Small Language Models: Survey, Measurements, and Insights - Zhenyan Lu et al (2024)
SLM에 대해서 공부할 때 본 논문으로 LLM 서베이처럼 간략하게 키워드 중심으로 정리하되 간단한 설명도 곁들이고자 한다.
1. Overview

OPT를 포함한 SLM의 타임라인이다.

BLOOM, Phi, Gemma, Qwen, SmolLM 외에도 다양한 SLM을 이 논문을 통해서 확인했다.
2. Architectures
아래에서는 전체적인 model의 구조를 KV-cache, Attention의 종류, Normalization의 종류, Activation의 종류 등을 일목요연하게 파이 차트로 정리한 그림으로 들어간다.
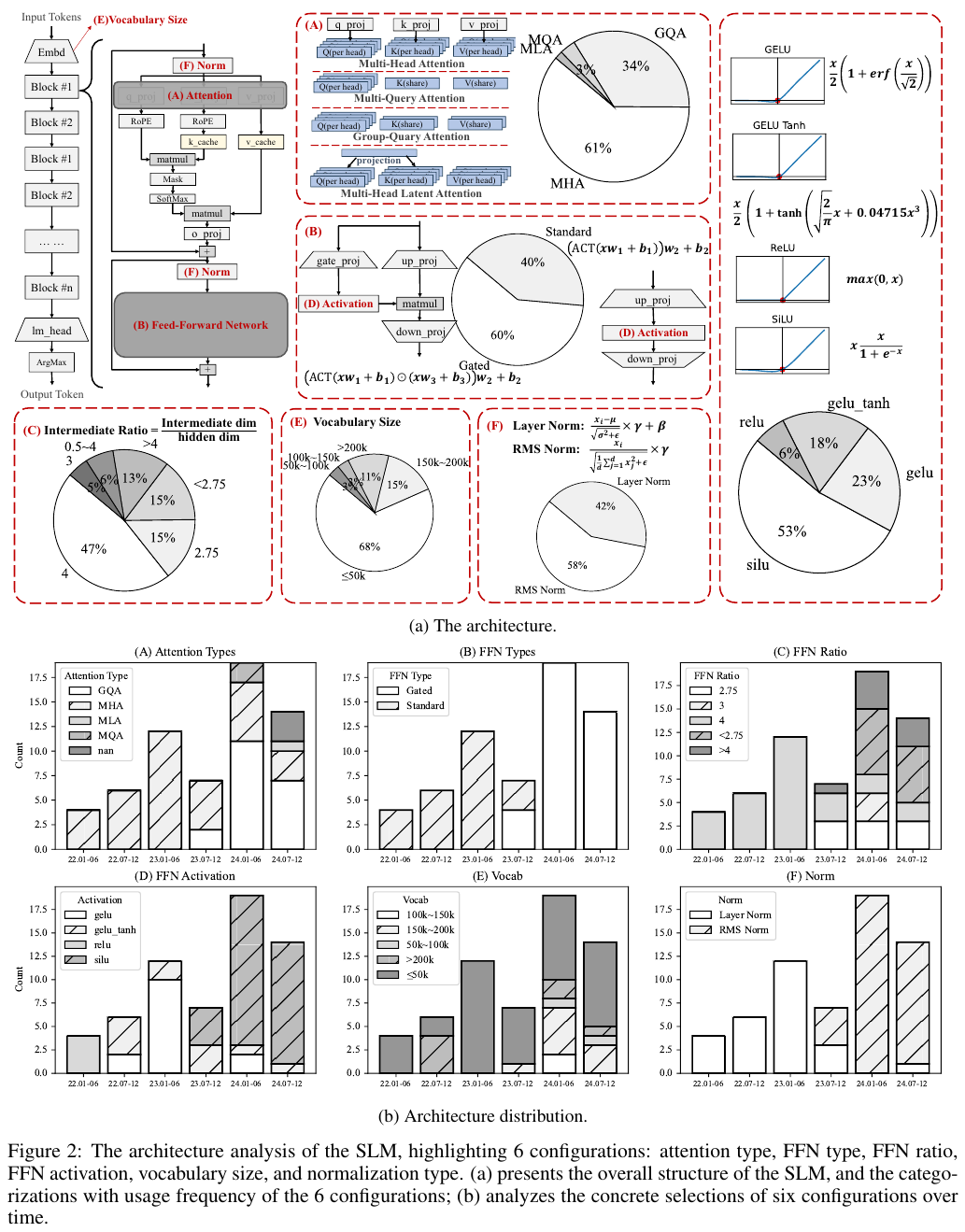
Attention Types:
- MHA (Multi-Head Attention)
- MQA (Multi-Query Attention)
- GQA (Group-Query Attention)
- MLA (Multi-Head Latent Attention)
LLM과 같이 SLM에서도 다양한 sharing parameters를 도입하여 latent features와 연산량 감소 사이에서 고민하고 있음을 알 수 있다. 자세한 사항은 위 Figure에 Q, K, V 중에서 어떤걸 sharing하는지 잘 안내하고 있다.
