Basics
Session-based recommender systems이란 특정한 시간 구간 동안인 session에 기반한 추천을 의미한다.
Session의 길이에 따라서, 유저의 단기적인, 중기적인, 장기적인 interactions나 선호를 기반으로 하여 추천을 하게 된다.
시간의 개념이 들어가기 때문에 유저가 아이템들과 상호작용한 순서를 고려한 Sequential recommender systems와도 연결된다.
여기서는 간단하게 아래의 논문들을 살펴본다.
- GRU4Rec
- SR-GNN
- SASRec
- Caser
- CL4SRec
- Transformers4Rec
BERT4Rec은 재현성의 문제가 있다고 알고 있어서 제외한다.
Session-based & Sequential Models
GRU4Rec
GRU4Rec의 논문 제목은 Session-based Recommendations with Recurrent Neural Networks다. (링크)
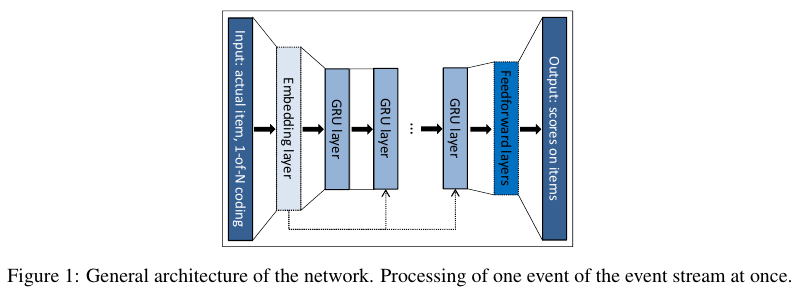
RNN 구조 중에서 GRU를 사용하는 모델이며 그 구조는 아래 Figure 1에 묘사되어 있다.
Session-Parallel Mini-Batches
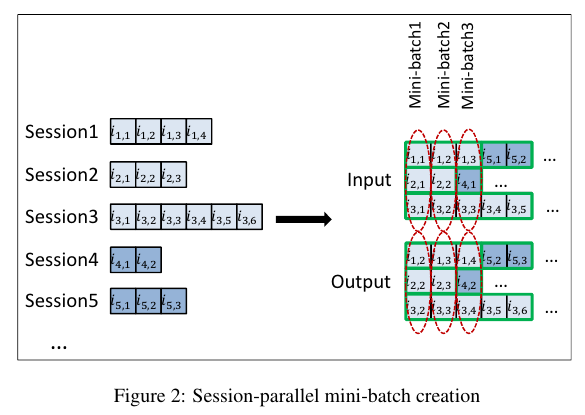
NLP에서는 문장의 단어들을 sliding window에 기반해서 다음 단어를 예측하는데, 이를 기반으로 mini batches를 구성한다. Session 기반 추천의 경우 다음의 2가지를 고려해서 미니 배치를 구성해야 한다. (1) 세션 마다 길이다 다르다. Figure 2를 보면 Session 1의 경우 길이가 4, Session 2에서는 길이가 3, ... 이런식으로 모두 길이가 다르다. (2) 세션이 시간의 흐름에 따라서 어떻게 변화하는지를 파악해야 하기 때문에 단순하게 세션을 쪼개서는 목적을 달성할 수 없다. 따라서 Mini-batch 1은 모든 세션의 첫 번째 이벤트로 구성하고, Mini-batch 2에서는 모든 세션의 두 번째 이벤트로 구성한다. 이때, 각 세션은 모두 독립적이라고 가정한다. 자세한 내용은 위 Figure 2에 그려져있다.
Sampling on the Output
일반적으로 아이템의 수는 굉장히 많기 때문에 몇가지 아이템에 대한 예측만을 수행하는 것이 합리적이다. 이때, 유저가 어떤 아이템에 점수를 매기지 않았다는 사실은 그 유저가 마음에 들지 않아서 상호작용을 하지 않았다 보다는 그 아이템을 모르기 때문에 상호작용을 하지 않았다는 이유가 더 합리적이라고 저자들은 이야기한다. 따라서 인기 있는 아이템들을 토대로 negative samples를 샘플링한다.
