GoogLeNet은 VGGNet와 마찬가지로 2014년 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)에서 성공적인 결과를 달성한 모델이다. 또 다른 이름으로는 Inception v1 model이라고도 한다. (링크)
GoogLeNet의 논문 이름은 Going Deeper with Convolutions이라는 심플한 이름이다. 저자는 굉장히 많은데 Christian Szegedy, Wei Liu, Yangqing Jia, 그리고 그 외 6인이다.
Abstract
ILSVRC 2014의 classification과 detection을 해결하기 위해서 Inception이라는 deep convolutional neural network를 제안한다. 가장 큰 특징(hallmark)는 network 내의 컴퓨팅 리소스 활용의 개선이다. 이는 신중하게 뉴럴 네트워크의 depth와 width를 늘리면서 동시에 컴퓨팅 리소스 사용에 대한 예산을 고려했기 때문이다. 퀄리티를 담보하기 위해서 Hebbian principle과 multi-scale processing에 기반하여 작업을 수행했다. 구체적으로는 GoogLeNet이라는 22 layers를 가진 deep network를 ILSVRC14에 제출하였다.
1 Introduction & 2 Related Work
Introduction이 짧기도 하고 해당 문제 (여기서는 classification과 object detection)에 대한 기존 연구를 소개하기에 묶어서 소개한다.
GoogLeNet은 기존의 AlexNet 보다 12 x fewer parameters를 사용하고 동시에 더 좋은 성능을 보인다. 컴퓨팅 리소스을 반드시 고려해야 하는데, 이 때문에 computional budget을 추론 시에 1.5 billion multiply-adds을 유지하도록 설정했다. 또한 Network-in-Network를 많이 참조하였는데, representaional power를 향상시키기 위함이다. 특히 1 x 1 convolution을 활용하여 두 가지 목적을 달성하는데, 첫 번째는 dimension reduction으로 인한 파라미터 수의 감소이고 두 번째는 뉴럴 네트워크의 width 증가다.
Object detection 분야에서 현재 leading approach는 Regions with Convolutional Neural Network (R-CNN)이다. R-CNN은 object detection을 두 개의 하위 문제로 나눠서 해결하는데, 첫 번째는 low-level; color나 superpixel consistency으로 잠재적 object proposals를 category-agnostic fashion에서 제시하는 점이고 두 번째는 CNN classifiers로 해당 locations의 정체를 식별한다. 이를 통해 파워풀한 성능을 보였다. GoogLeNet은 object detection에서 R-CNN이 고전적 CV 기술과 CNN을 합쳤던 것 처럼 categorization 방식과 bounding box 제안 방식을 적절히 섞었다.
3 Motivation and High Level Considerations
Deep neural network (DNN)의 성능을 향상시키는 가장 간단한 방법은 네트워크의 크기의 증가다. 이는 depth (levels의 수)를 늘리는 방법과 width (개별 level에 속한 units의 수)를 늘리는 방법을 포함한다.
하지만 더 큰 크기의 모델은 오버피팅의 가능성이 증가하고 학습시키는데 비용이 많이 든다. 이를 해결하기 위한 궁극적인 방법은 dense fully connected에서 sparsely connected 구조로의 전환이다.
Arora et al [2](Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning
some deep representations. CoRR, abs/1310.6343, 2013)에 따르면 biological systems를 따라하는데 있어서 다음과 같은 결론을 주장했다. 데이터의 확률 분포가 large, very sparse deep neural network에 의해서 표현된다면 optimal network
topology는 layer by layer로 성립할 수 있다. 이는 highly correlated outputs인 the correlation statistics of the activations of the last layer와 clustering neurons을 분석함으로써 알 수 있다.
뒷 부분은 아직 명확하게 이해한 바는 아니나, 대략적으로 sparse matrix를 몇몇개의 dense matrices로 클러스터링을 취하여 sub-matrices를 만들어서 계산하면 더 효율적으로 가능하다고 주장하는듯 하다.
