FCOS 모델의 논문 이름은 FCOS: Fully Convolutional One-Stage Object Detection다. (링크)
저자는 Zhi Tian, Chunhua Shen, Hao Chen, Tong He다.
Github: 링크
Anchor free 객체 탐지 방법이다. HRNet에서도 언급되길래 리뷰를 결심하게 되었다.
Abstract
Semantic segmentation과 유사하게 per-pixel prediction 방법으로 fully convolutional one-stage detector (FCOS) 방법을 제안한다. RetinaNet, SSD, YOLOv3와 Faster R-CNN 등 대부분의 SOTA 모델들은 사전에 정의된 anchor boxes 앵커 박스에 의존한다. 본 연구에서는 앵커 박스의 calculating overlapping 중첩 계산과 같은 복잡한 계산을 피한다. 보다 중요한 바는 앵커 박스와 관련된 모든 하이퍼파라미터 세팅을 피할 수 있다는 점이다. 오직 post processing 후처리에 non-maximum supression (NMS)만을 적용함으로써 더 간단한 구조로 one-stage detectors의 성능을 능가하였다. 이때 ResNeXt-64x4d-101 구조를 사용했다.

FCOS에서는 위 Figure 1에 나온 바와 같이 ($l, t, r, b$)의 4D vector를 예측한다.
3. Our Approach

FCOS의 전체적인 구조는 위 Figure 2와 같다. Classification, Center-ness, Regression이 결과로 나온다.
3.1 Fully Convolutional One-State Object Detector
$i$번째 레이어에서 나온 Feature map은 $F_i \in \mathbb{R}^{H \times W \times C}$로 표기한다.
Ground-truth bounding boxes는 {$B_i$}로 정의된다.
$B_i = (x_0^{(i)}, y_0^{(i)}, x_1^{(i)}, y_1^{(i)}, c^{(i)}) \in \mathbb{R}^4 \times \{ 1, 2, ..., C \}$
$c^{(i)}$는 bbox에 있는 객체의 클래스다. 그리고 $C$는 전체 클래스의 개수로 MS-COCO는 총 80개다.
$x_0^{(i)}, y_0^{(i)}$는 left-top 좌표이고 $x_1^{(i)}, y_1^{(i)}$는 right-bottom 좌표다.
Location ($x, y$)가 ground-truth box에 속하면 positive sample이라고 간주하고 이 위치에 속하는 클래스 라벨을 $c^*$로 설정한다.
만약 ground-truth box에 속하지 않는다면 negative sample이고 클래스 라벨을 $c^*$ = 0으로 설정한다.
Classification과 더불어서 다음의 4D real vector $\textbf{t}^* = (l^*, t^*, r^*, b^*)$을 예측하는데 이는 위치를 예측하는 regressor다.
$l^*, t^*, r^*, b^*$는 bbox의 네 가지 측면에 대한 거리다.
Location ($x, y$)에 대해서 위 네 가지 숫자는 아래와 같이 정의된다.
- $l^* = x - x_0^{(i)}$
- $t^* = y - y_0^{(i)}$
- $r^* = x_1^{(i)} - x$
- $b^* = y_1^{(i)} - y$
Network Outputs
$\textbf{p}$는 MS COCO의 경우 80D vector로 클래스에 대한 예측 벡터다.
추가적으로 regression targets는 항상 양수여야 하기 대문에 exponential을 regression branch의 최상단에 위치시킨다.
Loss Function
$L(\{ \textbf{p}_{x, y} \}, \{ \textbf{t}_{x, y} \}) $
= $ \frac{1}{N_{pos}} \sum_{x, y} L_{cls}( \textbf{p}_{x, y}, c_{x, y}^* )$ + $\frac{\lambda}{N_{pos}} \sum_{x, y} \mathbb{I}_{c_{x, y}^* > 0} L_{reg}( \textbf{t}_{x, y}, \textbf{t}_{x, y}^* )$
$\mathbb{I}_{c_{x, y}^* > 0}$는 indicator 함수다.
Inference
location이 $p_{x, y}$ > 0.05면 positive samples로 고른다.
3.2. Multi-level Prediction with FPN for FCOS
BPR은 best possible recall의 약자다.
Stride가 16x과 같이 큰 경우 CNN의 최종 피쳐 맵은 상대적으로 낮은 BPR을 초래할 수 있다.
하지만 FCN을 기반하면 좋은 BPR의 결과를 생성할 수 있다.
FPN 구조를 채택하여 서로 다른 레벨의 피쳐 맵을 활용한다.
P3, P4, P5, P6, P7의 다섯 레벨을 활용한다.
각각은 C3, C4, C5 그리고 1x1 conv를 활용한다.
그리고 각각의 P들의 strides는 P3부터 P7까지 순서대로 각각 8, 16, 32, 64, 128이다.
각각의 피쳐 레벨마다 regression targets의 숫자의 범위를 제한한다.
max($l^*, t^*, r^*, b^*$) > $m_i$이거나 max($l^*, t^*, r^*, b^*$) < $m_{i-1}$이어야 한다.
$m_i$은 maximum distance in feature level $i$다.
$i$는 2, 3, 4, 5, 6, 7의 범위를 가지며, $m_i$는 $m_2$ 부터 $m_7$까지 각각 순서대로 다음의 값을 갖는다.\
0, 62, 128, 256, 512, 그리고 $\infty$다.
대부분의 overlapping은 상당히 크기가 서로 다른 객체 사이에서 발생한다.
Multi-level 예측을 했음에도 ground truth box가 겹치는 경우 더 작은 bbox를 선택한다.
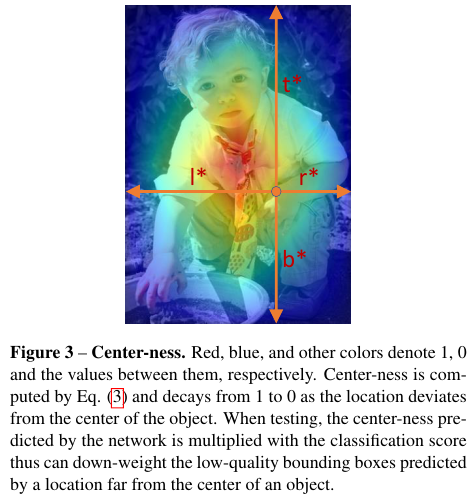
3.3. Center-ness for FCOS
하이퍼파라미터 없이 bbox의 저품질 탐색을 방지하는 방법을 소개한다.
Classification branch와 병렬적인 single layer branch를 추가로 도입한다. 이는 Figure 2에 나와있다.
target regression에 대한 centerness는 다음와 같이 정의한다.
centerness* = $\sqrt{ \frac{min(l^*, r^*)}{ max(l^*, r^*) } \times \frac{min(t^*, b^*)}{ max(t^*, b^*) } }$
centreness는 0과 1사이의 값을 가지며 binary cross entropy loss (BCE)에 의해서 학습된다.
최종적으로 저품질의 bbox는 최종 NMS 과정에서 높은 확률로 필터링 된다.
Centerness는 아래 Figure 3처럼 표기된다. 1과 0사이의 값을 빨간색과 파란색 사이의 그라데이션으로 표기한다.
4. Experiments
COCO에 대해서 object detection 실험을 수행한다.