Normalization Methods
- Layer Norm
- RMS Norm
Activation Methods
- ReLU
- GELU
- SiLU
- GELU Tanh
FFN (Feed Forward Network) Types
- Standard
- Gated
Training Datasets
- The Pile
- WuDaoCorpora
- RoBERTa
- Pushshift.io Reddit
- SlimPajama
- StarCoder
- RedPajama
- RefinedWeb
- Dolma
- CulturaX
- FineWeb-Edu
- DCLM
- Cospomedia
본인은 기존에 The Pile, RoBERTa, RefinedWeb, FineWeb 위주로 봤는데 RedPajama도 한 번 눈여겨 볼 필요가 있을것 같다.
아래 표에서는 모델과 각 모델이 사용한 데이터 셋을 나타낸다.

SLM 역시 LLM처럼 하나의 데이터만 사용하지 않고 여러개의 데이터를 혼합해서 사용한다.

Chinchilla와 Gopher 논문에서 나타낸 scaling law에 따르면 전체적으로 더 큰 모델일수록, 더 많은 토큰을 학습할수록 성능이 좋은거 같지만 correlation이 약하다.
2.4. Training Algorithms
블로그의 소제목에 2.1부터 2.3까지가 없지만 논문에 2.4로 적혀있다. 혼선을 방지하기 위해서 논문의 숫자를 따르기로 한다.
1. Maximal Update Parameterization ( µP ):
initialization, layer-wise learning rates, and activation magnitudes를 활용해서 안정적인 학습을 요하는 방법이라고 한다.
작은 모델에서 사용하던 optimizer hyperparameters 특히 learning rate를 그대로 큰 모델에 쓸 수 있다고 한다. Cerebras-GPT에서 사용한 방법이다.
Note:
이 부분에서 이해가 잘 안되는데 큰 모델의 하이퍼파라미터를 작은 모델에 쓰는게 아니라 반대인가?
이 부분은 추가적인 학습이 필요하다.
2. Knowledge Distillation:
SLM이 아니더라도 딥러닝을 공부하다 보면 한 번쯤 볼 수 있는 익숙한 개념이다.
더 큰 모델이 teacher model이고 더 작은 모델이 student model이 되어 두 모델의 outputs의 차이를 줄이는 방법이다.
두 모델 사이의 loss와 student model 자체의 loss 설정이 중요하다.
LaMini-GPT 그리고 Gemma-2가 이 방법을 채택했다.
3. Two Stage Pre-training Strategy:
MiniCPM이 채택한 방식이다. Pretraining phase와 Annealing phase로 나뉜다.
Pretraining phase: MiniCPM은 비교적 정제가 덜 된 풍부한 양의 데이터 (coarse-quality pre-training data)로 학습한다.
Annealing phase: 다양하고 고품질의 지식과 ability-oriented SFT data를 pre-training data에 섞어서 사용한다.
3. SLM Capabilities
저자들은 3종류의 총 12개의 Datasets를 사용했으며 5-shot accuracy, 그리고 commonsense reasoning, problem-solving, mathematics의 경우 올바른 답을 골랐는지를 통해서 측정했다고 한다.
Commonsense Reasoning Datsets:
- HellaSwag: Tests narrative understanding through plausible sentence completion.
- TruthfulQA : Assesses the model’s ability to avoid providing false information.
- Winogrande: Evaluates pronoun ambiguity resolution using commonsense reasoning.
- CommonsenseQA: Presents multiple-choice questions requiring everyday knowledge.
