AlexNet은 2012년 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)에서 우승한 현대 CNN 모델의 시초격인 모델이다.
AlexNet의 논문 이름은 ImageNet Classification with Deep Convolutional Neural Networks로 Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton 3인이 작성했다.
Abstract
ImageNet LSVRC-2010에서 제공하는 1000개의 클래스를 가진120만의 high-resolution 이미지들을 분류하기 위해 Large deep convolutional neural network을 학습했다. 테스트 데이터에 대해서 top-1과 top-5 error rates를 각각 37.5%와 18.0%를 달성해서 좋은 성능을 달성했다. 약 6천만개의 파라미터와 65만개의 뉴런, 5개의 convolutional layers, max pooling, 3단 fully-connected layers (이하 FCL), 그리고 마지막으로 1000-way softmax를 사용했다. Convolution 계산에 있어서 효율적으로 GPU 계산을 달성했다. 오버피팅을 방지하기 위해 dropout이라는 regularization method를 적용했다. 또한 ILSVRC-2012에서는 1위를 달성했는데 top-5 error rate가 15.3%로 2번째인 26.2%보다 좋았다.
Introduction
Object recognition에 있어서의 성능 향상을 위해서 더 많은 데이터를 모으고 더 강력한 모델을 학습하고 오버피팅을 방지해야 한다. 상대적으로 작은 크기의, 기존의 labeled images 데이터에는 NORB, Caltech-101/256, CIFAR-10/100, MNIST 등 다양한 데이터들이 있다.
100만 단위의 이미지들을 학습하기 위해서 더 복잡하고 큰 모델을 만들었으며, convolutional neural networks를 이용했다. 기존 cnn 모델들은 depth와 breadth가 각기 다르고 각각은 이미지 고유의 특성 (stationairty of statistics, and locality of pixel dependencies).
본 논문에서 제시하는 모델은 Large CNN이며, highly-optimized GPU implementations of 2D convolution이고, 120만개의 데이터를 충분히 학습할 수 있으며, 오버피팅을 방지하기 위한 여러 테크닉을 사용했다. 2개의 GTX 580 3GB GPUs로 5~6일에 걸쳐서 모델을 학습했다.
The Dataset
ImageNet은 총 150만개의 labeld high-resolution images다. 120만개의 training 데이터, 5만개의 validation 데이터, 1만 5천개의 test 데이터로 구성되어 있다. ImageNet 이미지들이 variable-resolution images기 때문에 여기서는 down-sample했다고 하는데, 모든 이미지들은 256 x 256으로 변형했다. 직사각형의 경우 짧은 부분을 256으로 변경한 후 center 256 x 256 crop out했다고 한다. 그외의 다른 pre-process는 진행하지 않고 centered raw RGB values of the pixels를 그대로 input에 넣어서 학습했다.
Methods = The Architecture
ReLU
여기서는 Rectified Linear Units (ReLUs)를 활용하여 nonlinearity (비선형성)을 확보했다. 하이퍼볼릭 탄젠트 tanh를 activation 함수로 쓸 수도 있지만 학습 성능에 있어서 ReLU가 훨씬 나음을 실험으로 보였다.

Multiple GPUs
Multiple GPUs로 모델을 학습했다.

