Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection 논문이다. (링크)
저자는 Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi다.
스스로를 평가하면서 RAG를 수행하는 방법론이다.
전에 블로그에 쓴 글 (링크)에서 공부하면서 Self-RAG를 살짝 살펴보았지만 논문을 제대로 본적은 없어서 정리할 겸 리뷰한다.
Abstract
RAG는 factuality 사실성의 측면에서 도움이 되었지만 indiscriminately 무차별적인 retrieving 검색과 고정된 수의 검색된 passages 구절의 수, 검색된 구절의 연관성 등이 LM's versatility 언어모델의 다재다능함을 약화시킨다.
본 논문에서 제시하는 Self-Reflective Retrieval-Augmented Generation (SELF-RAG)는 retrieval과 self-reflection으로 LM의 퀄리티와 사실성을 모두 향상시켰다. 적응적으로 on-demand의 개념으로 검색을 수행하며 검색된 구절을 이용할 때 reflection tokens라는 특수한 토큰을 사용한다. 7B와 13B 크기의 LLM을 사용해서 ChatGPT, retrieval-augmented Llama2-chat을 Open-domain QA의 reasoning과 fact verification task에서 성능적으로 추월했음을 보였다.
3. Self-RAG: Learning to Retrieve, Generate and Critique
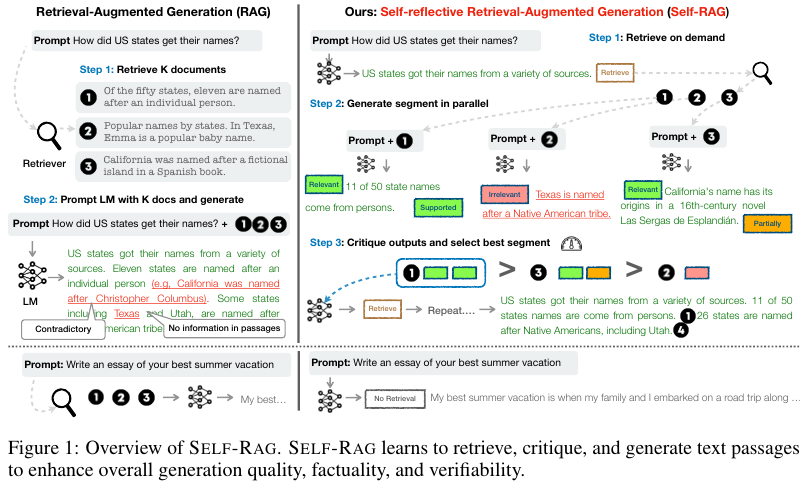
Self-RAG의 전반적인 플로우는 Figure 1과 같다.
Step 1. Retrieve on demand
Step 2: Generate segment in parallel
Step 3: Critique outputs and select best segment
입력은 $x$, 모델은 $M$, 연속적인 텍스트 출력은 $y = \left[y_1, y_2, ..., y_T \right]$로 나타낸다.
$T$는 segment의 개수이고, $y_t$는 $t$ 번째 segment의 토큰들의 시퀀스다.
$y$는 원본 vocab의 단어일 수도 있고 reflection tokens일 수도 있다.
검색된 문서는 $d$로 표시한다.
Reflection tokens는 아래 Table 1에 나와있다.

Retrieve:
질의 x에 대해서 검색을 수행할지 말지를 결정.
yes, no, continue.
여기서 yes와 no는 검색을 할지 말지를 결정하는 부분이다.
continue는 기존에 검색된 문서가 있어서 이를 그대로 활용함을 의미한다.
IsRel:
검색된 문서의 관련성 평가.
Relevant, Irrelevant의 binary score다.
IsSup:
답변 y에서 진술된 내용들이 검색된 document d에 의해서 충분히 검증되고 있는가를 평가
Fully supported, Partially supproted, No support / Contradictory
triple score다.
IsUse:
답변 y가 질문 x에 대해서 유용한 답변인가를 평가
논문에서는 1점 부터 5점까지 5개의 정수로 나타낸다.
자세한 내용 원문은 논문의 Appendix A.1 Refelection Tokens에 나와 있다.
Figure 1의 내용을 알고리즘의 형태로 도식화 하면 아래와 같다.