- PIQA: Focuses on physical commonsense reasoning and object interactions. (물리학이 아닌 실생활에서의 물리적 작용을 포함한 상식적인 추론 평가)
- OpenBookQA: Combines scientific knowledge with commonsense for open-book science questions.
- BoolQA: Tests commonsense and factual reasoning with yes/no questions.
Problem-Solving Datasets:
- ARC Easy: Contains simple science questions testing general knowledge and reasoning.
- ARC Challenge: Presents complex science exam questions requiring knowledge integration.
- MMLU : Evaluates problem-solving across diverse academic disciplines.
Mathematics Datastes:
- GSM8K : Assesses grade-school-level mathematical reasoning skills. (초등수준)
- Minerva Math : Evaluates advanced mathematical reasoning across various topics. (고등학생 이상)
저자들의 경우 전체적인 성능 레퍼런스는 라마 모델들로 잡고 있다.
Llama 3.1 7B가 좋은 레퍼런스로 보인다.
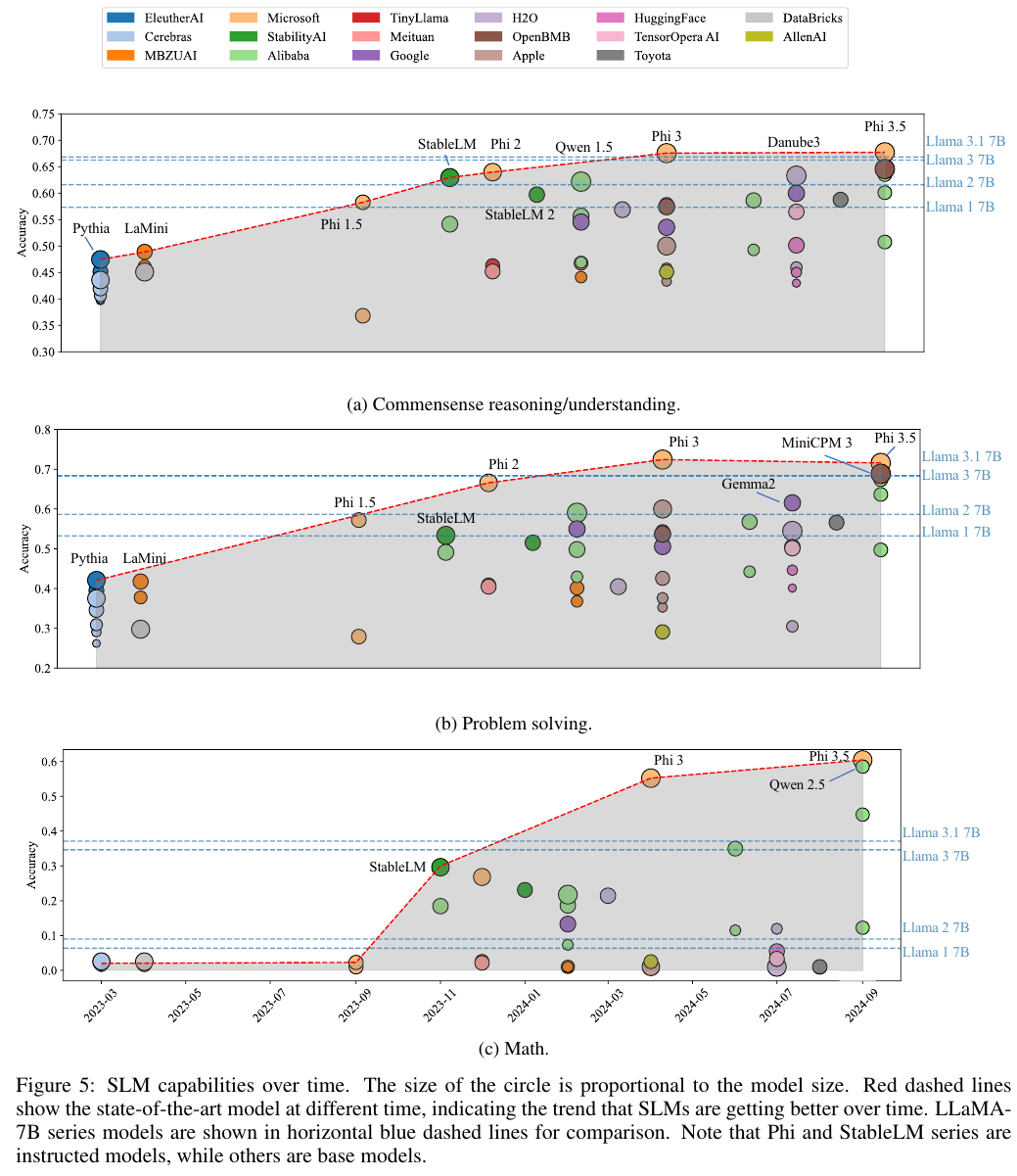

Phi 3.5, MiniCPM3, Gemma 2, Qwen 2.5 정도 모델들이 주목할 만한듯 하다.
