
Instruction quality improvement
Instruction selection
5.1.2. Instruction Tuning Strategies
Balacing the Data Distribution
Combining Instruction Tuning and Pre-training
Multi-stage Instruction Tuning
Efficient training for multi-turn chat data
Establishing self-identificaiton for LLM
5.1.3. The Effect of Instruction Tuning
Performance Improvement
Task Generalization
Domain Specialization
5.1.4. Empirical Analysis for Instruction Tuning
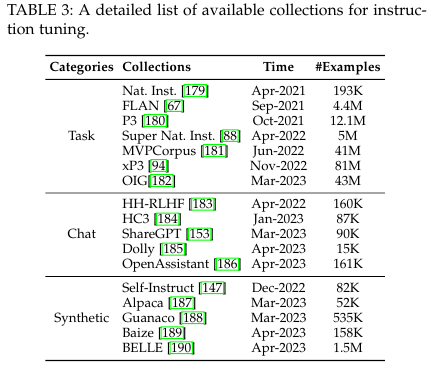
Instruction datasets
Task-specific instructions
Daily chat instructions
Synthetic instructions
Improvement Strategies
Enhancing the instruction complexity
Increasing the topic diversity
Scaling the instruction number
Balancing the instruction difficulty
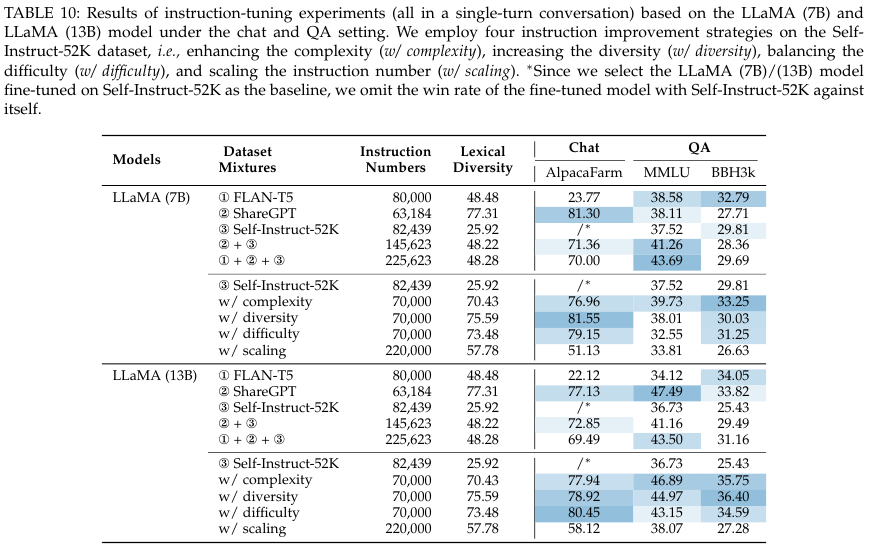
5.2. Alignment Tuning
5.2.1. Background and Criteria
Alignment Criteria
Helpfulness
Honesty
Harmlessness
5.2.2. Collecting Human Feedback
Human Labeler Selection