4 Architecture Details
Inception architecture는 CNN 안에 존재하는 optimal local sparse structure가 사용가능한 dense components로 표현가능하다는 아이디어에 기초한다.

Figure 2를 보면 논문에서 제시하는 Inception module을 확인할 수 있다. Network-in-Network라는 말에서도 알 수 있듯이, 거대한 CNN 구조 안에 또 다른 하나의 network가 존재하는 모양이다.
(a)에서는 1x1, 3x3, 5x5, 3x3 max pooling을 통해서 다양한 사이즈의 receptive field를 활용해서 이전 레이어의 피쳐를 학습함을 알 수 있다. (b)에서는 3x3과 5x5 convolutions 앞에 1x1 convolutions를 추가하여 channel 수를 줄여서 파라미터 수를 감소시키는 구조다. 또한 1x1 conv는 바로 뒤에 ReLU가 뒤따라 오기 때문에 non-linearity를 추가하는 효과도 있다.
3개의 conv와 1개의 max pooling을 거친 다음 filter concatenation으로 피쳐를 모으고, 다음 레이어로 내보낸다.
5 GoogLeNet
해당 챕터에서는 GoogLeNet의 구조를 설명한다.
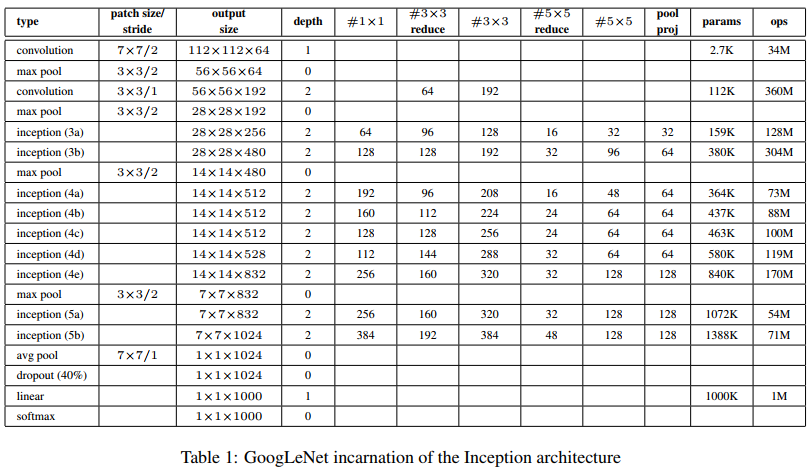
인풋 이미지는 224 x 224의 RGB 이미지다. Table 1에 쓰인 inception module은 Figure 2에 나온 (b)의 구조다.
해당 모델의 구조는 22 layers (pooling 포함 시 27 layers)이다.
AlexNet과 VGGNet에 없던 새로운 구조는 avg pool이다.
Auxcilary losses를 계산하기 위해서와 아래 Figure 3에 표기된 메인 softmax인 softmax2를 구하기 위서 쓰였다.

레퍼런스에 나온 블로그를 보고 안 내용인데 중간중간 가지가 나와서 생성하는 노란색 사각형 안의 softmax0와 softmax1는 auxilary loss들이라고 한다. 도입이유는 깊어지는 layers에 따른 vanishing gradient 문제를 해결하기 위함이다.
두 loss는 우리가 최종적으로 예측하고자 하는 softmax2에서 유래되는 loss 보다는 덜 중요하므로 가중치를 0.3만 준다.
메인 loss는 가중치를 1을 준다.
최종 inference 과정에서는 softmax0와 softmax1을 사용하지 않는다. Softmax0와 softmax1에서 나온 두 loss는 학습을 위한 보조 도구이기 때문이다.
아래의 내용은 auxilarary losses를 구할 때 쓰인 내용이다.
4a와 4d에는 5x5 sized filter, stride 3의 average pooling이 쓰였다.
