Chinchilla 모델이 등장한 논문의 이름은 Training Compute-Optimal Large Language Models다(링크)
저자는 Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, Laurent Sifre다.
딥마인드에서 발표한 논문으로 기존 딥마인드의 모델인 Gopher와 본 논문에서 새로 제시하는 모델인 Chinchilla의 파라미터, 학습한 데이터 토큰의 수를 비교하여 기존의 Scaling law가 유요한지를 탐구했다.
더 작은 모델에 대해서 더 많은 수의 토큰을 학습하면 더 좋은 성능을 달성할 수 있음을 보인 논문이다.
Abstract
400개가 넘는 언어 모델에 대해서 약 70 M 부터 16 B까지의 파라미터에 대해서 5 B 부터 500 B 의 토큰을 학습했을 때 compte-optimal 학습을 위해서는 모델의 크기와 학습 데이터의 수를 둘 다 균등하게 증가시켜야 함을 보인다.
같은 compute budget 연산 예산에 대해서 70B에 4배의 데이터를 학습한 Chinchilla 모델이 Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), Megatron-Turing NLG (530B) 보다 넓은 범위의 다운스트림 평가 지표에서 더 좋은 성능을 거두었음을 보였다.


Table 1과 4에서는 Chinchilla 모델의 구체적인 파라미터 수와 LaMDA, GPT-3, Jurassic, Gopher, MT-NLG와의 모델 사이즈와 학습 토큰 수를 비교한다.
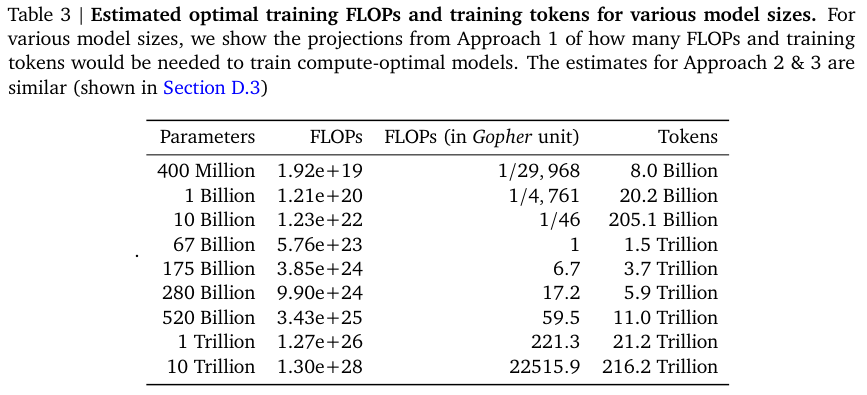
Table 3에서는 400 M 부터 10 T 까지 다양한 크기의 모델에 요구되는 적합한 토큰의 수를 새로 제시한다.

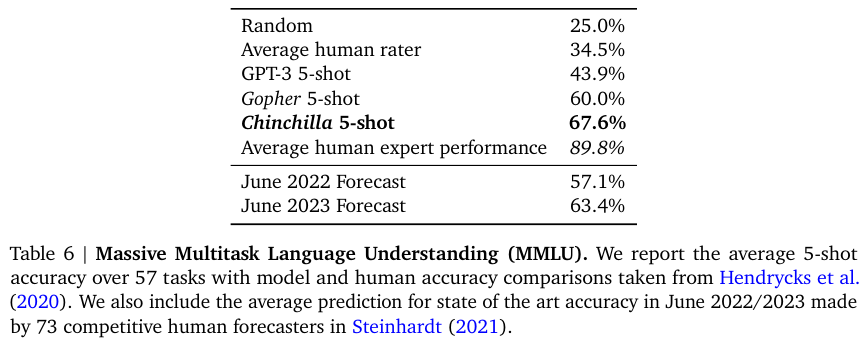
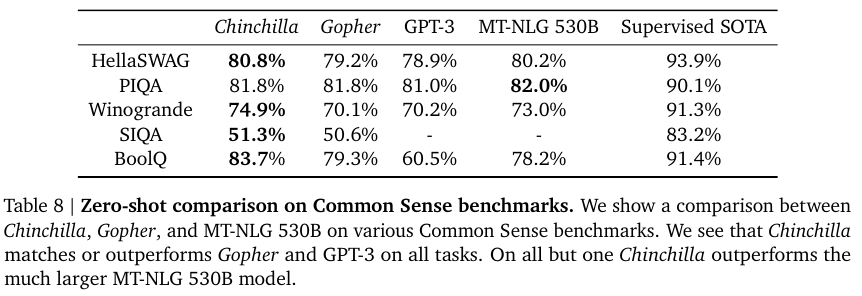
Table 5, 6, 8은 다양한 다운스트림 태스크와 그 결과를 나타낸다.
더 작은 사이즈지만 많은 토큰으로 학습한 Chinchilla가 SOTA를 달성했음을 알 수 있다.
References:
'NLP > LLM' 카테고리의 다른 글
| LLaMA (2023) 논문 리뷰 (0) | 2025.04.16 |
|---|---|
| InstructGPT (2022) 논문 리뷰 (0) | 2025.04.15 |
| LaMDA (2022) 논문 리뷰 (0) | 2025.04.11 |
| PaLM (2022) 논문 리뷰 (0) | 2025.04.11 |
| Scaling Laws for Neural Language Models (2020) 논문 리뷰 (0) | 2025.04.11 |



