IR (Information Retrieval) Basics
Information retrieval (정보검색)이란 대규모 정보군으로부터 정보 요구를 충족시키는 비구조적인 속성(일반적으로 텍스트)를 지닌 자료(일반적으로 문헌)을 찾아내는 것이다. 과거에는 경영 관리, 연구 개발, 출판물, 특허, 설계도, 시험 데이터 파일 등 기억 매체에 기록된 대량의 데이터 집단에서 자신이 필요로 하는 특정 정보를 선택하여 신속하게 찾는 형태이었으나, 웹이 활성화되면서 원격지나 분산되어 있는 자료까지 통합하여 검색하는 웹 정보검색 서비스로 발전되고 있다.
데이터는 여러 타입으로 분류할 수 있는데, Structured Data (구조적 자료), Semi-Structured Data (반구조적 자료) , Unstructured Data (비구조적 자료)로 나눌 수 있다. 아래 표를 보면 알기 쉽다.
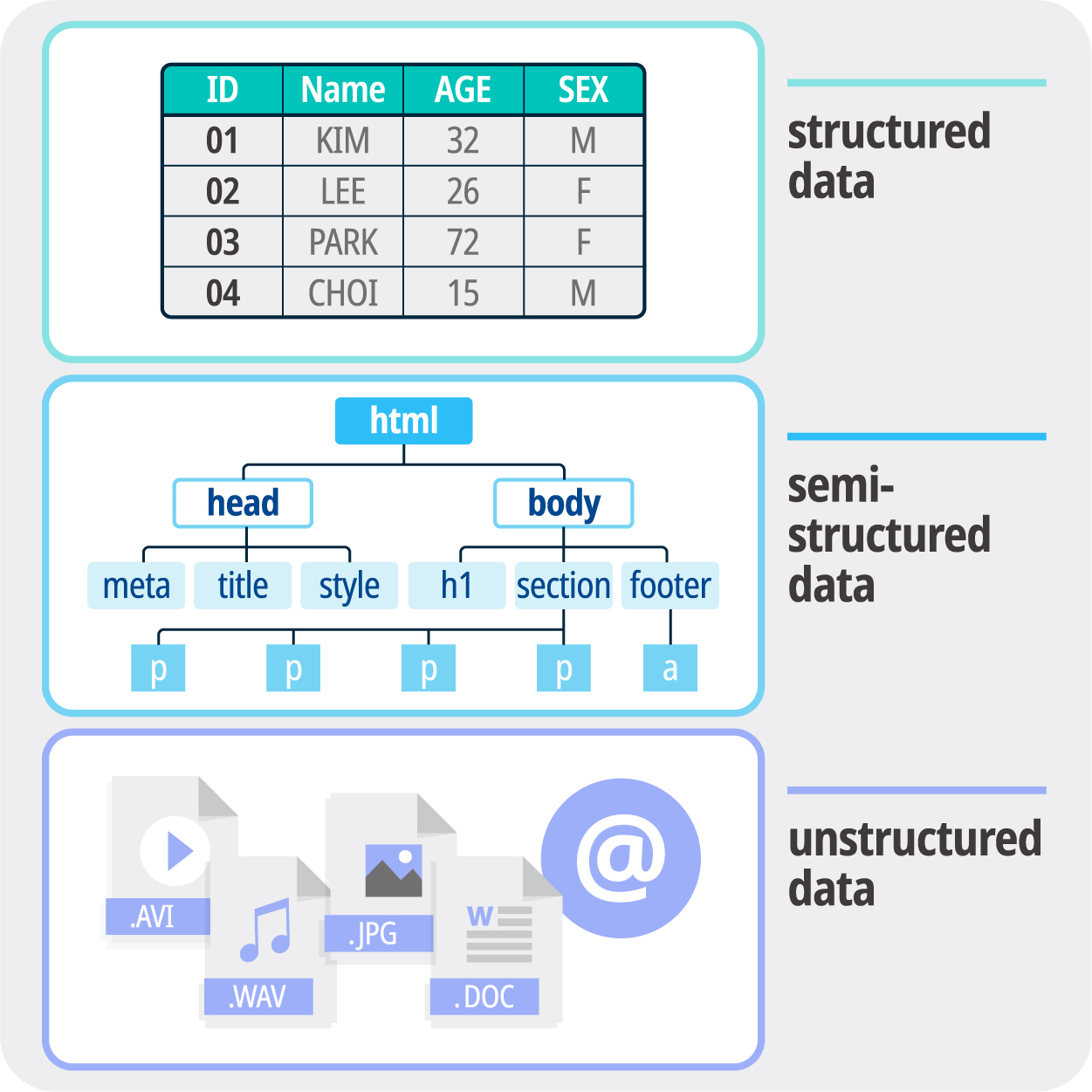
Unstructured Data (비구조적 자료)란 의미적으로 불명확하여 컴퓨터가 이해하기 어려운 자료 형태다. 동영상, 오디오, 텍스트, 이메일 등의 데이터다.
