BloombergGPT는 금융을 목적으로한 LLM으로 논문 제목은 BloombergGPT: A Large Language Model for Finance다. (링크)
저자는 Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, Gideon Mann다.
Pre-training 부터 직접 학습시킨 LLM으로 50B를 가진 제법 큰 모델이다.
Base 모델로는 Open LLM인 BLOOM (블로그 링크)을 사용했다.
Abstract
금융 기술 영역에서의 NLP 분야의 사용은 방대하고 복잡하다. Sentiment analysis 부터 named entity recognition, question answering까지 포함한다. LLM은 다양한 분야에서 효과적이었지만 금융 분야에 특화된 LLM은 보고되지 않았다. 이 논문에서 저자들은 BloomberGPT, 50 B의 파라미터를 가진 언어 모델을 광범위한 금융 데이터로 363 B 토큰들을 구성하였으며 일반적인 목적의 언어 데이터 345 B와 함께 학습에 사용했다. 자세한 학습 방법은 Appendix C에 첨부했다.
2. Dataset
BloombergGPT를 학습하기 위해서 저자들은 FINPILE을 구축했다. 이는 영어를 기반으로한 news, fillingsm press releases, web-scraped financial documents, and social media drawn from Bloomberg archives를 사용했다. 이는 지난 20년간의 비즈니스 과정에서 얻은 데이터다. (몇몇 저자들이 블룸버그의 직원이다.)
자세한 데이터는 아래 Table 1에 소개되어 있다.
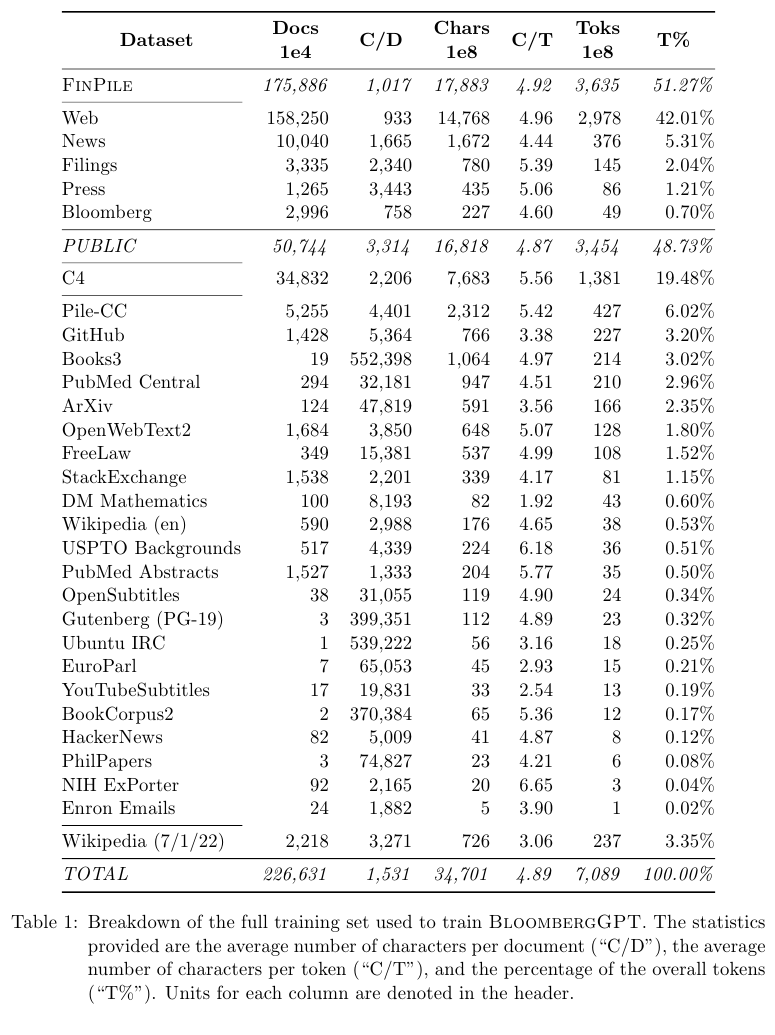
Abstract에서 말했듯이 금융 데이터인 FINPILE 외에도 Pile, C4, ArXiv, BookCorpus, Wikipedia 등 일반적인 언어 데이터도 학습에 사용했다.