Fully connected layer는 1024 units고 ReLU가 뒤따라 온다.
Dropout layer의 dropout ratio는 70%인 점도 50%였던 AlexNet이나 VGGNet과 다르다.
맨 마지막 FC layer와 softmax를 통해서 1000개의 클래스를 확률로 예측한다.
Table 1과 위에서 설명한 내용을 포함한 최종 아키텍쳐는 아래의 Figure 3에 그림으로 나와있다.
6 Training Methodology
DistBelief라는 distribued machine learniong system을 이용해서 모델을 학습했다. GPU를 사용했으며 몇개의 Multi-GPU로 1주일이 안 되게 걸려서 학습했다. Optimizer는 Asynchronous stochastic gradient descent를 사용했으며 momentum은 0.9고 fixed learning rate schedule을 사용했다. Learning rate가 every 8 epochs마다 4%씩 감소한다. Polyak averaging이 마지막 추론 시간에 쓰였다.
7 ILSVRC 2014 Classification Challenge Setup and Results
ILSVRC 2014에 쓰인 데이터는 AlexNet과 VGGNet에서 설명하였으므로 생략한다.
저자들은 7개 버젼의 서로 다른 GoogLeNet을 따로 학습하고 앙상블한 결과를 제출했다. 이때 모든 모델들은 같은 initialization, learning rate policies를 사용했지만 sampling과 input images의 순서만 서로 다르다.
보다 공격적인 crop을 사용했는데, 4 scales (256, 288, 320, 352)의 이미지 resize 후, left, center, right square crops를 각각 시행했다. 4개의 corners와 하나의 center 224 x 224 crop 그리고 mirrored versions를 사용했다. 따라서 4 x 3 x 6 x 2 = 144 crops per image가 된다. 데이터 증강을 통해 하나의 이미지에서 파생된 144개의 cropped images를 학습에 사용했다는 의미다.
Softmax probabilites는 multiple crops에 대해서 average를 취한 다음 이를 통해 최종적으로 클래스를 예측했다. 즉 144개의 이미지를 이용해서 원본 이미지 클래스 하나를 예측했다.
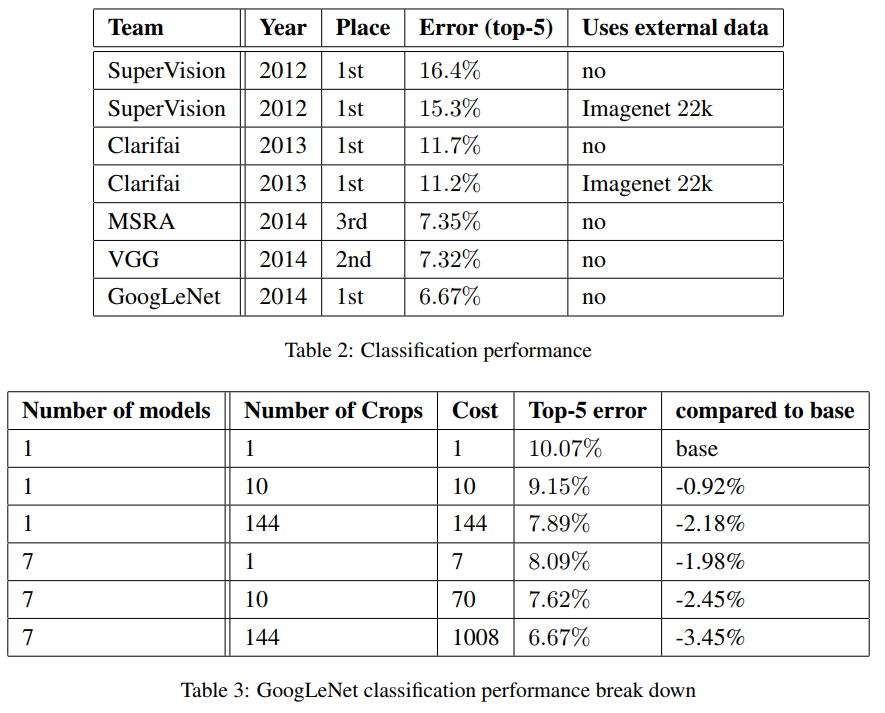
최종 submission에서 validation과 test 데이터에 대해서 각각 top-5 error는 6.67%을 달성했다. 자세한 결과는 Table 3에 나와있다.