Structured Data (구조적 자료)란 컴퓨터가 이해하기 쉬운 관계형 데이터 베이스 (RDB) 등의 자료 형태다. 엑셀 등의 테이블 형식의 데이터다.
Semi-Structured Data (반구조적 자료)란 데이터의 형식과 구조가 변경될 수 있는 데이터로 데이터의 구조 정보를 데이터와 함께 제공하는 파일 형식의 데이터다. JSON, HTML, XML 등이 이에 속한다.
Explicit Markup (명시적 마크업)은 컴퓨터가 이해하기 쉬운 자료의 구조를 웹페이지에서 나타낸다.
IR (Information Retrieval) Models
1. Boolean Query (불리언 질의)
AND, OR, NOT 등의 연산자를 사용하여 쿼리 용어를 결합하는 부울 논리를 기반으로 한다.
문서는 용어의 집합으로 표현되며, 지정된 조건과 일치하는 문서를 식별하기 위해 쿼리가 처리된다.
정확한 쿼리 일치에는 효과적이지만, 부울 모델은 정확도를 기준으로 문서의 순위를 매기거나 부분 일치를 제공할 수 없다.
현재의 검색 엔진에서는 그렇게 자주 쓰이는 알고리즘은 아니라고 한다.
2. Ranking Models
문서와 쿼리의 관계를 연관성이나 유사도 점수 등을 통해서 도출한다.
Probabilistic models와 Vector Space models가 여기에 속한다.
Boolean search는 랭킹을 사용하지 않는다.
2.1. Probabilistic Models
Binary Independence Model
Language models
Latent Dirichlet allocation
Okapi BM25
Okapi Best Matching 25 모델은 TF-IDF의 변형된 버젼으로 가장 널리 사용되는 랭킹 알고리즘이다.
PageRank
웹페이지의 문서들의 연결 (link)를 기반으로 한 랭킹 알고리즘이다. 클수록 높은 랭크다.
2.2. Vector Space Models
문서와 쿼리를 n-dim vectors로 표현하고 이를 이용하여 쿼리와 유사도를 측정한다.
문서와 쿼리의 n-dim vectors로의 표현을 embedding이라고 하는데 이 임베딩은 다양한 방법들이 존재한다.
TF-IDF, Word2Vec, GloVe를 활용하거나 ELMo나 BERT 등의 딥러닝 NLP 모델을 활용하기도 한다.
TF-IDF (Term Frequency - Inverse Document Frequency)
Term-Frequency는 문서 (document)에 나온 단어 (term)의 개수다. 이때 전체 단어의 수로 나누어 정규화 한다.
Inverse Document Frequency는 Document Frequency의 역수인데, document frequency는 전체 문서 중에서 단어 t가 등장하는 비율이다. 이 수를 뒤집은 수가 IDF다. 이 IDF는 단어가 흔히 등장하지 않다면 정보량이 많다는 데에서 기반한다.
이 TF와 TDF를 곱한 값을 ranking score로 삼는다. 클수록 높은 랭크다.
Relevance Feedback
사용자의 클릭 비율이나 체류 시간 등을 활용한 랭킹 알고리즘이다.
References:
최신정보검색론 (Manning 외 2인)
[업스테이지] AI 실전 학습 - Information Retrieval
Stanford CS276: Information Retrieval and Web Search
https://en.wikipedia.org/wiki/Information_retrieval
http://terms.tta.or.kr/dictionary/dictionaryView.do?word_seq=045850-1
http://terms.tta.or.kr/dictionary/dictionaryView.do?word_seq=175129-2
https://www.elastic.co/kr/what-is/information-retrieval
'Information Retrieval' 카테고리의 다른 글
| Inverted Index Python Implementation - En and Ko (0) | 2024.04.14 |
|---|---|
| Boolean Search, Queries, Index and Inverted Index (0) | 2024.04.14 |
| Information Retrieval and Recommender Systems (0) | 2024.04.09 |


