LLaMA의 논문 이름은 LLaMA: Open and Efficient Foundation Language Models다. (링크)
저자는 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample다.
LLaMA 패밀리의 첫 모델이다.
Abstract
7B 부터 65B의 사이즈를 가진 LLM이다. 조단위의 토큰에 대해서 학습했다.
LLaMA-13B는 GPT-3 175B의 성능을 뛰어넘었으며 LLaMA-65B는 Chinchilla-70B와 PaLM-540B의 성능을 뛰어넘었다.
Pre-training data
- English CommonCrawl 2017-2020년도 데이터
- C4
- Github
- Wikipedia - bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk의 20개 언어를 포함
- Gutenberg and Books3
- ArXiv
- Stack Exchange
Tokenizer로는 BPE, 그리고 총 1.4 T 토큰을 활용했다.

Architecture
Decoder only 모델이다.
Pre-normalization [GPT-3]
RMSNorm을 사용
RMS Norm 간단히 설명 (논문 링크)
$\bar{x_i} = x_i / RMS(x)$. 이때 $RMS(x) = \sqrt{ \frac{1}{n} \sum_i^n x_i^2 }$
기존의 Layer Norm은 mean과 variance를 모두 계산한다.
이는 location shift와 scaling을 모두 수행한다는 의미인데,
mean을 0으로 변형하면 이 식이 바로 RMS Norm이다.
즉 location shift를 제외하고 scaling만 사용한다.
SwiGLU activation function [PaLM]
Rotary Embeddings [GPTNeo]
Relative Positional embedding의 하나다.
Optimier로는 AdamW, $\beta_1$ = 0.9, $\beta_2$ = 0.95
그리고 consine learning rate schedule,
weight decay는 0.1, gradient clipping은 1.0, warmup steps는 2,000을 사용한다.
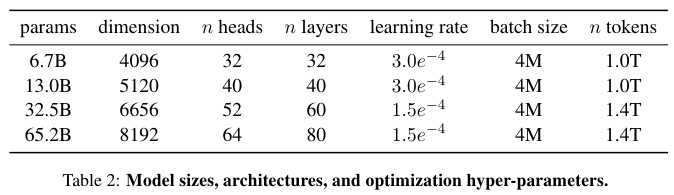
모델별로 구체적인 파라미터와 하이퍼 파라미터는 아래의 Table 2에 나와있다.
Efficient implementation
xformers를 활용했다.
65B 모델의 경우 학습하는 코드는 380 tokens/sec/GPU을 처리했으며,
80GB 램의 A100 2048대로 학습했다.
1.4 T tokens에 대해서 약 21일이 걸렸다.
Main Results
상식 추론, 클로즈드 북 QA, 독해, 수학 추론, 코드 생성에 대한 결과 표들이다.
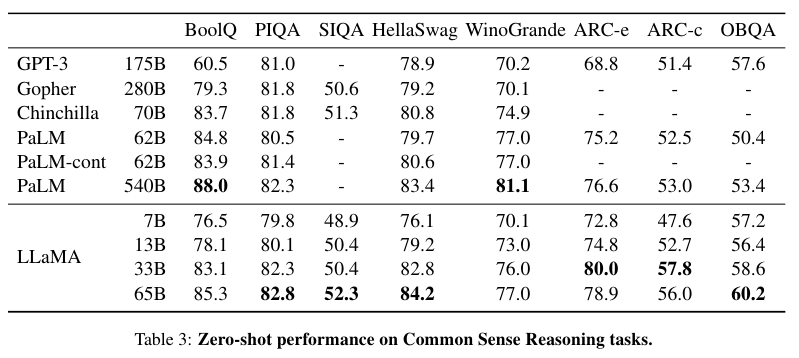


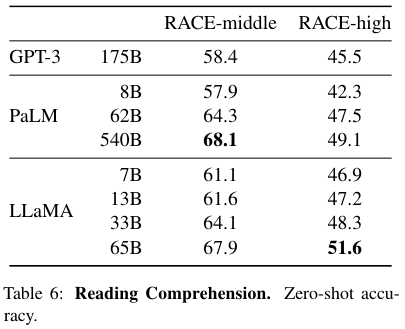


전체적으로 PaLM 모델과 비등비등하지만 약간 더 좋은 성능을 보여준다.
References:
https://velog.io/@wkshin89/MLDL-Rotary-Embeddings
https://velog.io/@alstjsdlr0321/Chapter-8.-LLaMA-2-Part1
'NLP > LLM' 카테고리의 다른 글
| LLaMA 2 (2023) 논문 리뷰 (0) | 2025.04.17 |
|---|---|
| Emergent Abilities of Large Language Models (2022) 논문 리뷰 (0) | 2025.04.17 |
| InstructGPT (2022) 논문 리뷰 (0) | 2025.04.15 |
| Chinchilla (2022) 논문 리뷰 (0) | 2025.04.11 |
| LaMDA (2022) 논문 리뷰 (0) | 2025.04.11 |