8 ILSVRC 2014 Detection Challenge Setup and Results
Deep neural network (DNN)
ILSVRC detection task는 bounding box를 생성하고 해당 object에 대해서 200개의 클래스를 할당해야 한다. Detected object는 groundtruth와 bounding box가 적어도 50% 이상 겹쳤을 때 correct라고 센다. 최종 성능 지표는 mAP (mean average precison)으로 측정한다.
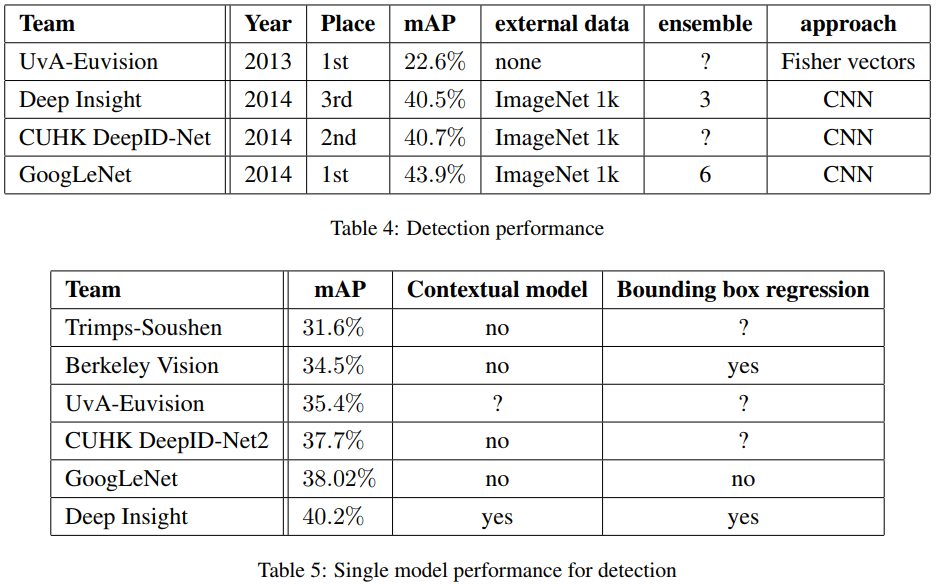
최종적으로 6개의 ConvNets를 앙상블해서 제출하여 성능이 40%에서 43.9%까지 상승했다.
자세한 내용은 아래 Table 5에 나와있다.
9 Conclusion
본 논문에서는 optimal sparse structure를 readily avaible dense building blocks로 근사함을 실제로 보였고 성능에서도 향상됨을 보였다.
Retrospective
AlexNet, VGGNet, GoogLeNet을 보고 든 생각인데 오래된 모델들이지만 경진대회를 통해 나온 모델들이기에
Dacon이나 Kaggle에 도전할 때 좋은 접근법을 약간 알아가는 것 같다.
References:
https://gaussian37.github.io/dl-concept-inception/
'Computer Vision' 카테고리의 다른 글
| SPPNet (2014) 논문 리뷰 (0) | 2024.04.09 |
|---|---|
| R-CNN (2014) 논문 리뷰 (0) | 2024.04.04 |
| VGGNet (2014) 논문 리뷰 (0) | 2024.04.01 |
| AlexNet (2012) 논문 리뷰 (0) | 2024.02.28 |
| Computer Vision 소개 (0) | 2024.02.21 |



