Visualizing and Understanding Convolutional Networks 논문은 convolution network에서 깊이 마다 어떻게 피쳐가 학습되는지를 시각화한 논문이다. (링크)
저자는 Matthew D Zeiler, Rob Fergus다.
우선 layer의 깊이에 따른 구분을 먼저 적는다.
Input → Layer 1 → Layer 2 → ... → Layer K → Output
Input과 가까운 레이어들을 shallow layer, bottom layer라고 한다.
Output에 가까운 레이어들을 deep layer, top layer라고 한다.
함수의 입력을 밑에 넣고 중간의 함수를 거쳐서 위쪽으로 출력이 나오는 구조에서 bottom layer와 top layer가 유래했다고 한다.
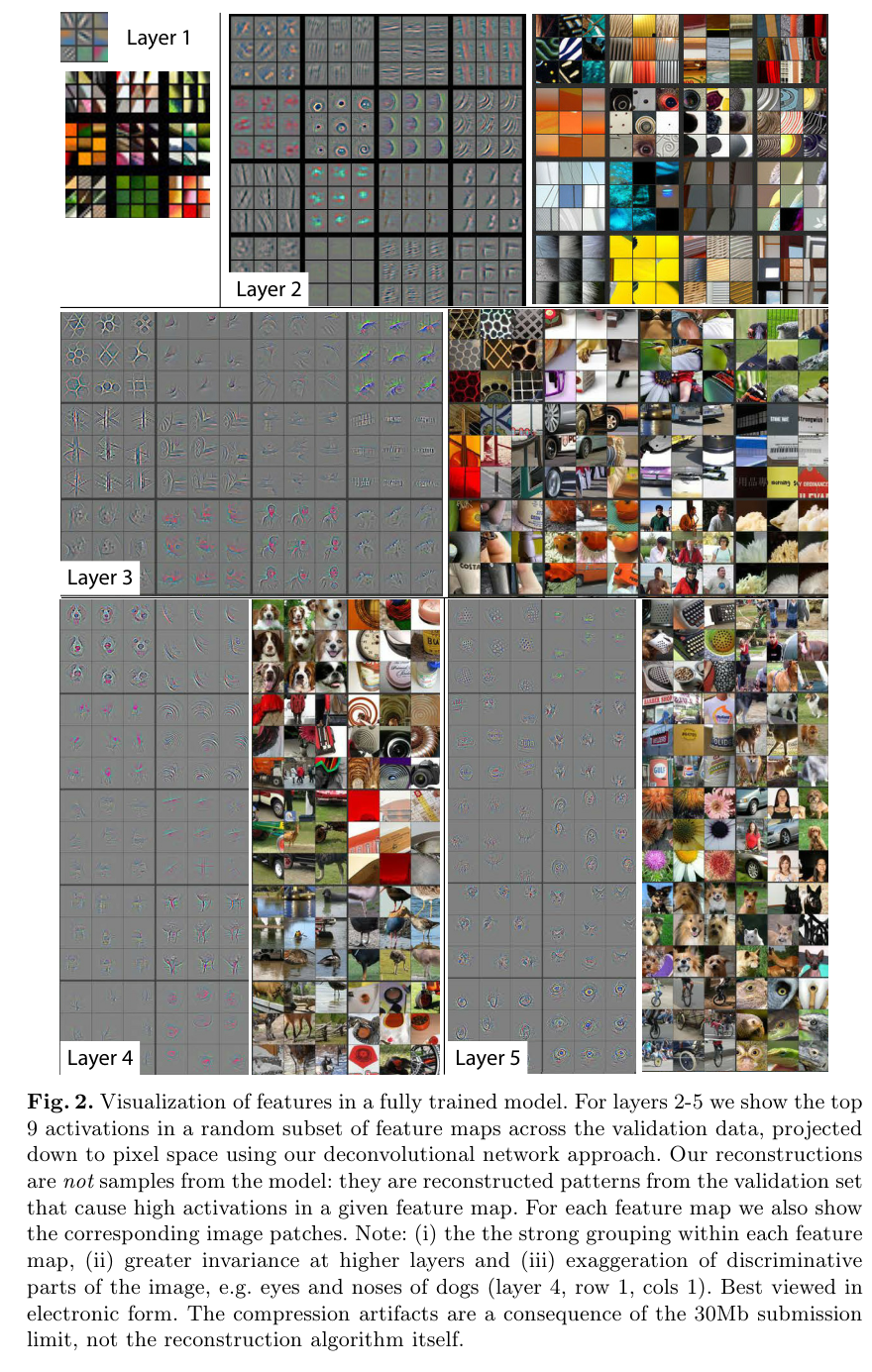
아래 Figure 2를 보면 레이어 마다의 피쳐의 복잡도를 시각화한 결과를 볼 수 있다.
shallow 레이어에서는 단순한 피쳐를 학습한다.
중간 레이어는 중간 정도의 복잡함을 지닌 피쳐를,
deep 레이어에서는 보다 복잡한 피쳐를 학습한다.
References:
https://news.mit.edu/2017/explained-neural-networks-deep-learning-0414
'Computer Vision' 카테고리의 다른 글
| FPN (2017) 논문 리뷰 (0) | 2025.04.25 |
|---|---|
| CRAFT (2019) 논문 리뷰 (1) | 2025.04.15 |
| ViT Vision Transformer(2021) 논문 리뷰 (1) | 2025.04.08 |
| YOLO v3 (2018) 논문 리뷰 (0) | 2025.04.08 |
| YOLO v2 (2016) 논문 리뷰 (0) | 2025.04.08 |