Loss로는 BPR에서 사용한 ranking loss를 사용한다.
SR-GNN
SR-GNN의 논문 제목은 Session-based Recommendation with Graph Neural Networks다. (링크)
주어진 session sequence $s$에 대해서 directed graph $\mathcal{G}_s = (\mathcal{V}_s, \mathcal{E}_s) $로 표시한다.
Item은 $v_{s, i} \in V$로 표기하고, Edge는 $(v_{s, i - 1}, v_{s, i}) \in \mathcal{E}_s$로 표기하는데 이는 곧 유저가 세션 $s$에서 아이템 $v_{s, i}$을 $v_{s, i - 1}$을 본 다음에 클릭했다는 뜻이다. Item 노드를 $v$로 표기하고, 그 임베딩 벡터는 $\text{v}$로 표기한다.
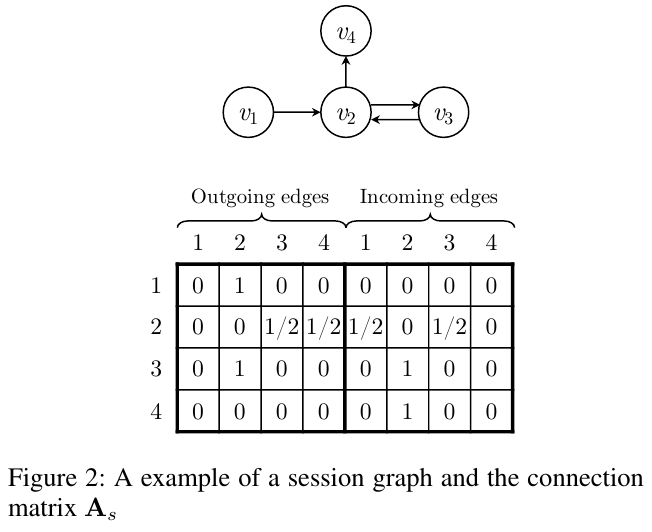
SR-GNN에서는 일반적인 adjacency matrix가 아니라, outgoing edges와 incoming edges를 따로 분류해서 두 개의 adjacency matrices를 concat한 session $s$의 connection matrix $A_s$를 사용한다.
The Graph Neural Network Model 논문 (링크)와 Gated Graph Sequence Neural Networks 논문 (링크)에서 참고해서 다음의 Equation (1) ~ (5)를 제시한다. 식을 보면 알겠지만 GRU 구조다.

$\sigma$는 sigmoid function이고 $\odot$은 elemnt-wise multiplication 연산이다.
Session Embeddings
여기서는 세션 $s$에 대한 임베딩을 설정한다. 이때 s의 길이는 $n$이다.
Local embedding은 가장 마지막에 클릭한 아이템의 embedding인 $\text{v}_n$으로 설정한다.
따라서 $s$의 local embdding $s_l = \text{v}_n$다.
Global embedding $s_g$는 soft-attention 메커니즘을 사용하여 각각의 아이템들의 임베딩의 weighted sum의 형태로 구성한다.

Local와 Global을 모두 포함한 Hybrid embedidng $s_h$는 $W_3 [ s_l $ ; $s_g ]$로 표기하며, $W_3 \in \mathbb{R}^{d \times 2d}$로 $2d$-dim 벡터를 $d$-dim 벡터로 변환한다.
최종 예측은 다음 과정을 통해서 도출한다.
$\hat{\text{z}}_i = s_h^\top \text{v}_ni$
$\hat{\text{y}} =$ softmax( $\hat{\text{z}} $ )
이때 $\hat{\text{z}}_i $는 전체 candidate items 중에서 아이템 $i$에 대한 score고, $\hat{\text{y}}_i $는 세션 $s$에서 다음번에 여러가지 노드들이 유저에 의해서 클릭될 확률들이다.
Loss 함수는 Cross Entropy다.
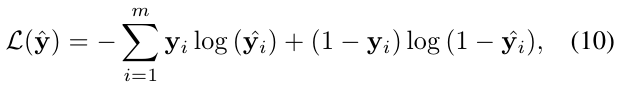
SASRec
SASRec 논문 제목은 Self-Attentive Sequential Recommendation다. (링크)
Transformer의 Self-Attention 구조를 사용한 논문이다.

