Self-Instruct의 논문 이름은 Self-Instruct: Aligning Language Models with Self-Generated Instructions다. (링크)
저자는 Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi다.
Github: 링크
사람이 생성한 레퍼런스 instructions을 기반으로 LLM을 통해서 instructions를 생성하고 파인 튜닝에 사용한 논문이다.
Abstract
Instruction-tuned LLM은 새로운 태스크에 대한 zero-shot 성능에서 놀라운 성능을 보였다. 하지만 이는 사람이 작성한 instruction 지시에 의존하기 때문에 그 양과 다양성, 독창성에 있ㅇ어서 한계가 있고 이는 모델의 일반화에 한계점이 있다.
본 논문에서는 Self-intsrtuct 방법을 통해서 instruction-following 성능의 역량을 향상시킨다. 우리의 파이프라인은 instructions, inputt, output samples를 LLM으로 생성한 다음 유효하지 않거나 중복을 제거하고 이를 통하여 원래 모델을 파인 튜닝한다. vanilla GPT-3를 활용하였으며 InstructGPT에 비해서 33%의 향상을 거두었다.

2. Method

Figure 2에 나온대로 4개의 스텝으로 이루어진다.
Step 1: Instruction Generation
Step 2: Classification Taks Identification
Step 3: Instnace Generation
Step 4: Filtering
Step 1: Instruction Generation
175 tasks를 pool로 준비한다 (1 개의 task 마다 1개의 instruction과 1개의 instance를 준비한다.)
매 스텝마다 8개의 instruction을 풀에서 뽑아서 in-context 예시로 사용한다.
이때 8개 중에서 6개는 사람이 작성한 태스크고 나머지 2개는 이전 단계에서 모델이 생성한 태스크로 diversity를 향상시키기 위함이다.
아래 Table 5가 프롬프트 템플릿이다.

Step 2: Classification Taks Identification
Classification 분류와 아닌 작업을 나눈다.
그 이유는 저자들이 few-shot 개념으로 사용할 프롬프트를 12개의 분류 지시와 19개의 분류가 아닌 지시로 나누었기 때문이다.
아래 Table 6가 프롬프트 템플릿이다.

Step 3: Instnace Generation
지시와 태스크 유형이 정해진 상태에서 지시에 맞는 인스턴스를 독립적으로 생성한다.
이는 어려운 일인데 저자들은 인스턴스를 두 가지 유형으로 나눠서 생성한다.
1. Input-first Approach
입력에 기반한 지시를 통해서 그에 해당하는 출력을 생성한다.
아래 Table 7이 Input-first Approach 프롬프트 템플릿이다.
2. Output-first Approach
분류 문제를 위한 방법으로 가능한 클래스 라벨을 먼저 생성한 다음 각 클래스에 해당하는 입력을 생성한다.
아래 Table 8이 Output-first Approach프롬프트 템플릿이다.


Step 4: Filtering and Postprocessing
다양성을 증진시키기 위해서 새로운 지시를 태스크 풀에 넣을 때 ROUGE-L 유사도가 현존하는 지시와 0.7보다 작을 때만 추가한다.
또한 image, picture, graph와 같은 특정 키워드가 있는 경우는 모두 제외했다.
각각의 지시에 대해서 새로운 인스턴스를 생성할 때 똑같은 인스턴스가 존재하거나, 입력이 동일하지만 출력이 다른 경우는 제외했다. Invalid 유효하지 않은 인스턴스는 휴리스틱 방법으로 필터링했다 (너무 짧거나, 너무 길거나, 인스턴스의 출력이 입력의 반복인 경우.)
Finetuning the LM to Follow Instructions
오리지널 LM의 파인튜닝을 위해서 지시, 인스턴스의 입력, 프롬프트, 그리고 인스턴스의 출력을 표준적인 지도학습의 방법으로 학습시켰다. 모델의 robust 강건성을 위해서 다양한 템플릿을 사용했다. 예를 들어서 prefix의 측면에서 Task의 삽입 여부, Input의 삽입 여부, Output이 프롬프트의 끝에 붙을지 말지를 각각 만들었다. 이외에도 break lines의 개수도 다양하게 적용했다.
3. Self-Instruct Data from GPT3
저자들은 가장 큰 GPT3 LM (davinci engien)을 사용했는데 이는 OpenAI의 API로 접근 가능하다.
구체적은 지시, 인스턴스, 그외 관련 데이터는 다음의 Table 1에 나와있다.