금융 데이터는 363 B tokens로 전체 데이터의 51.27%를 차지한다.
웹 데이터는 298 B 토큰으로 42.01%를 차지한다.
Company Fillings는 14 B 토큰으로 2.04%를 차지한다.
Bloomberg의 데이터는 총 5B 토큰으로 0.70%를 차지한다.
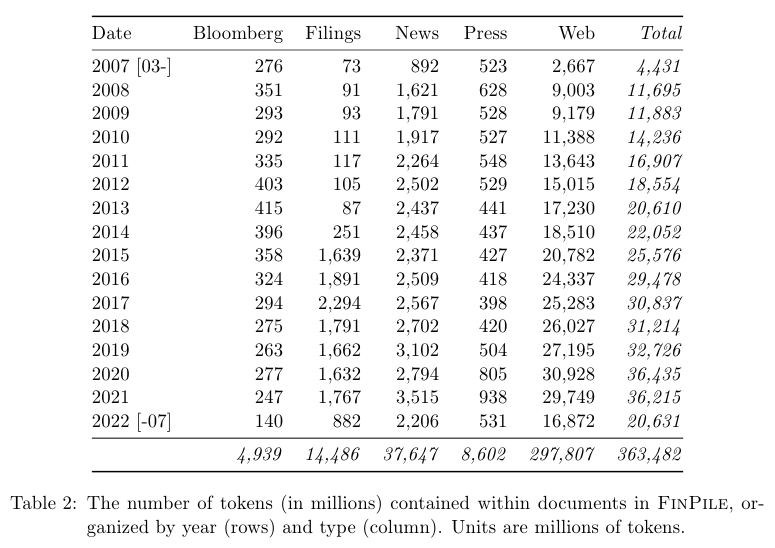
연도별 FINPILE 데이터의 토큰 숫자는 위 Table 2에 나와있다.
Tokenization
Unicode chracter가 아니라 byte 단위의 시퀀스로 데이터를 다룬다. 다음의 regaular expression 정규표현식에 따라서 byte sequence를 청크들로 쪼갠다. 정규표현식: [ A-Za-z]+ | [0-9] | [^A-Za-z0-9]+다.
GPT-2와는 다르게 알파벳 청크 사이의 빈칸 spaces를 포함한다. 이를 통해서 multi-word 토큰을 허용하고 학습할 수 있다.
또한 information density를 증가시키고 context lengths를 줄인다.
그리고 BPE가 아니라 Unigram tokenizer를 사용한다.
Parallel Tokenizer Training
Unigram tokenizing은 계산에 있어서 비효율적이기 때문에 Pile 데이터를 split and merge 방법으로 토크나이징을 수행한다. Pile의 22개 도메인 각각을 256개의 청크로 쪼개서 거의 비슷하게 만든다. Unigram 토크나이저의 vocab size는 65,536 = 2^16이며 총 22 x 256 = 5,632개의 청크에 대해서 토크나이저를 학습한다. 계층적으로 각각의 토크나이저를 합친다. 우선 각각의 도메인별로 256 개의 토크나이저를 합친 다음에, 다시 22개의 토크나이저를 합쳐서 최종 토크나이저를 만든다.
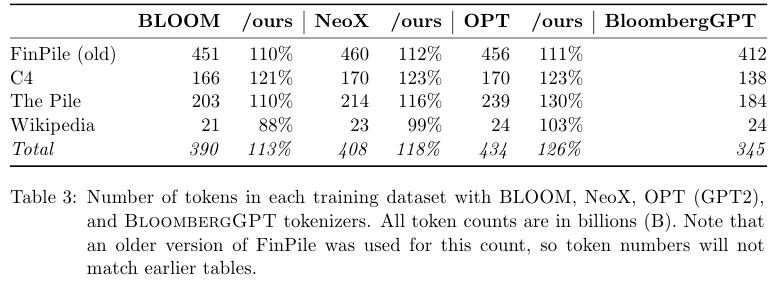
NeoX, OPT, BLOOM과 비교한 토큰의 수는 아래 Table 3에 제시되어 있다.
3. Model
총 70개의 레이어, 40개의 헤드 수, Vocab size는 131,072, Hidden dim은 7680이며 총 파라미터 수는 50.6B다.