Figure 1에서 알 수 있듯이 Self-Attention (SA)으로 session 내에서의 관계를 sequence-aware하게 학습하고, point-wise feed forward network (FFN)로 SA에서 학습된 내용을 추가적으로 학습한다.
Session $s$에서 현재 시점 $i$ 이후의 값들을 참조하지 않고, Residual connection, Layer Normalization, Dropout을 사용하며, LM Head와 Embedding이 sharing 되는 것과 동일한 구조를 채택했다.
사실상 NLP 분야의 GPT와 같은 decoder only 구조를 지닌다고 볼 수 있다.
Caser
Caser 논문의 이름은 Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding다. (링크)
Transformer의 구조를 따르는 논문들과 다르게 Convolution, 그 중에서도 1D Conv를 사용한다.
자세한 모델의 구조는 아래 Figure 3와 같다.
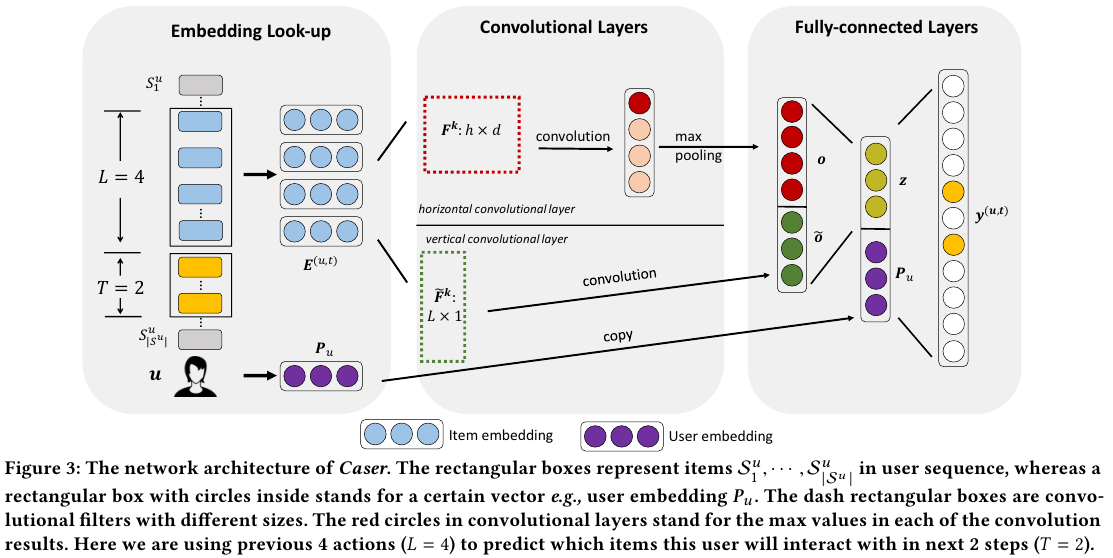
1D Convolution은 Yoon Kim의 논문인 Convolutional Neural Networks for Sentence Classification (링크)에서 봤던 기억이 있다. 흔히 알고 있는 2D는 컨볼루션 연산이 좌우의 x축과, 위아래의 y축으로 움직인다면 1D 컨볼루션은 좌우의 x축이나, 위아래의 y축으로만 움직이는 개념이다.
여기서는 Horizontal conv와 Vertical con 2가지의 1D 컨볼루션을 사용한다.
