역색인을 파이썬을 이용해서 구현해본다.
Elasticsearch를 비롯해서 다양한 상업용 라이브러리가 굉장히 효율적인 알고리즘으로 구현해놓았겠지만,
IR을 공부하는 입장에서 직접 구현해볼만한 가치가 있다고 생각해서 간단하게 구현하고 이를 csv와 db 형태로까지 해본다.
영어와 한국어 둘 다 역색인을 파이썬과 sqlite3를 이용해서 db로 간단하게 구현해본다.
영어 역색인 English Inverted Index
import re
import os
import numpy as np
import pandas as pd
import sqlite3
documents = ["'I did enact Julius Caesar I was killed i' the Capitol; Brutus killed me.",
"So let it be with Caesar. The noble Brutus hath told you Caesar was ambitious."]
필요한 라이브러리들을 불러오고 https://arsetstudium.tistory.com/42 에서 공부했던 문장들을 문서로 설정한다.
이제 nltk를 활용하여 형태소 분석을 수행하여 문장을 token 단위로 쪼갠다. 이때 대문자를 소문자로 변경해준다.
import nltk
# nltk.download('punkt') # 필요하면 이 명령어로 다운로드
tokens = []
for idx, d in enumerate(documents):
t = nltk.tokenize.word_tokenize(d)
tokens.append(t)
print(f"Tokenized document {idx}:", t)
>>
Tokenized document 0: ["'", 'I', 'did', 'enact', 'Julius', 'Caesar', 'I', 'was', 'killed', 'i', "'", 'the', 'Capitol', ';', 'Brutus', 'killed', 'me', '.']
Tokenized document 1: ['So', 'let', 'it', 'be', 'with', 'Caesar', '.', 'The', 'noble', 'Brutus', 'hath', 'told', 'you', 'Caesar', 'was', 'ambitious', '.']
# Stopwords 도입해서 불용어 삭제
# nltk.download('stopwords') # 필요하면 이 명령어로 다운로드
from nltk.corpus import stopwords
# remove stop words by stop words list
stops = stopwords.words ('english')
# converts the words in tokens to lower case and then checks whether
#they are present in stop_words or not
filtered_sentence = [w.lower() for w in tokens[0] if not w.lower() in stops]
print("original:",tokens[0])
print("filtered:",filtered_sentence)
>>
original: ["'", 'I', 'did', 'enact', 'Julius', 'Caesar', 'I', 'was', 'killed', 'i', "'", 'the', 'Capitol', ';', 'Brutus', 'killed', 'me', '.']
filtered: ["'", 'enact', 'julius', 'caesar', 'killed', "'", 'capitol', ';', 'brutus', 'killed', '.']
NLTK의 토크나이저와 stopwords를 활용하여 문장을 토큰화하고 불용어를 제거했다.
이때 '이나 . 같은 구두점 (punctuations)가 그대로 남아 있어서 제거해준다.
구두점들은 파이썬의 string 라이브러리에 있는 punctuations를 활용한다.
prin(stops)
>>
['i',
'me',
'my',
'myself',
'we',
'our',
'ours',
'ourselves',
'you',
"you're",
"you've",
"you'll",
"you'd",
'your',
'yours',
'yourself',
'yourselves',
'he',
'him',
'his',
'himself',
'she',
"she's",
'her',
'hers',
...
"weren't",
'won',
"won't",
'wouldn',
"wouldn't"]
# 리스트 형태로 저장되어있다.
import string
string.punctuation
>> '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
for p in string.punctuation:
stops.append(p)
stops
>>
['i',
'me',
'my',
'myself',
'we',
'our',
'ours',
'ourselves',
'you',
"you're",
"you've",
"you'll",
"you'd",
'your',
'yours',
'yourself',
'yourselves',
'he',
'him',
'his',
'himself',
'she',
"she's",
'her',
'hers',
...
'`',
'{',
'|',
'}',
'~']
파이썬 string의 for 문을 활용하여 구두점들을 stops에 넣은 후 출력하여 확인한다.
잘 들어가있는 것을 확인했으므로 다시 불용어를 제거한다.
불용어 제거에 덧붙여서 Stemming을 더한 코드를 구현해본다.
from nltk.stem import PorterStemmer
st = PorterStemmer()
filtered_sentence = [st.stem(w.lower()) for w in tokens[0] if not w.lower() in stops]
print("original:",tokens[0])
print("filtered:",filtered_sentence)
>>
original: ["'", 'I', 'did', 'enact', 'Julius', 'Caesar', 'I', 'was', 'killed', 'i', "'", 'the', 'Capitol', ';', 'Brutus', 'killed', 'me', '.']
filtered: ['enact', 'juliu', 'caesar', 'kill', 'capitol', 'brutu', 'kill']
구두점은 잘 제거가 되었는데, julius와 brutus의 s가 삭제된 상황을 확인할 수 있다.
둘 다 고유명사이므로 이런 현상이 발생하면 안된다.