4. SLM Runtime Cost
Inference Latency와 Memory Usage
실제로 활용함에 있어서의 생성 지연 시간과 메모리 사용에 관한 챕터다.
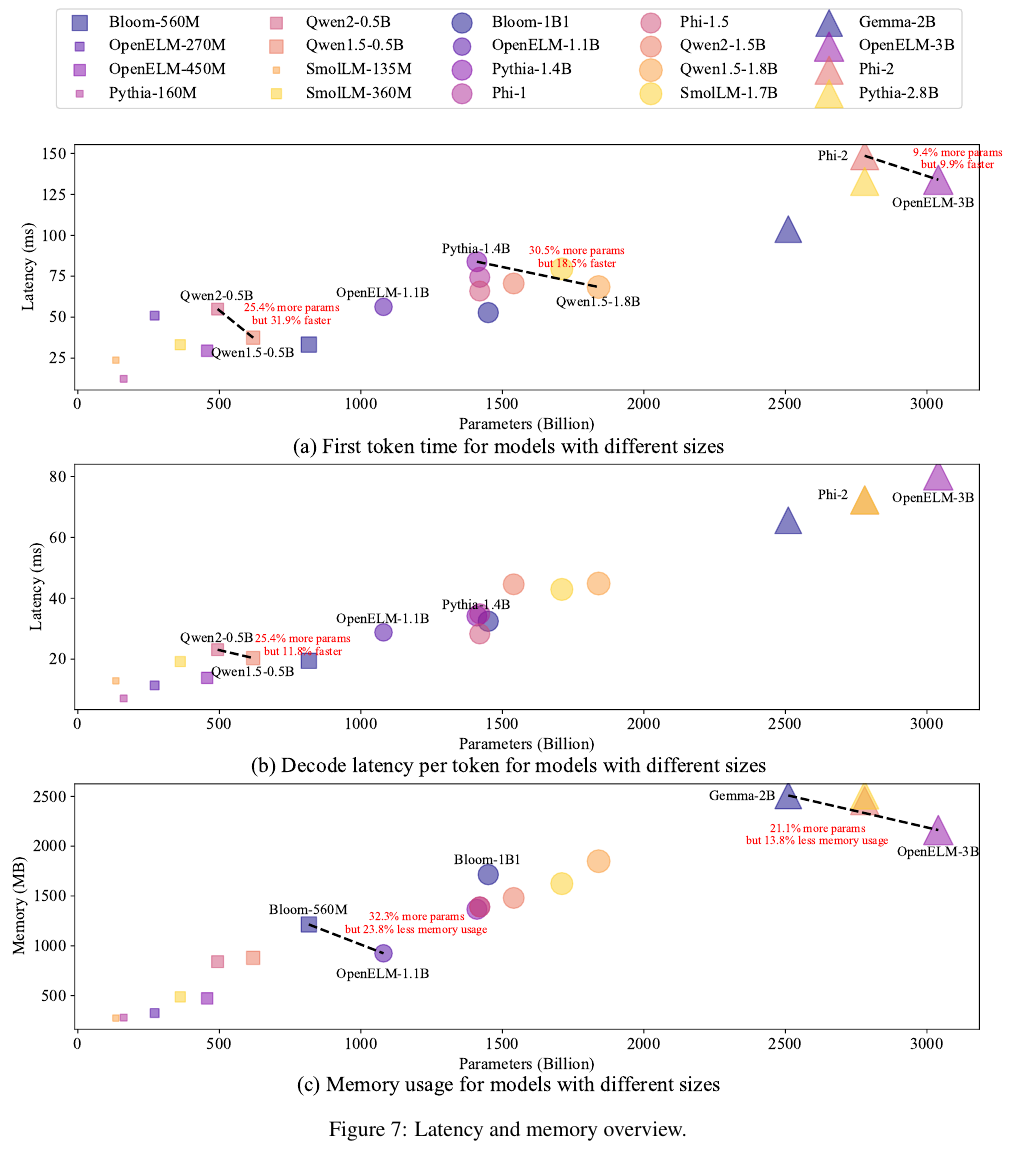
비슷한 파라미터들끼리 비교했을 때
첫 토큰 생성 시간에서 OpenELM 3B, 그리고 Qwen1.5 0.5B와 1.8B가 더 빨랐으며,
Decode에서는 Qwen1.5 0.5B가 더 빨랐고,
Memory usage에서는 OpenELM 1.1B와 3B가 더 효율적임을 알 수 있다.
