파이토치 한국 사용자 모임의 박정환님의 RAG 서베이 논문과 관련된 글 1편과 2편 을 보다가 궁금해져서 찾아 보았다.
원본이 되는 RAG Survey 논문의 링크 역시 같이 포함한다.
주의점
위 2편의 글과 원본 서베이 논문을 보면 알겠지만 RAG의 검색 (Retrieval)파트와 생성 (Generation) 파트를 각각 별개로 평가할 수 있다는 점에 유의해야한다.
Downstream Tasks and Datasets of RAG

TraviaQA나 SST-2, GSM8K, HellaSwag 등등 익숙한 기존의 LM의 평가 데이터들도 많이 보인다.
하지만 결국 궁금한것은 최종적으로 구현하거나 가져와서 써야 하는 평가 함수, 즉 accuracy나 F1 score나 Exact Match (EM) 등 어떤 것을 써야하나였다. 다행히 그 결과는 아래 Table 3에 있었다.
Evaluation Metrics

Context relevance의 경우 Accuracy, Recall, Precision, Hit Rate, MRR, NDCG, BLEU, ROUGE 등을 사용한다.
아래는 위 평가를 보다 편하게 해줄 프레임워크들이다.
Evaluation Frameworks

개별 프레임워크의 주소를 첨부한다.
이외에도 RAG 전용은 아니지만 허깅페이스의 evaluate를 사용하는 방법도 있다.
Accuracy, Recall, Precision, BLEU, ROUGE 등등의 기본적인 지표뿐만 아니라 Matthews Correlation Coefficient나 Google BLEU와 같은 지표들도 이미 만들어져있어서 간편하게 사용할 수 있다.
Hugginface의 evaluate가 제공하는 여러가지 지표는 여기서 찾아 볼 수 있다.
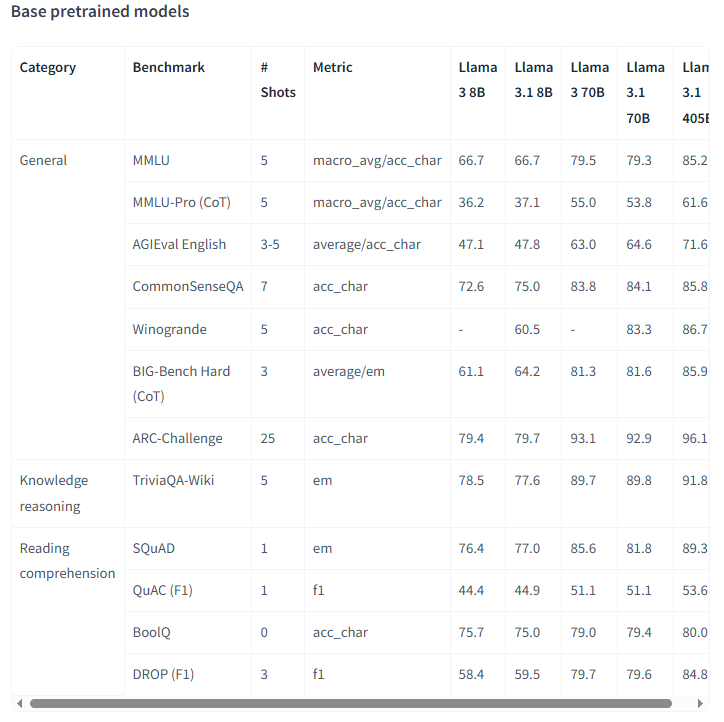
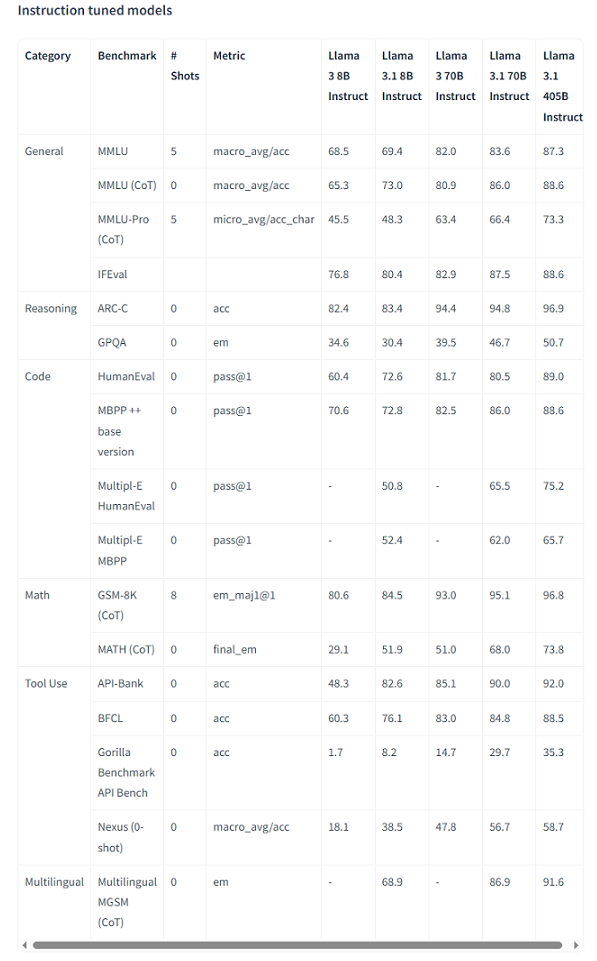
끝으로 RAG 성능 지표와의 비교를 위해서 우리에게 친숙한 LLaMA-3.1의 평가 지표를 첨부한다.
LLaMa-3.1 8B의 Evaluation Metrics
LLaMa-3.1 8B에서 사용하는 Evaluation Metrics는 다음과 같다.
References:
https://huggingface.co/meta-llama/Llama-3.1-8B
https://langbase.com/models/meta/Llama-3-70B/benchmarks
https://github.com/gomate-community/awesome-papers-for-rag
'NLP' 카테고리의 다른 글
| OpenAI Responses API vs Chat Completion API (0) | 2025.03.28 |
|---|---|
| RAGAS의 metric별 required columns (0) | 2025.03.28 |
| Small Language Models: Survey, Measurements, and Insights (0) | 2025.03.17 |
| A Survey of Large Language Model - Wayne Xin Zhao et al (2024) (0) | 2025.03.17 |
| Instruct learning, fine tuning, and T5 (0) | 2025.01.28 |