Local Response Noramlization
논문을 보면 아래와 같이 local response normalization을 설명한다.
The response-normalized activity is given by the expression
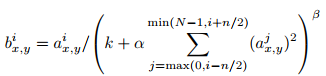
where the sum runs over n "adjacent" kernel maps at the same spatial position, and N is the total number of kernels in the layer.
같은 spatial position, 즉 3 x 3 matrix 같은 경우 n개의 kernel maps에 존재하는 1, 1 cell의 항목들끼리 위의 계산을 해주고, 1,2의 cell끼리 계산하고, ... 이런 계산을 반복해서 계산한다는 이야기다.
참조: Batch Normalization
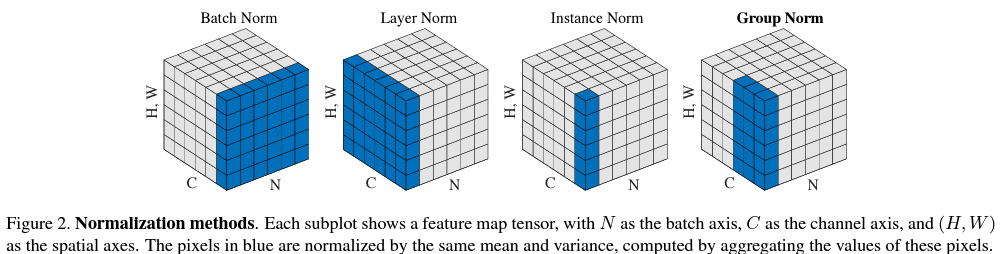
Batch Normalization은 N x H x W x C 의 데이터가 있을 때,
총 N개의 H x W x C 데이터가 있고, H x W x C은 총 H x W x C개의 cell이 있다.
따라서, 개별 cell을 batch N에 대해서 normalization을 수행한다.
이때의 normalization은 expectation과 variance로 수행한다.
PyTorch에서는 torch.nn.BatchNorm2d라는 명령어로 적용할 수 있다.
Overlapping Pooling
기존에는 adjacent pooling units를 수행할 때 겹치지 않게 수행했는데, AlexNet에서는 겹치도록 수행했다고 한다.
Recuding Overfitting
Data Augmentation
첫 번째로는, 이미지와 horizontal reflections에서 224 x 224 patches를 랜덤하게 추출한다고 한다.
테스트 단계에서는 위의 extracting을 5번 적용하고 그 평균으로 최종 예측을 수행한다.
두 번째 증강으로는 altering the intensities of RGB channels in training images라고 한다.
이는 PCA를 적용한 다음 그 components에 대해서 정규 분포 N(0, 0.1)에서 뽑은 magnitude만큼 곱해서 더한다.
Dropout
0.5의 확률로 dropout을 적용한다. 처음 두 개의 FC layers에 적용한다.
Experiment
Details of Learning
SGD (Stochastic Gradient Descent)를 사용했으며, batch size는 128, momentum은 0.9, weight decay는 0.0005를 사용했다.
Initialization에서 weigths는 모두 정규분포 N(0, 0.01), 그리고 biases는 2, 4, 5번째 convs와 FC는 1로, 나머지 레이어들에 대해서는 0으로 지정했다고 한다. Initial learning rate는 0.01이다.
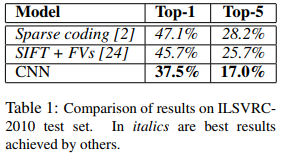
Sparse coding과 SIFT + FVs 보다 CNN이 ILSVRC-2010에 대해서 좋은 성능을 보인다.
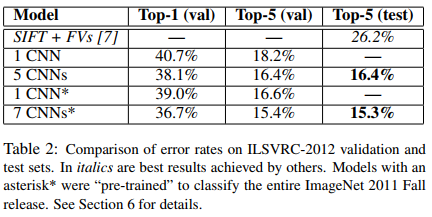
CNN의 레이어를 더 깊이 쌓을수록 ILSVRC-2012에 대해서 더 나은 성능을 보임을 알 수 있다.
Conclusion
Deep CNN 구조를 활용하여 challenging supervised learning에 대해 좋은 결과를 얻을 수 있었다.
CNN에 있어서 Depth가 중요함을 확인할 수 있었다.
Overall Structure

페이퍼에는 나와 있지 않은 항목이라 뒤로 뺐는데, 가독성과 모델에 파악을 위해서 다음 포스트 부터는 순서를 바꿔야하나 생각해봐야겠다.
하여튼 AlexNet의 구조는 위 Figure 4의 오른쪽 항목에서 알 수 있다.
5개의 Convolutional layers로 구성되며 FC는 3개의 Linear layers(aka MLPs, Multi-Layer Perceptrons)로 구성된다.
모든 Convolution의 뒤엔 ReLU가 뒤따라오며, Linear Layer의 경우도 softmax가 오는 맨 마지막을 제외하고는 모두 ReLU를 취한다.

Figure 5에서는 알렉스넷에 쓰인 파라미터의 수를 확인할 수 있다.
Pooling은 그 특징상 파라미터가 없으며 Conv과 FC의 파라미터 수를 합하면 약 60만개임을 알 수 있다.
References:
https://image-net.org/challenges/LSVRC/2012/analysis/
https://arxiv.org/abs/1803.08494
https://d2l.ai/chapter_convolutional-modern/alexnet.html
https://d2l.ai/chapter_convolutional-modern/batch-norm.html
https://stackoverflow.com/questions/40060949/how-to-calculate-the-number-of-parameters-of-alexnet
https://github.com/pytorch/vision/blob/main/torchvision/models/alexnet.py
'Computer Vision' 카테고리의 다른 글
| SPPNet (2014) 논문 리뷰 (0) | 2024.04.09 |
|---|---|
| R-CNN (2014) 논문 리뷰 (0) | 2024.04.04 |
| GoogLeNet = Inception v1 (2014) 논문 리뷰 (0) | 2024.04.03 |
| VGGNet (2014) 논문 리뷰 (0) | 2024.04.01 |
| Computer Vision 소개 (0) | 2024.02.21 |