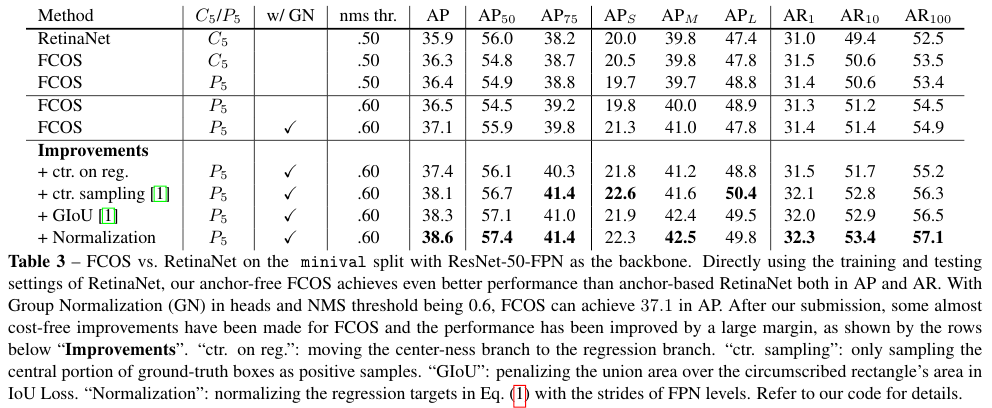

One-stage methods는 물론이고 Two-stage methods와 비교해도 SOTA 결과를 달성함을 확인할 수 있다.
References:
https://blog.si-analytics.ai/72
https://pajamacoder.tistory.com/7
'Computer Vision' 카테고리의 다른 글
| Squeeze-and-Excitation (2018) 논문 리뷰 (0) | 2025.04.28 |
|---|---|
| HRNet (2019) 논문 리뷰 (0) | 2025.04.28 |
| DeepLab V3 (2017) 논문 리뷰 (0) | 2025.04.28 |
| Inception V3 (2015) 논문 리뷰 (0) | 2025.04.28 |
| DETR (2020) 논문 리뷰 (0) | 2025.04.27 |