Human Feedback Collection
Ranking-based approach
Question-based approach
Rule-based approach
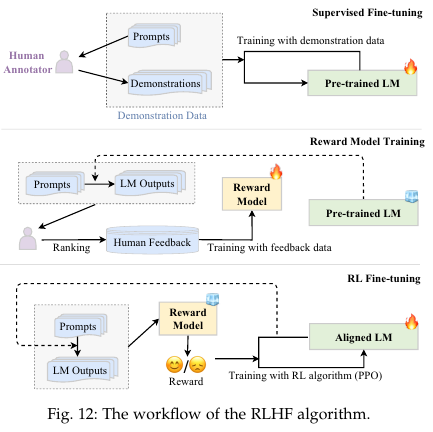
5.2.3. Reinforcement Learning from Human Feedback (RLHF)
Proximal Policy Optimization (PPO)
Supervised fine-tuning (SFT)
Reward model training
RL fine-tuning
Alignment without RLHF
Supervised Alignment Tuning

5.3. Parameter-Efficient Model Adaptation
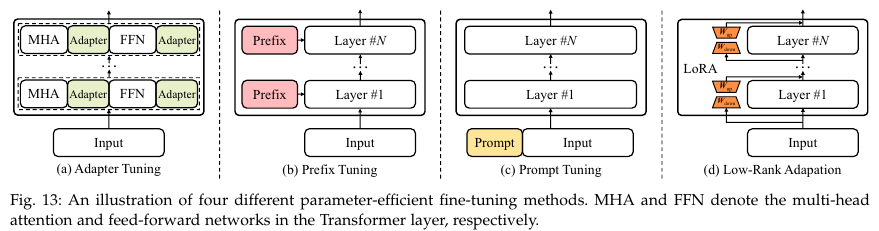
5.3.1. Parameter-Efficient Fine-Tuning Methods
Adapter Tuning
Prefix Tuning
Prompt Tuning
Low-Rank Adaptation (LoRA)
6. Utilization
6.1. Prompting

6.2. In-Context Learning (ICL)
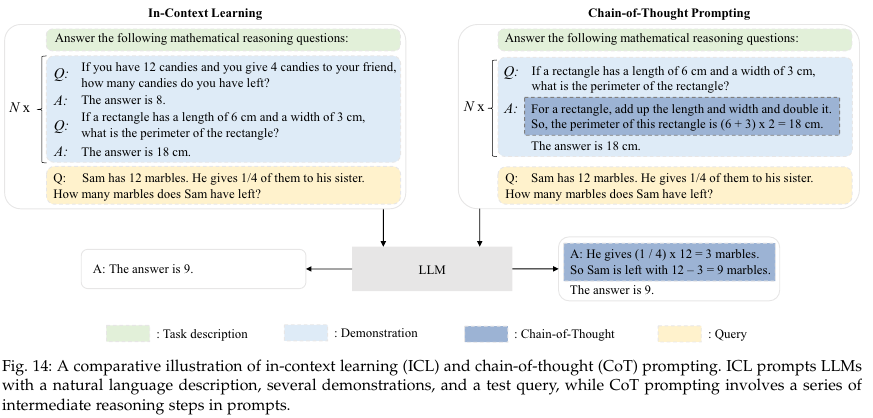
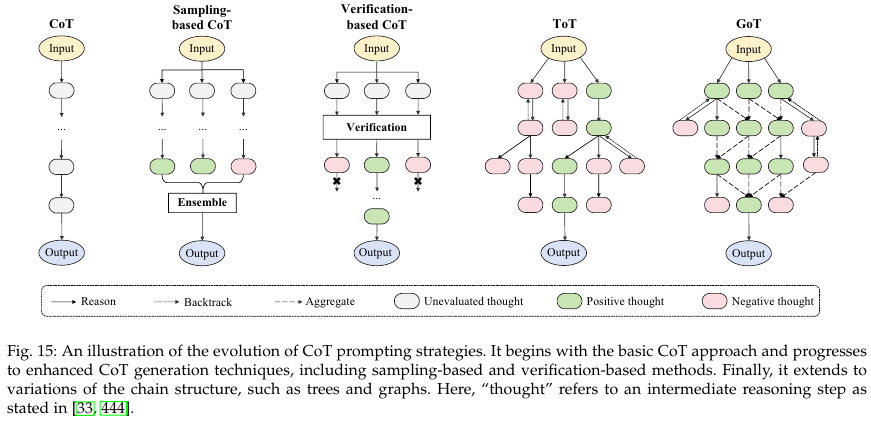
6.3. Chain-of-Thought (CoT) Prompting
Tree-of-Thought (ToT)란 개념도 등장
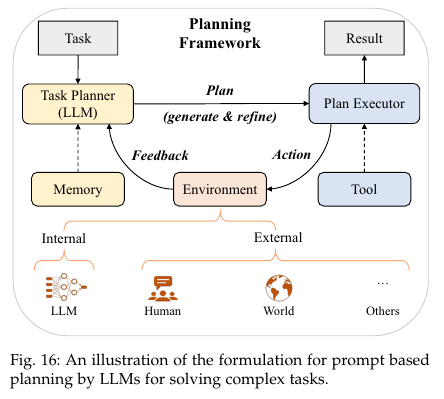
6.4. Planning

7. Capacity and Evaluation
7.1. Basic Ability
Language Generation
Text Generation
Code Synthesis
Closed-Book QA