Diversity
Berkeley Neural Parser를 활용해서 지시를 파싱했고 root에 가장 근접한 동사와 첫 번째 direct noun object를 추출했다. 총 52,445개의 지시 중에서 26,559개의 지시가 이와 같은 구조를 가졌으며 다른 방법들은 더 복잡합 clauses 절들을 가지고 있었다.
Top 20의 가장 흔한 root verbs와 그들의 top 4 direct noun objects를 Figure 3에 보인다. 이는 전체의 14%를 차지하는데 전체적으로 다양성이 확보되었다고 볼 수 있다.

또한 생성된 지시들과 175개의 시드 지시들 사이의 higest ROUGE-L도 측정했는데 그 결과는 Figure 4에서 보여준다.
Figure 5에서는 지시, 인스턴스 입력, 인스턴스 출력의 길이의 다양성을 보여준다.
아래는 Figure 4와 5다.

Quality
200개의 지시를 뽑아서 지시 마다 1개의 인스턴스를 랜덤하게 뽑았다.
그리고 이를 해당 논문의 저자들이 expert annotator로서 지시에 맞게 인스턴스의 입력과 출력이 올바른지 아닌지를 판단한다.
그 결과는 Table 2에 나와있다.

좋은 예시와 나쁜 예시는 Table 10과 11에 첨부했다.