Transformer Decoder only 구조이며 LN, Multi-head Self-Attention, FFN, GELU, ALiBi positional embedding을 적용했다.
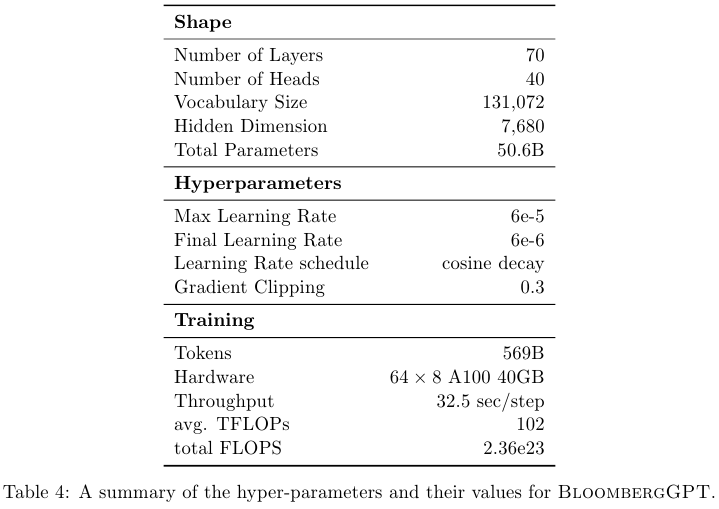
Chinchilla 논문을 따라서 파라미터와 학습 토큰의 수를 결정했다.
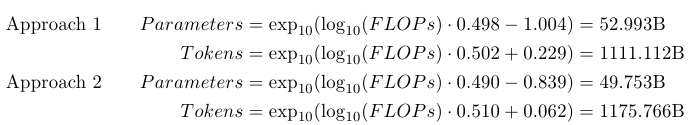
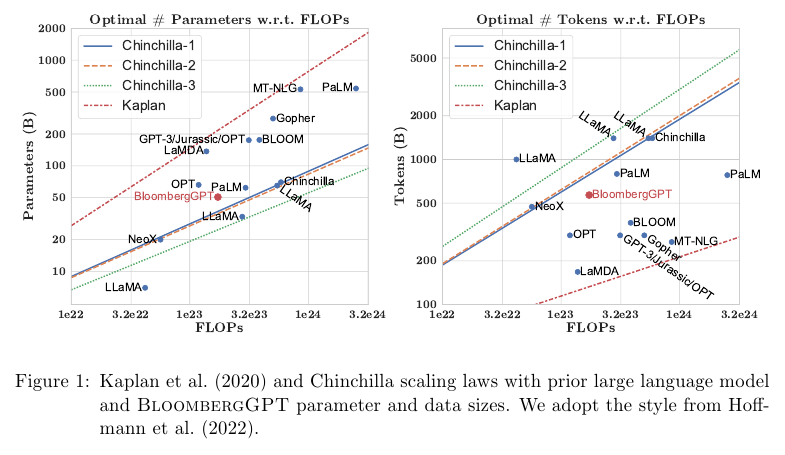
Training
베이스 모델은 오픈 LLM인 BLOOM이다.
PyTorch를 사용해서 표준적인 left-to-right causal language modeling objective를 사용했다.
2048 tokens의 윈도우 사이즈를 가진다.
AdamW optimizer를 사용했으며 $\beta_1 = 0.9, \beta_2 = 0.95$, weight decay는 0.1이다.
최대 학습률은 6e-5이며 consine decay learning rate scheduler를 사용했다.
Warm-up은 liner wramp-up이다. 그리고 warm-up steps는 1800 steps다.
첫 7,200 steps에서는 배치 사이즈는 1024로, 그 다음 부터는 배치 사이즈를 2048로 설정했다.
