CRAFT 논문의 제목은 Character Region Awareness for Text Detection이다. (링크)
저자는 Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, Hwalsuk Lee다.
Github: PyTorch 링크
OCR과 관련해서 한국의 Clova와 Naver에서 낸 논문이다.
ICAIF 2024에 참여했을 때 많은 금융 기업들이 문서 자동화에 LLM을 사용하는걸 보고 OCR도 알아두면 좋겠다 싶어서 본 논문이다.
Abstract
기존의 방법들은 rigid 엄격한 word-level bounding boxes를 이용했다. 하지만 본 논문에서는 개별 character 문자를 탐색하고 문자 사이의 affinity 관련성을 이용한다. TotalText와 CTW-1500를 포함한 6개의 벤치마크에 대해서 감지 성능의 SOTA를 달성했다.

3. Methodology

VGG-16을 바탕으로 하여 변형을 가했다.
U-net처럼 중간 중간 conv stage에서 feature map을 뽑아서 추가한다.
3.2. Training
Region score와 Affinity score라는 groundtruth label을 생성했다.
Figure 3에 자세하게 과정이 나와있다.

총 3단계를 거쳐서 groundtruth labels를 생성한다.
1) 2-dim isotropic Gaussian map을 준비한다.
isotropic Gaussin distribution은 multivaraite Gaussian의 모든 independent varaibles의 상관 관계가 없는 특수한 분포를 뜻한다.
2) character box에 맞게 2-d Gaussian map을 변형할 perspective transform을 계산한다.
3) Gaussian map을 perspective transform를 이용해 warp 변형한다.
Weakly-supervised learning

Figure 4에서는 전반적인 학습 과정을 보여준다.
Synthetic image 합성 이미지는 region score와 affinity score를 계산하고 이를 synthetic GT (GroundTruth)와 SSE를 계산한다.
이때 loss의 사용되는 계산값은 각각의 confidence score다.
Confidence score를 다음과 같이 정의된다.
Sample word $w$에 대해서 $R(w)$은 bounding box의 region, $l(w)$는 word의 length다.
estimated bbox와 문자열의 길이는 $l^{c}(w)$로 나타낸다.
$s_{conf}(w) = \frac{ l(w) - min( l(w), | l(w) - l^c (w) ) }{ l(w) }$.
Pixel-wise confidence map $S_c$는 다음과 같이 정의된다.
$S_c$ = $s_{conf}(w)$ if $p \in R(w)$ and 1 otherwise.
이때 $p$는 region $R(w)$에 있는 픽셀이다.
Objective L은 다음과 같이 정의된다.
L = $ \sum_{p} S_c (p) \cdot ( || S_r (p) - S_r^{*} (p) ||_2^2 + || S_a (p) - S_a^{*} (p) ||_2^2 ) $
이때 $r$은 region score를, $a$는 affinity score를 나타낸다.
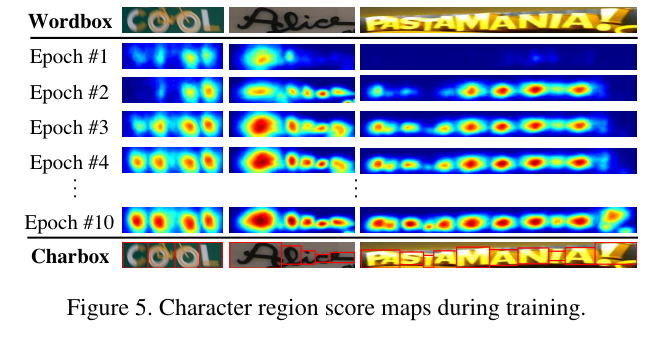
Figure 5에서는 학습 과정에서의 character region score 문자 영역 스코어에 대한 히트맵을 보여준다.
Real Image의 경우는 합성 이미지와 다르게 Crop, split word into characters, Unwarping의 과정을 거친다.
위 Figure 4와 아래의 Figure 6을 참조하면 알 수 있다.

3.3. Inference
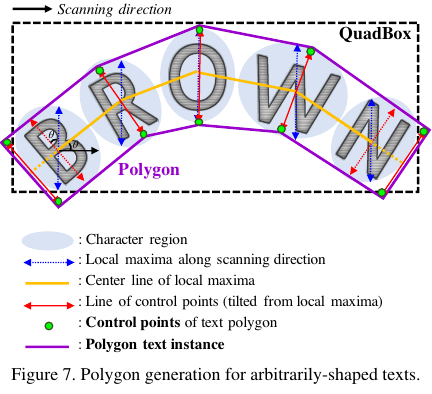
Non-Maximum Suppression (NMS)와 같은 추가적인 post-processing 과정을 이용하지 않는다.
대신 전체 문자에 대한 추가적인 polygon을 생성하여 curved texts에 대응한다.
4. Experiments
4.1. Datasets
- ICDAR2013
- ICDAR2015
- ICDAR2017
- MSRA-TD500
- TotalText
- CTW-1500
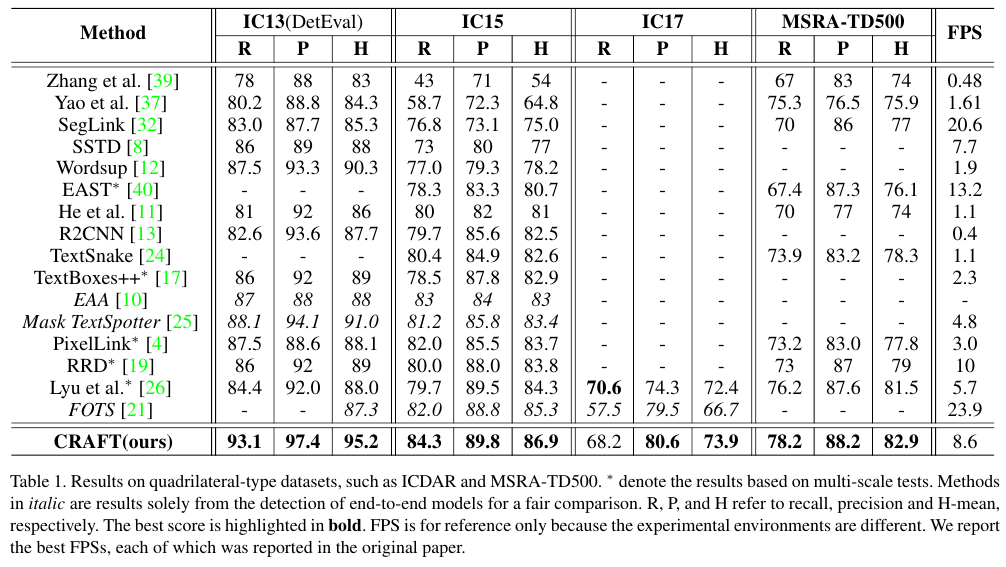

Table 1과 2를 보면 CRAFT가 대부분의 데이터에 대해서 최상의 성능을 달성함을 알 수 있다.

Figure 8은 TotalText 데이터에 CRAFT 방법을 적용한 결과의 예시다.
'Computer Vision' 카테고리의 다른 글
| YOLO v4 (2020) 논문 리뷰 (0) | 2025.04.27 |
|---|---|
| FPN (2017) 논문 리뷰 (0) | 2025.04.25 |
| Visualizing and Understanding Convolutional Networks (2013) 논문 리뷰 (0) | 2025.04.11 |
| ViT Vision Transformer(2021) 논문 리뷰 (1) | 2025.04.08 |
| YOLO v3 (2018) 논문 리뷰 (0) | 2025.04.08 |