POS tagging (품사 태깅)을 이용하여 고유명사일 경우 stemming을 수행하지 않도록 코드를 변경한다.
영어에서 인물 고유명사 단수는 NNP고 복수는 NNPS다. 위 두 가지 케이스일 경우 stemming을 제외한다.
filtered_sentence = [st.stem(w.lower()) for w in tokens[0] if not w.lower() in stops]
filtered_sentence = []
sentence = nltk.pos_tag(tokens[0])
for w in sentence:
t, p = w
t = t.lower() # lower로 변경
if p in ("NNP", "NNPS"): #인물 고유 명사인 경우
# 고유명사인 경우 stops에 없을 확률이 높으므로 일단 확인하지 않는다.
filtered_sentence.append(t)
else:
if t not in stops:
filtered_sentence.append(st.stem(t))
print("original:",tokens[0])
print("filtered:",filtered_sentence)
>>
original: ["'", 'I', 'did', 'enact', 'Julius', 'Caesar', 'I', 'was', 'killed', 'i', "'", 'the', 'Capitol', ';', 'Brutus', 'killed', 'me', '.']
filtered: ['enact', 'julius', 'caesar', 'kill', 'capitol', 'brutus', 'kill']
julius와 brutus의 s가 온전히 보존되었음을 확인할 수 있다.
위 작업을 함수화하여 두 가지 문서에 대해서 적용하고 table 형식으로 만든다.
pandas DataFrame으로 테이블화 한다.
# Tokenizatoin, Stemming, Removing Stopwords, and Lower the cases
def preprocess(orig_sentence):
filtered_sentence = []
sentence = nltk.pos_tag(orig_sentence)
for w in sentence:
t, p = w
t = t.lower() # lower로 변경
if p in ("NNP", "NNPS"): #인물 고유 명사인 경우
# 고유명사인 경우 stops에 없을 확률이 높으므로 일단 확인하지 않는다.
filtered_sentence.append(t)
else:
if t not in stops:
filtered_sentence.append(st.stem(t))
return filtered_sentence
terms = []
for token in tokens:
term = preprocess(token)
print(term)
terms.append(term)
def make_table(terms):
term_col = []
doc_col = []
for idx, term in enumerate(terms):
curr_term_col = list(set(term))
term_col.extend(curr_term_col)
doc_col.extend([str(idx+1)]*len(curr_term_col)) # 0이 아닌 1부터 문서 표시
table = pd.DataFrame({"Term": term_col, "Doc": doc_col})
return table
df = make_table(terms)
df
>>
Term Doc
0 brutus 1
1 kill 1
2 caesar 1
3 julius 1
4 capitol 1
5 enact 1
6 let 2
7 brutus 2
8 caesar 2
9 told 2
10 ambiti 2
11 nobl 2
12 hath 2
이제 Term에 대해서 오름차순 정렬을 수행한다.
df = df.sort_values(by=['Term', 'Doc'])
df
>>
Term Doc
10 ambiti 2
0 brutus 1
7 brutus 2
2 caesar 1
8 caesar 2
4 capitol 1
5 enact 1
12 hath 2
3 julius 1
1 kill 1
6 let 2
11 nobl 2
9 told 2
오름차순으로 잘 정렬되었음을 확인했다.
이제는 Term에 대한 document list를 postings list 형태로 만들 차례다.
document list는 유니크한 문서의 값들이 필요하므로 파이썬 리스트 대신 셋을 사용한다.
df.groupby(by='Term').Doc.count()
>>
Term
ambiti 1
brutus 2
caesar 2
capitol 1
enact 1
hath 1
julius 1
kill 1
let 1
nobl 1
told 1
Name: Doc, dtype: int64
# Term이 있는 Doc들을 set으로 설정한다
# 중복 등록을 피할 수 있고 나중에 AND나 OR 비교를 용이하게 하기 위함이다
# AND는 intersection으로, OR은 union으로 수행
df.groupby(by='Term').Doc.apply(set)
Term
ambiti {2}
brutus {1, 2}
caesar {1, 2}
capitol {1}
enact {1}
hath {2}
julius {1}
kill {1}
let {2}
nobl {2}
told {2}
Name: Doc, dtype: object
Postings list가 Term 별로 잘 만들어졌으므로 함수화한 다음 CSV 파일로 저장한다.
def make_dict_postings(table):
dictionary = table.groupby(by='Term').Doc.count().to_frame()
postings_list = table.groupby(by='Term').Doc.apply(set).to_frame()
result = pd.concat((dictionary, postings_list), axis=1)
result.columns = ['Doc Freq', 'Doc list']
result.index.name = 'Term'
return result
inverted_index_table = make_dict_postings(df)
inverted_index_table
Doc Freq Doc list
Term
ambiti 1 {2}
brutus 2 {1, 2}
caesar 2 {1, 2}
capitol 1 {1}
enact 1 {1}
hath 1 {2}
julius 1 {1}
kill 1 {1}
let 1 {2}
nobl 1 {2}
told 1 {2}
# Save as CSV
inverted_index_table.to_csv("en_inverted_index_table.csv", index=False)
SQLite3를 활용하여 DB로 저장
이번에는 SQLite3를 활용해서 db 형태로 저장해본다.