Open-Book QA
Knowledge Completion
Knowledge Reasoning
Symbolic Reasoning
Mathematical Reasoning
7.2. Advanced Ability
Human Alignment
Interaction with External Environment
Tool Manipulation - Agent

7.3. Benchmarks and Evaluation Approaches
MMLU
BIG-bench
HELM
Human-level test benchmarks - AGIEval, MMCU, M3KE, C-Eval, Xiezhi
Evaluation on Base LLMs and Fine-tuned LLMs
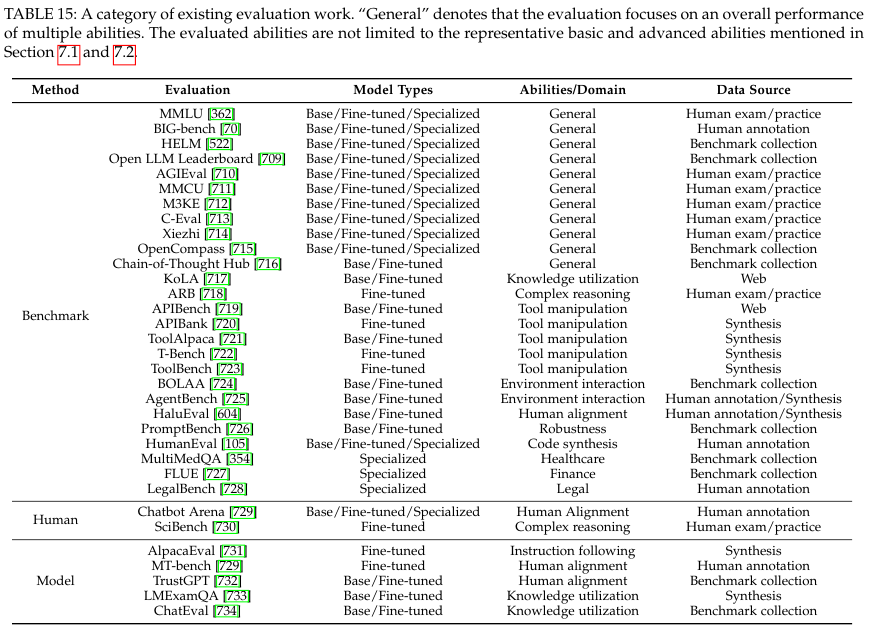
7.4. Empirical Evaluation
Open-source models
Closed-source models
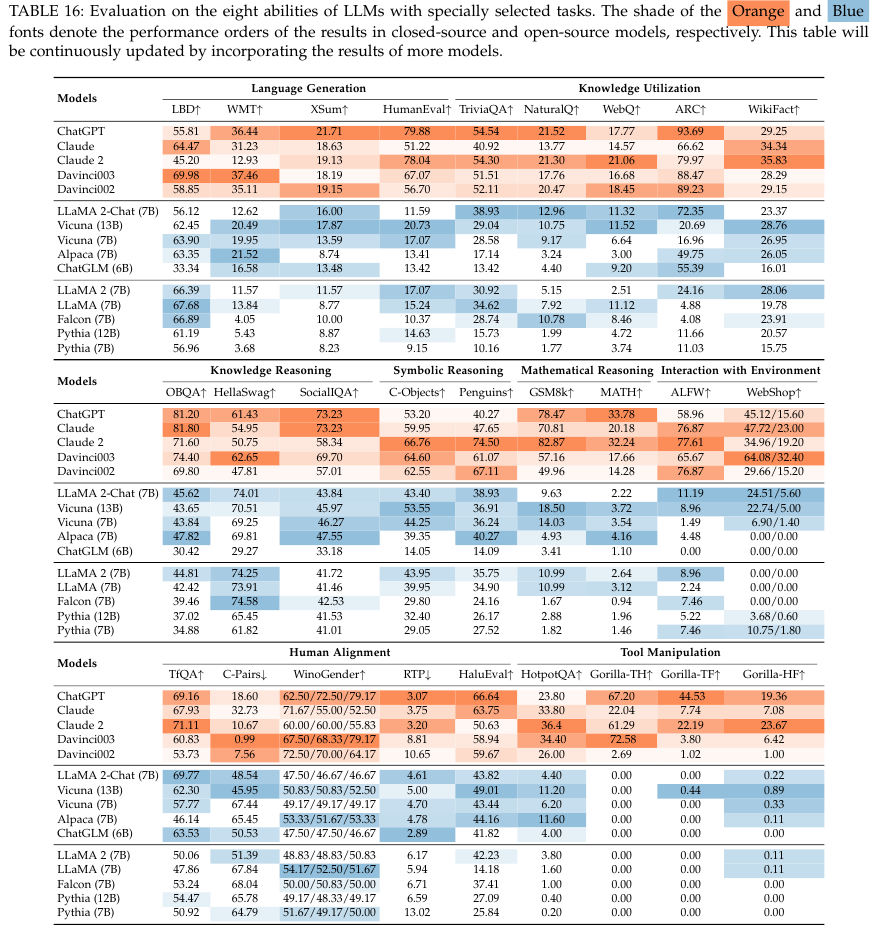
8. Applications
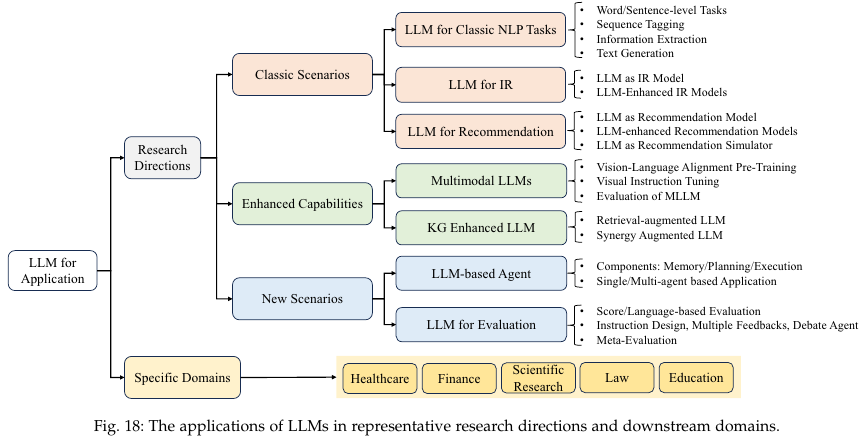
Classic NLP Tasks
- Word/Sentence-level Tasks
- Sequence Tagging
- Information Extraction
- Text Generation
- Summary
LLM for Information Retrieval
- LLMs as IR Models
- LLM-Enhanced IR Models
LLM for Recommender Systems
- LLM as Recommender Systems
- LLM-enhanced Recommender Systems
- LLM as Recommender Simulator
Multimodal LLMs - Text + Vision or Audio or etc
