TAG 방법론의 논문 제목은 Text2SQL is Not Enough: Unifying AI and Databases with TAG다. (링크)
저자는 Asim Biswal, Liana Patel, Siddarth Jha, Amog Kamsetty, Shu Liu, Joseph E. Gonzalez, Carlos Guestrin, Matei Zaharia다.
Github: 링크
SQL과 RDB의 테이블 형식의 데이터를 어떻게 잘 retrieve할까에 대한 논문이다.
Abstract
데이터베이스에서 자연어 질문을 처리하는 AI 시스템은 엄청난 가치를 창출하리라고 기대된다. 사용자는 언어모델 (LM) 의 강력한 추론 및 지식 기능과 데이터 관리 시스템의 확장 가능한 연산 능력을 동시에 활용할 수 있다. 이러한 결합된 기능을 통해 사용자는 커스텀 데이터 소스에 대해 임의의 자연어 질문을 할 수 있다. 하지만 기존의 방법과 벤치마크는 이러한 환경을 충분히 탐구하지 못했다. Text2SQL method는 relational algebra로 표현될 수 있는 자연어 질문에만 초점을 맞추며, 이는 실제 사용자가 묻고 싶어 하는 질문의 일부에 불과하다. 마찬가지로 RAG는 데이터베이스 안에 있는 하나 또는 소수의 데이터 레코드에 대한 point lookups를 통해 답변할 수 있는 제한된 쿼리의 하위 집합을 고려한다. 본 연구에서는 데이터베이스에서 자연어 질문에 답변하기 위한 통합적이고 범용적인 패러다임인 Table-Autmented Generation (TAG)을 제안한다. TAG는 이전에 연구되지 않았던 table augmented genearation (LM)과 DB 간의 광범위한 상호작용을 나타내며, world knowledge and reasoning capabilities 세계 지식 및 추론 기능을 활용할 수 있는 연구를 제공한다. 저자들은 TAG 문제를 위해서 체계적인 벤치마크를 개발하였으며 표준적인 방법으로는 20% 이하의 쿼리 정확도를 보인다.
1. Introduction
실제 비즈니스 사용자의 질문은 domain knowledge 도메인 지식, world knowledge 세계 지식, exact computaion 정확한 계산, 그리고 semantic reasoning 의미 추론의 정교한 조합을 요구하는 경우가 많다는 사실을 발견했다. DB는 저장된 최신 데이터와 대규모의 정확한 계산 (LM은 이 부분에서 취약합니다)을 통해 도메인 지식의 원천을 명확하게 제공한다.
언어모델은 두 가지 핵심적인 방식으로 데이터베이스의 기존 기능을 확장한다. 첫째로 LM은 자연어 사용자 쿼리의 핵심 요소인 텍스트 데이터에 대한 의미 추론 기능을 보유하고 있다. 둘째로 LM은 세계 지식을 모델 학습 과정에서 배우며 이를 암묵적으로 알고있다. 예를 들어서 "what are the QoQ trends for the "retail" vertical?"라는 질문에 대해서 QoQ (quater over quarter) trend는 전분기 대비 추세를 의미하며, retail은 소매 업종을 의미하기 때문에 이에 대한 사전 세계 지식을 알고 있어야 답변을 할 수 있기 때문이다.
기존의 Text2SQL이나 RAG는 유용하지만 다음과 같은 문제점을 가지고 있다.
Text2SQL 방법들은 직접적인 relational equivalents 관계형 대응 관계를 갖는 자연어 쿼리의 subset 하위 집합에는 적합하지만, 의미 추론이나 세계 지식이 필요한 광범위한 사용자 쿼리는 처리할 수 없다.
예를 들어, 어떤 고객 리뷰가 긍정적인지 묻는 사용자의 쿼리는 각 리뷰를 긍정적 또는 부정적으로 분류하기 위해 리뷰에 대한 논리적 행 단위 LM 추론이 필요할 수 있다.
반면에 RAG는 point lookups로 응답 가능한 쿼리의 하위 집합만을 처리하며 데이터베이스의 풍부한 쿼리를 제대로 사용하지 못한다. 또한 LM은 계산에서 오류가 발생하기 쉽고 계산 작업 효율이 낮을 뿐만 아니라, 긴 컨텍스트 프롬프트에서 성능이 저하된다.
따라서 저자들은 Table-Autmented Generation (TAG)을 대신 제안한다.
아래 Figure 1은 TAG의 핵심 구조를 보여준다.

Query Synthsis: syn(R) → Q
Query Execution: exec(Q) → T
Answer Generation: gen(R, T) → A
Query Synthesis에서는 사용자의 요청 R을 실행 가능한 데이터베이스 쿼리 Q로 만든다.
Query Execution에서는 Q를 실행해서 데이터 T를 생성한다.
Answer Generation에서는 R과 T를 가지고 A를 생성한다.