3.2 Self-RAG Training
3.2.1. Training The Critic Model
Data Collection for Critic
수작업으로 reflection 토큰을 annotation하는 작업은 비싸다. 대신 LLM을 이용해서 이를 생성한다.
GPT-4를 이용해서 supervised 방법으로 reflection tokens를 생성하고 그들의 지식을 in-house $C$로 증류한다.
각각의 리플렉션 토큰 그룹에 대해서, 오리지널 학습 데이터로 부터 몇개의 인스턴스를 샘플링한다.
그 다음 각각의 리플렉션 토큰의 그룹에 맞는 지시 프롬프트를 GPT-4에 제공한다.
Retrieve를 예로 들면 GPT-4에
“Given an instruction, make a judgment on whether finding some external documents from the web helps to generate a better response.”
라는 프롬프트를 넣는다.
오리지널 입력 $x$, 오리지널 출력 $y$, few-shot demonstrations $I$를 이용해서 리플렉션 토큰 $r$을 예측한다: $p(r | I, x, y)$.
저자들은 타입 별로 4k-20k의 지도 학습 데이터를 모아서 학습 데이터인 $C$를 구성했다.
Critic learning
학습 데이터 $D_\text{critic}$을 모은 다음 $C$로 pre-trained LM을 시작하고 그 다음 $D_\text{critic}$에 대해 standard conditional language modeling objective 표준적인 조건부 언어 모델링 목적함수를 설정하고 이를 maximum likelihood의 측면에서 최적화한다.
$ \underset{C}{max} \mathbb{E}_{((x, y), r) \sim D_\text{critic}} \text{log} \, p_C(r | x, y) $
Critic은 리플렉션 토큰의 카테고리에 대한 예측에서 GPT-4 베이스의 예측과 90% 일치한다.
3.2.2. Training The Generator Model
Data Collection for Generator
입력-출력 쌍 ($x, y$)이 주어지고, retrieval 검색기와 critic 모델 $C$를 이용해서 오리지널 출력 $y$을 증강하고 이를 통해 지도 학습 데이터를 생성한다.
정확히 Self-RAG의 inference-time process를 모방한다.
개별 세그먼트 $y_t$에 대해서 $C$를 통해서 추가적인 구절이 생성의 향상에 도움이 되는지 아닌지를 판단한다.
위 과정을 통해서 만약 검색기가 필요하다고 판단하면 retrieval special token Retrieve = Yes가 추가되고, 검색기 $R$이 top-K 구절을 검색하여 가져온다.
각 구절에 대하여 $C$가 추가적으로 이 구절이 연관이 있는지 아닌지를 판단하고 ISREL을 예측한다.
그 다음 $C$는 이 구절이 모델의 생성에 지원이 되는 구절인지를 판단하고 ISUP을 예측한다.
Critique 토큰인 ISREL과 ISSUP은 검색된 구절이나 생성의 뒤에 추가된다.
마지막으로 출력 $y$의 뒤에 $C$가 전체적인 유용성의 토큰인 ISUSE를 예측하고 덧붙인다.
Augmented output with reflection tokens과 오리지널 입력 페어는 $D_\text{gen}$에 추가된다.
아래 Figure 2에 자세한 생성 과정이 나와있다.

Generator learning
Generator model $M$은 curated corpus augmented with reflection tokens $D_\text{gen}$에 대해 학습한다.
목적함수는 standard next token objective다.
$ \underset{M}{max} \mathbb{E}_{((x, y), r) \sim D_\text{gen}} \text{log} \, p_M(y, r | x) $
3.3 Self-RAG Inference
Self-RAG의 추론 과정은 다음과 같다.
Adaptive retrieval with threshold
우선 아래 A. 3의 내용처럼 특정한 임계점 이상인 경우에만 검색을 수행한다.

Tree-decoding with critique tokens
검색이 필요하다면 각각의 segment step $t$에 검색기 $R$은 K개의 구절을 가져오고, 생성기 $M$은 이 구절을 병렬적으로 서로 다른 K개의 continuation candidates 후보를 생성한다.
저자들은 segment-level의 beam search를 통해서 (Beam size = B)해서 top-B segment continuations를 생성하고 생성의 마지막 단계에서는 best sequence만을 반환한다.
각각의 세그먼트 $y_t$에 대한 구절 $d$에 대해서 critic score $S$를 업데이트하고 linear weighted sum of normalized probability of each Critique token type에 대해 계산한다.
각각의 토큰 그룹 G (e.g., ISREL)에 대해서 timestamp를 찍고 이를 토대로 아래와 같이 세그먼트 점수를 계산한다.
$f(y_t, d, \text{Critique}) = p(y_t | x, d, y_{< t}) + S(\text{Critique})$
where $ S(\text{Critique}) = \sum_{G \in \mathcal{G} w^{G} s_t^{G}}$
for $\mathcal{G}$ = {ISREL, ISSUP, ISUESE}
where $s_t^{G} = \frac{ p_t^{\hat{r}} }{ \sum_{i = 1}^{N^G} p_t (r_i) }$다.
4. Experiements

Short-form 형태의 PopQA, TQA, Closed-set 형태의 Pub, ARC, 그리고
Long-form generations with citations 태스크인 Bio와 ASQA에 대해서 Self-RAG가 대체로 가장 좋은 성능을 달성했음을 보인다.
Appendix
Self-RAG에서 사용한 instruction, training examples, outputs examples, human evaluation을 덧붙이며 마무리한다.
Instruction and Demonstrations for determining Retrieve
Retrive를 해야하는지 아닌지에 대한 instruction의 프롬프트는 아래 Table 8에 나와있다.

Training Examples

Examples of Human Evaluations

Examples of Outputs

References:
https://digitalbourgeois.tistory.com/476
'NLP > RAG' 카테고리의 다른 글
| Enhancing RAG performance with smart chunking strategies (0) | 2025.05.10 |
|---|---|
| TAG (2024) 논문 리뷰 (1) | 2025.04.27 |
| Self-RAG, RAGAS 그리고 RAG Evaluation by LLM (0) | 2025.04.02 |
| RAGAS의 metric별 required columns (0) | 2025.03.28 |
| RAG에서의 평가 지표 (0) | 2025.03.26 |