Training Run
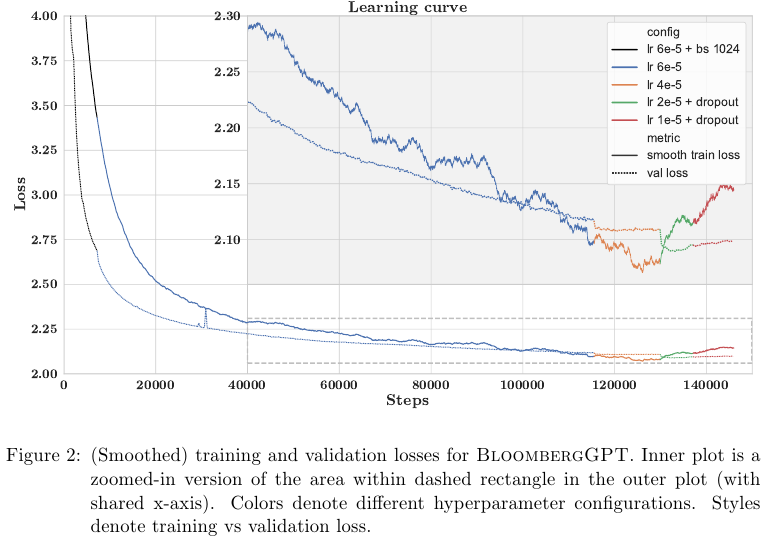
위처럼 자세하게 결과를 보고했는데 구체적인 트레이닝에 대ㅐ서는 이만 생략한다.
5. Evaluation
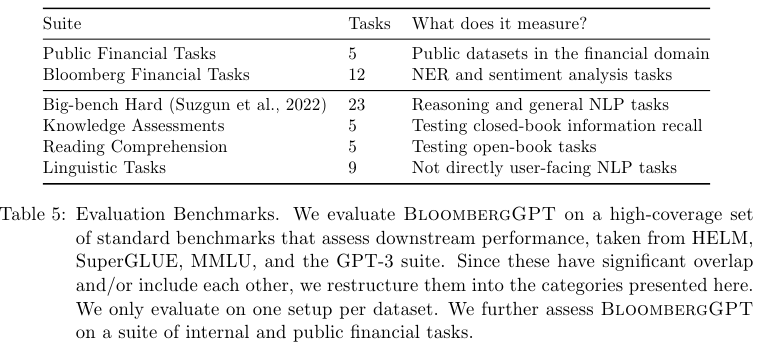
금융 분야 평가
Public Financial Tasks에서는 5개의 태스크
Bloomberg Financial Tasks에서 12개의 태스크
일반 언어 분야 평가
Big-bench Hard 23가지 태스크
Knowledge Assements 5가지 태스크
Reading Comprehension 5가지 태스크
Linguistic Tasks 9가지 태스크
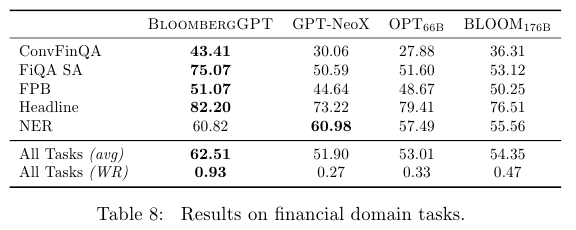
Table 8은 금융 분야에 대한 평가 결과를 보여준다. BloombergGPT의 결과가 베스트임을 알 수 있다.
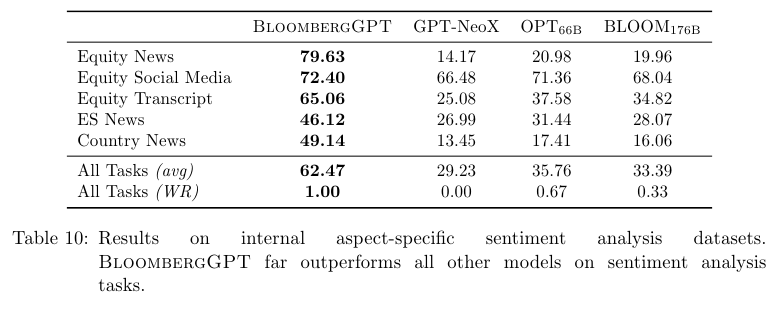
Sentiment analysis에서 BloomberGPT가 가장 좋은 결과를 보여준다.