LLM for Evaluation
LLM for Specific Domains
Healthcare
Education
Law
Finance
Scientific research
9. Advanced Topics
- Long Context Modeling
- LLM-empowered Agent
- Analysis and Optimization for Model Training
- Analysis and Optimization for Model Inference

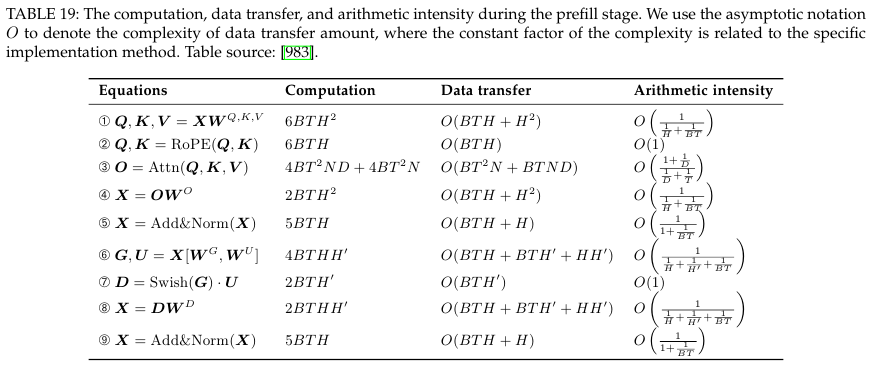
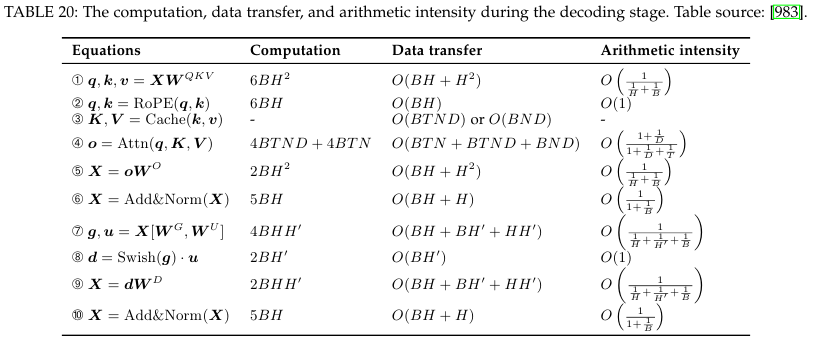
- Model Compression
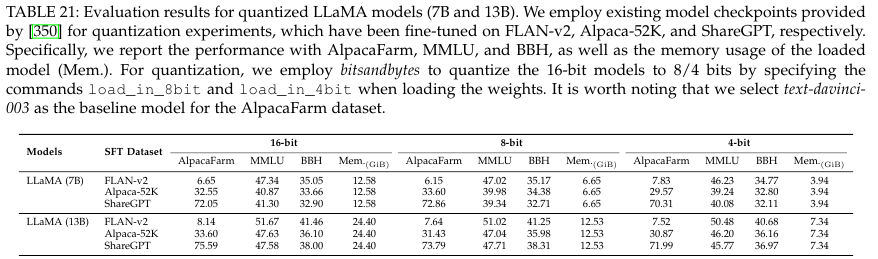
- Retrieval-Augmented Generation (RAG)
- Hallucination

10. Conclusion and Future Directions
Basics and Principles
Model Arthitecture
Model Training
Model Utilization
Saftey and Alignment
Application and Ecosystem
'NLP' 카테고리의 다른 글
| OpenAI Responses API vs Chat Completion API (0) | 2025.03.28 |
|---|---|
| Small Language Models: Survey, Measurements, and Insights (0) | 2025.03.17 |
| Instruct learning, fine tuning, and T5 (0) | 2025.01.28 |
| T5 (2019) 논문 리뷰 (0) | 2024.11.08 |
| RoBERTa (2019) 논문 리뷰 (0) | 2024.11.07 |