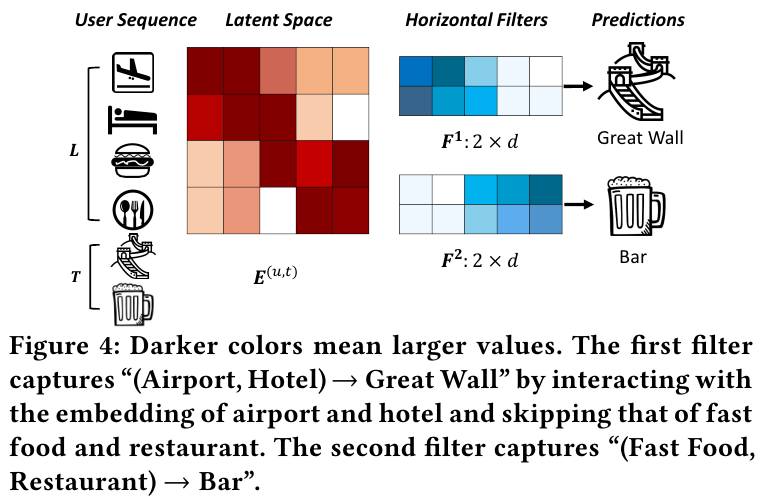
위 Figure 4를 보면 Horizontal conv는 쉽게 이해가 간다.유저의 시퀀스가 $S^u$이고, 그 시퀀스의 길이가 $L$이고, 다음 번의 $T$개의 아이템을 예측하는 상황이다. 이때 필터의 사이즈가 2라면 세션 내에서 2개의 아이템을 위에서 아래의 순서로 학습하게 되는데, 위의 경우 비행기 모양과 숙소 모양을 학습하게 된다. 따라서 그 다음은 여행과 관련된 만리장성을 예측하게 된다. 그 다음 필터에서는 패스트푸드와 식당 2개의 아이템을 학습하므로, 다음 단계에서 이와 관련된 바를 예측하게 된다.
Vertical conv는 Latent space에서 같은 위치에 있는 피쳐를 학습한다. 필터의 사이즈가 2라면, 잠재 공간에서 element를 왼쪽에서 오른쪽으로 학습하게 된다. 공항, 숙소, 패스트푸드, 식당의 각각의 latent vectors의 1번째 피쳐와 2번째 피쳐를 학습하게 된다. 이런 성질 때문에 point-level sequential patterns를 학습하게 된다.
Horizontal conv와 Vertical con를 통해서 학습한 아이템의 피쳐를 Fullcy connected layer (Affine transformation + Activation)을 취해서 아이템에 대한 벡터 $z$를 만들고 이를 유저의 벡터인 $P_u$와 concat해서 다시 FC를 취한 다음 다음 번 $T$ steps에 대한 아이템들을 추천하게 된다.
CL4SRec
CL4SRec 논문 제목은 Contrastive Learning for Sequential Recommendation다. (링크)
Contrastive learning의 개념을 rating or interaction prediction에 추가한 모델이다.
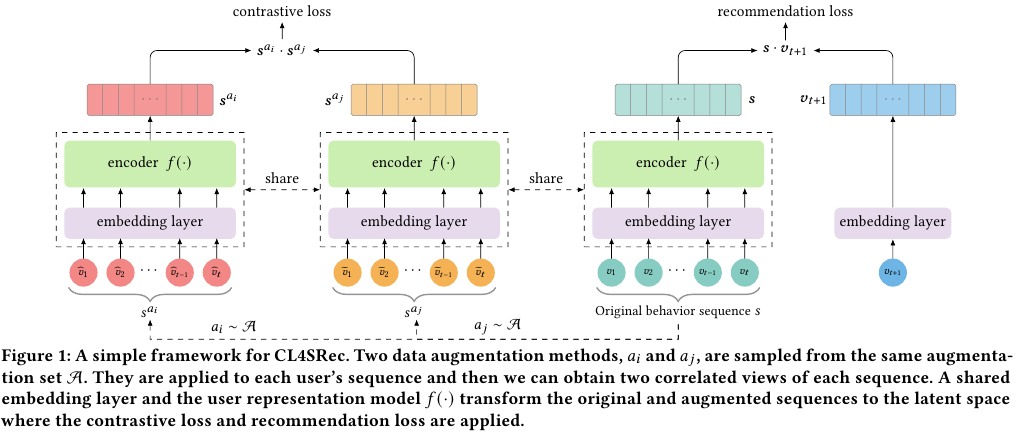
컴퓨터 비전 분야의 SimCLR에 영감을 받아서 더 강력한 user representation을 얻고자 한다.