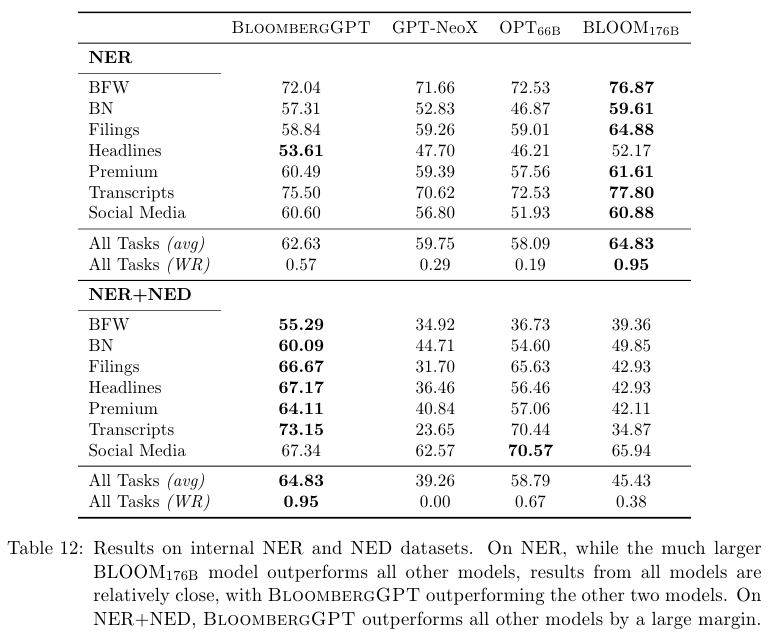
NER에서는 BLOOM이 가장 좋은 결과를 보여준다.
NED (Named entity disambiguation)은 entity 사이의 링크를 의미한다.
이를 활용한 NER + NED 태스크에서는 BloombergGPT가 가장 좋은 결과를 달성했다.
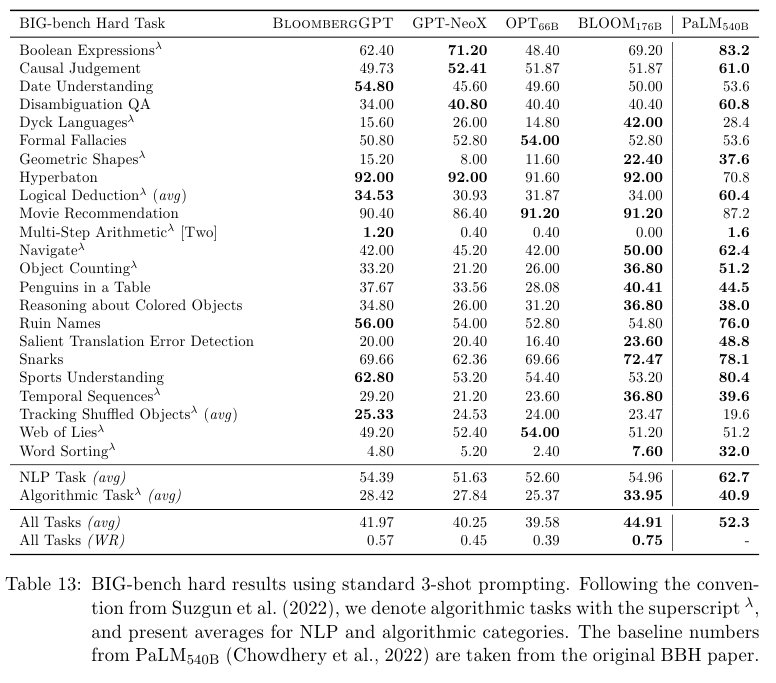
Table 13에서는 23가지 태스크인 BIG-bench의 결과를 보여준다.
몇몇 분야에서 comparable 결과를 보여준다.
이외에도 양이 너무 많아서 다 덧붙이진 않았지만 여러 분야에서 comparable한 결과를 보여준다.
'Time Series > Finance' 카테고리의 다른 글
| 주식 투자에서의 기초적인 Factor 팩터 내용 정리 (0) | 2025.05.05 |
|---|---|
| FinGPT (2023) 논문 리뷰 (0) | 2025.05.02 |
| SEC Fillings를 읽기 위한 회계용어 몇가지 정리 (1) | 2025.05.02 |
| SEC 미국 공시 관련 정보 모음 (0) | 2025.05.02 |
| Modern Portfolio Theory Basics (0) | 2025.04.28 |