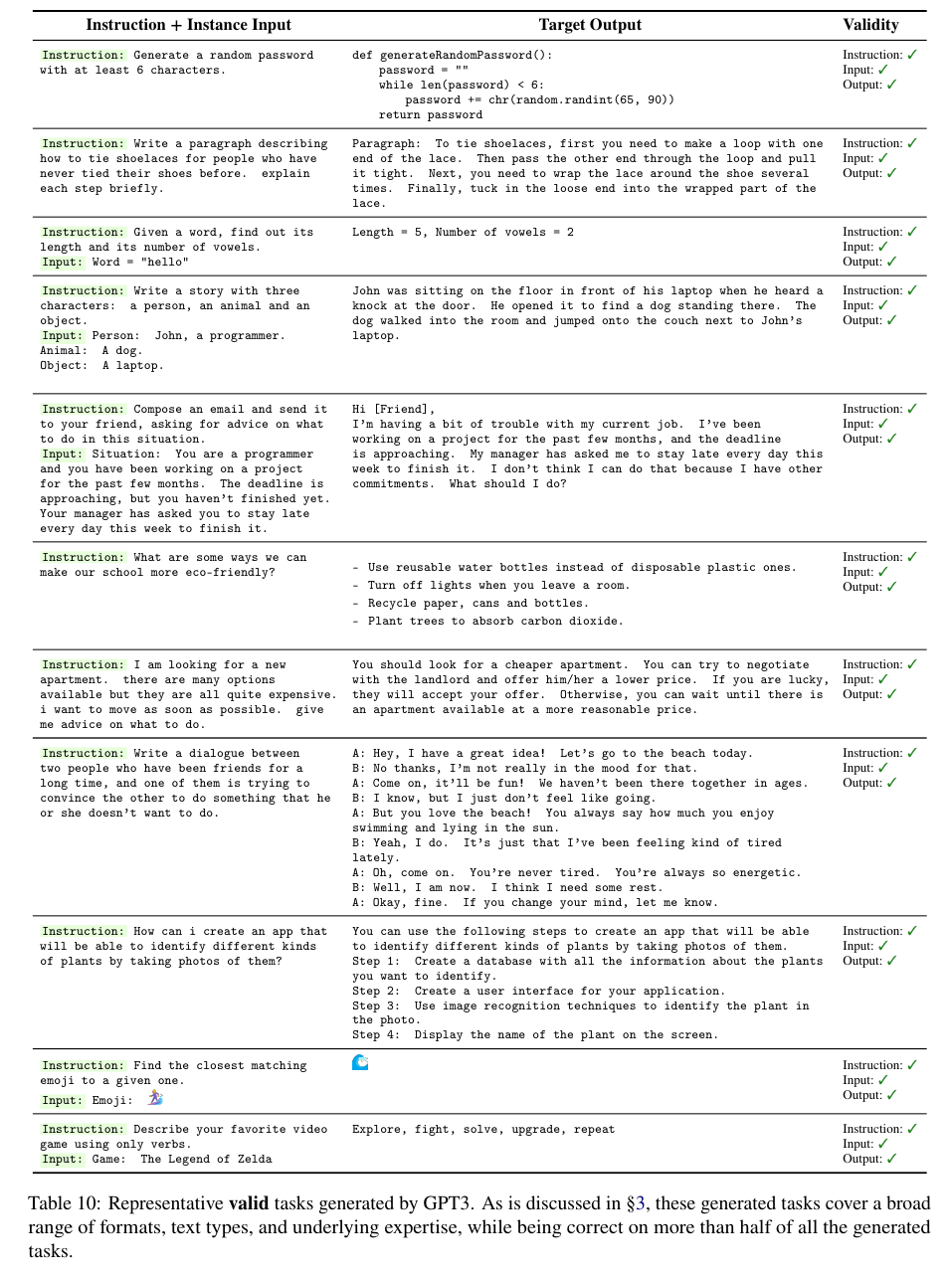

4. Experimental Results
T5-LM, GPT3, T0를 비교 모델로 사용했다.
SUPERNI (119개의 태스크와 개별 태스크 마다 100개의 인스턴스를 가진 데이터),
저자들이 직접 만든 252개의 지시 데이터
Human evluation by normal crowdworkers
위 세 가지 데이터로 비교했다.

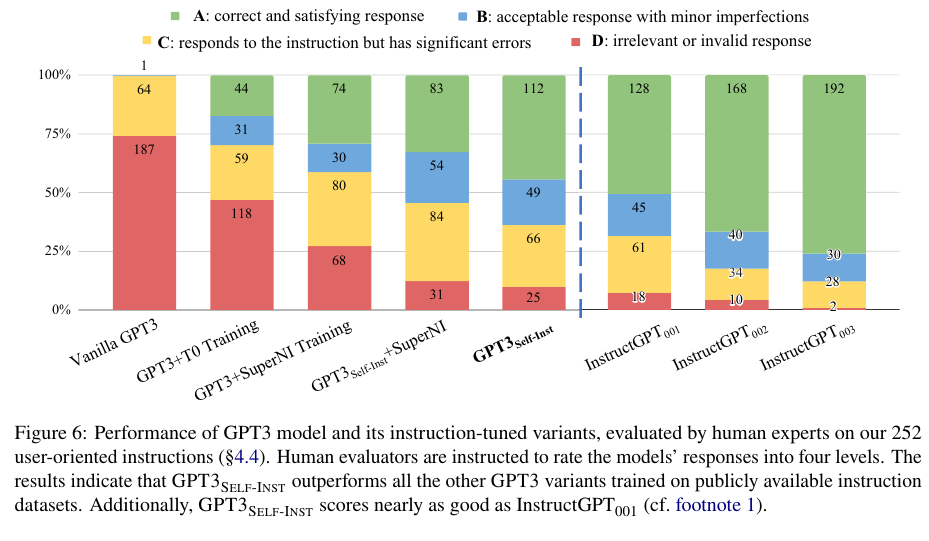
저자들이 제시한 Self-Instruct가 좋은 결과임을 Table 3와 Figure 6에서 보인다.
'NLP > LLM' 카테고리의 다른 글
| Mistral 7B (2023) 논문 리뷰 (0) | 2025.04.27 |
|---|---|
| GPT 4 (2023) 리뷰 (0) | 2025.04.26 |
| LLaMA 2 (2023) 논문 리뷰 (0) | 2025.04.17 |
| Emergent Abilities of Large Language Models (2022) 논문 리뷰 (0) | 2025.04.17 |
| LLaMA (2023) 논문 리뷰 (0) | 2025.04.16 |