동일한 원본 세션으로 부터 augemented 증강된 2개의 시퀀스들을 활용해서 contrastive loss를 구하고 이를 최소화한다.
Figure 1의 좌측에 나온 2개의 기둥이 있는 $s^{a_i}$와 $s^{a_j}$이 2개의 서로 다른 증강된 시퀀스를 나타낸다.
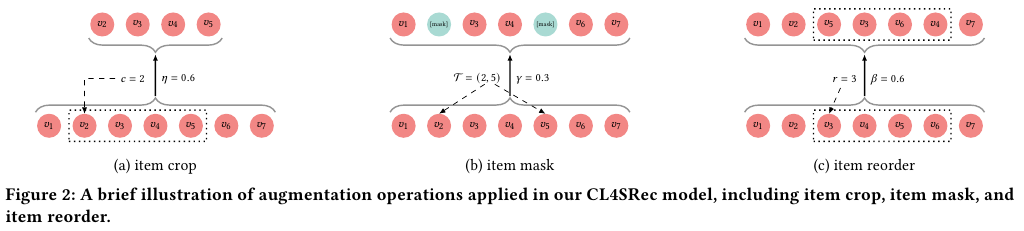
Augmentation 증강의 방법은 위 Figure 2에 묘사된 바와 같이 3가지다.
(a) item crop: 일부 아이템을 제거한다
(b) item mask: 일부 아이템에 마스킹을 취한다
(c) item reorder: 일부 아이템의 순서를 뒤바꾼다.

그외의 모델의 기본적인 구조는 Figure 3에서 제시된 SASRec과 동일하다.
Transformers4Rec
Transformers4Rec 논문 제목은 Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation다. (링크)
Nvidia와 Facebook이 함께 쓴 논문으로 NLP 분야와 추천의 개념을 밀접하게 엮은 논문이다.
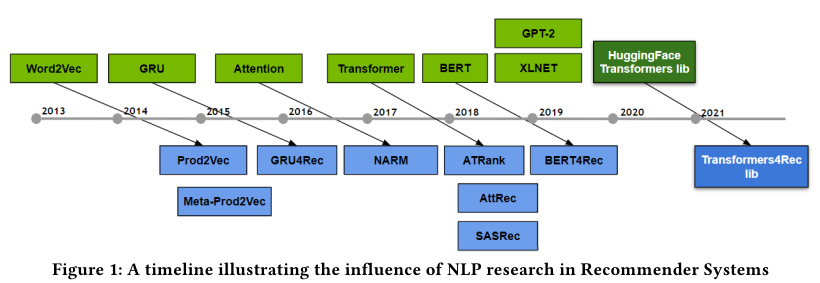


특히 NLP 분야의 모델들과 학습 방법을 추천에도 그대로 적용하여 성능을 비교한게 특징적이다.
모델들
- GPT-2
- Transformer-XL
- BERT
- ELECTRA
- XLNet
모델 학습 방법들
- Causal Language Modeling, CLM
- Masked Language Modeling, MLM
- Permutation Language Modeling, PLM
- Replacement Token Detection, RTD
PLM은 문장 안에 있는 tokens의 순서를 섞는 방식이다.
RTD는 MLM과 유사하지만 mask로 대체하는 대신 다른 가짜 토큰으로 대체한다. 그리고 진짜 토큰인지 대체된 가짜 토큰인지를 분류한다.

여러가지 언어모델들과 STAN 계열 모델들, 그리고 GRU4Rec과도 비교한 결과가 위 Table 2다.
References:
https://developer.nvidia.com/merlin/session-based-recommenders
https://www.linkedin.com/pulse/session-based-recommender-systems-imane-cherifi/
'Recommender Systems' 카테고리의 다른 글
| VBPR (2016) 논문 리뷰 (0) | 2025.06.24 |
|---|---|
| Socio Based Recommender Systems (0) | 2025.06.20 |
| Graph Based Recommender Systems (0) | 2025.06.20 |
| Matrix Factorization Based Recommender Systems (1) | 2025.06.20 |
| 추천 시스템 라이브러리와 데이터 리서치 (3) | 2025.06.19 |