3. TAG Design Space
Query Types:
(a) level of data aggregation가 필요한 단순한 point queries로 몇개의 행과 열을 보는 쿼리와
(b) the knowledge and capabilites가 필요한 summarization이나 ranking-based question 등의 복잡한 aggregation 집계 쿼리를 모두 지원한다.
Data Model
본 논문에서는 관계형 DB에 대해서 구현했다.
4. Evaluation
Dataset
BIRD에서 5가지 도메인을 선정했다.
california_schools, debit_card_specializing, formula_1, codebase_community, and european_football_2를 선정했다.
Queries
match-based, comparison, ranking, and aggregation queries를 선택했다.
Evaluation metrics
Match-based, comparison, ranking queries에 대해서는 exact matches 퍼센티지 기반의 accuracy를,
aggretation quries에 대해서는 qualitative analysis 정성적 분석을 수행했다.
Experimental setup
LLama-3.1 model의 70B를 이용해서 Text2SQL과 최종 생성에 이용했다.
SQLite3와 E5 base embedding model을 RAG의 베이스라인으로 삼았으며,
LLama-3.1-70B-Instruct를 vLLM과 함께 8개의 A100 80GB GPUs로 실행했다.
Baselines
- Text2SQL
- RAG with FAISS
- Retrieval + LM Rank (STaRK)
- Text2SQL + LM
- Hand-written TAG
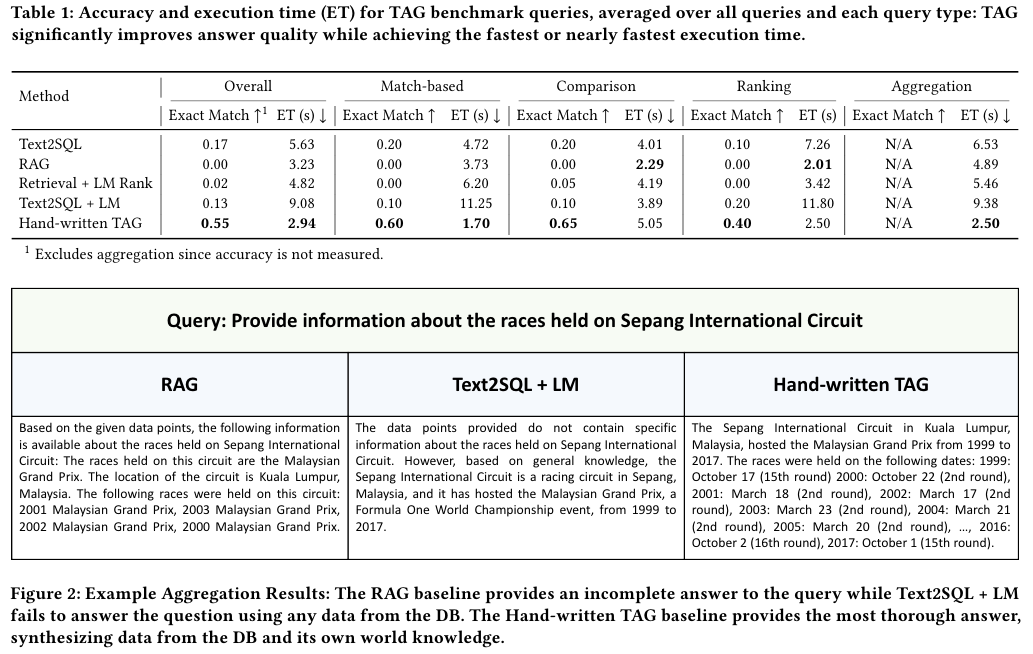
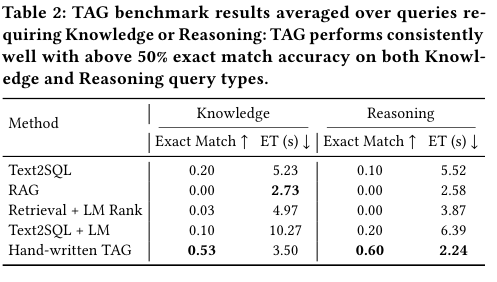
손으로 쓴 TAG가 대체로 가장 좋은 성능임을 알 수 있다.
여담
기본적으로 Text2SQL에 대한 생성은 few-shot instruction으로 수행하는 듯 하다.
그외에도 다양한 방법을 모아놓은 글 (링크)가 있으니 참조하면 좋을듯하다.
References:
https://smartmind.team/en/news/overcoming-llm-limitations-through-thanosql-using-tag/
https://devocean.sk.com/blog/techBoardDetail.do?ID=166859&boardType=techBlog
'NLP > RAG' 카테고리의 다른 글
| Enhancing RAG performance with smart chunking strategies (0) | 2025.05.10 |
|---|---|
| Self-RAG (2023) 논문 리뷰 (0) | 2025.04.17 |
| Self-RAG, RAGAS 그리고 RAG Evaluation by LLM (0) | 2025.04.02 |
| RAGAS의 metric별 required columns (0) | 2025.03.28 |
| RAG에서의 평가 지표 (0) | 2025.03.26 |