아래는 Phi-1.5로 살펴본 quantization 비교 결과다.

Qn_K_M에서 n은 n-bits, K는 k-quants method의 k, M은 medium (M) number of parameters다.
그리고 K = 0은 대칭을 의미한다 (symmetric quantization). 보다 자세한 내용은 링크를 참조 하길 바란다.
LLaMA의 quantization 이전과 이후의 메모리 비교 깃허브가 있어서 참고차 올린다.
결과를 보면 latency가 낮은 Q4_K_M이 Phi-1.5에 있어서 베스트임을 알 수 있다.
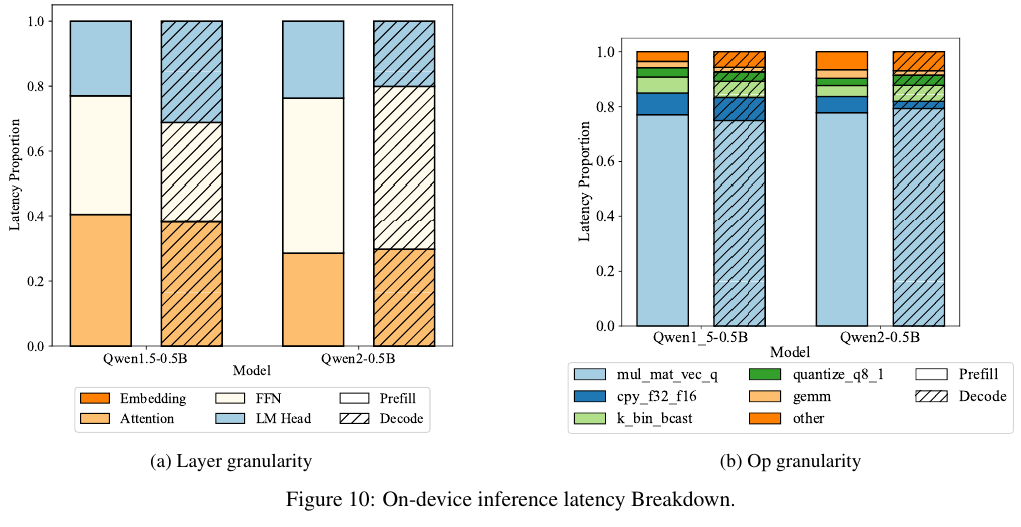
레이턴시가 언제 주로 발생하는지는 측정한 내용인데 레이어의 경우 Qwen 1.5와 2가 다르다.
구체적인 operation 레벨에서는 mul_mat_vec_q가 가장 많은 비중을 차지함을 알 수 있다.

메모리의 경우 대부분이 모델 파라미터가 가장 많은 부분을 차지한다.
OepnELM이 경우 KV Cache 비중이 극단적으로 낮은 모델임을 알 수 있다.
'NLP > LLM' 카테고리의 다른 글
| LoRA (2021) 논문 리뷰 (0) | 2025.04.11 |
|---|---|
| OPT (2022) 논문 리뷰 (0) | 2025.04.11 |
| GPT 3 (2020) 논문 리뷰 (5) | 2025.04.09 |
| A Survey of Large Language Model - Wayne Xin Zhao et al (2024) (0) | 2025.03.17 |
| LLM 개인용 유료 구독 가격 비용 정리 (0) | 2024.08.02 |