우선 가장 간단한 방법인 to_sql을 사용한다.
그런데 SQL은 Relational DataBase, 즉 테이블 형태로 저장하기에 하나의 cell에 하나의 값만 들어가야 한다.
따라서, string 형태로 길게 postings_list를 넣거나 Term-Document Table 형태로 집어 넣어야 한다.
여기서는 Term-Document Table 형식의 df를 DB에 en_inverted_index_table란 이름의 테이블로 저장한다.
# ir이라는 이름의 DB와 연결
conn = sqlite3.connect("ir.db")
# 커서 설정
cursor = conn.cursor()
# ir DB 안에 en_inverted_index_table이라는 이름의 Table 생성
df.to_sql("en_inverted_index_table", conn, index=False)
# DB와의 연결 종료
conn.close()
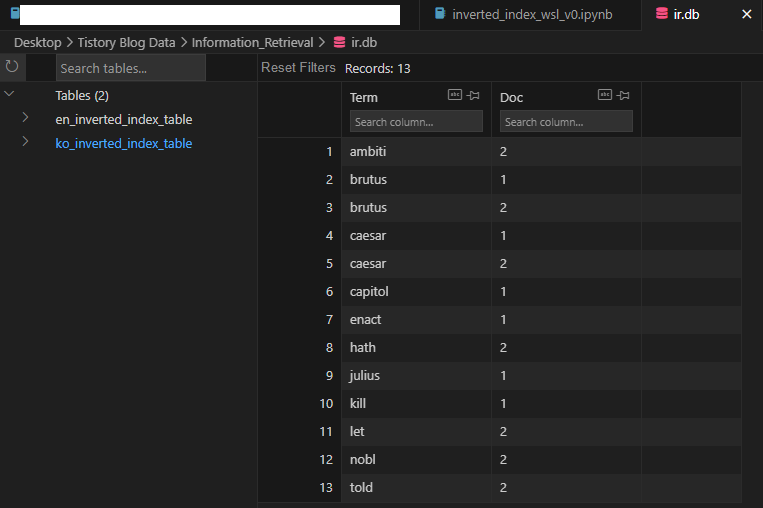
위 명령어를 수행하면 다음과 같이 ir이란 DB에 테이블이 들어가게 된다.
Boolean Search
이번에는 SQL 쿼리문을 통해 간단한 AND Boolean Search를 구현해보았다.
실제로는 RDB 설계나 Prime Key 등등 복잡다난한 문제들이 많겠지만 여기서는 모두 고려하지 않는다.
우선 쿼리를 "Caesar and Brutus"로 설정한다. 이런 유저의 쿼리를 검색에 맞게 전처리를 수행한다.
import nltk
from nltk.corpus import stopwords
# remove stop words by stop words list
stops = stopwords.words ('english')
def preprocess(orig_sentence):
filtered_sentence = []
sentence = nltk.pos_tag(orig_sentence)
for w in sentence:
t, p = w
t = t.lower() # lower로 변경
if p in ("NNP", "NNPS"): #인물 고유 명사인 경우
# 고유명사인 경우 stops에 없을 확률이 높으므로 일단 확인하지 않는다.
filtered_sentence.append(t)
else:
if t not in stops:
filtered_sentence.append(st.stem(t))
return filtered_sentence
query_tokens = preprocess(query_tokens)
query_tokens
>> ['caesar', 'brutus']
이번에는 "en_inverted_index_table"에서 query_token에 해당하는 문서 들을 불러온다.
# ir DB의 en_inverted_index_table의 column data type 확인
conn = sqlite3.connect("ir.db") # DB와 연결
cursor = conn.cursor()
# Table
table_name = "en_inverted_index_table"
answer = []
for query_token in query_tokens:
sql_query = f"""SELECT * FROM {table_name}
WHERE Term = "{query_token}";
"""
# query_token 주위에 ""으로 한번 묶어주어 스트링으로 인식시킨다.
cursor.execute(sql_query) # 실행
curr_answer = cursor.fetchall()
print("Qeury: {0}, and Answer:{1}".format(query_token,curr_answer))
>>
[('caesar', '1'), ('caesar', '2')]
[('brutus', '1'), ('brutus', '2')]
Caesar는 문서 1과 2에서, Burutus도 문서 1과 2에 있으므로 맞게 가져왔다.
정답의 결과는 (Term, Doc)의 형식의 tuple인데 우리는 term은 필요없으므로 Doc만 가져온다.
# ir DB의 en_inverted_index_table의 column data type 확인
conn = sqlite3.connect("ir.db") # DB와 연결
cursor = conn.cursor()
# Create Table
table_name = "en_inverted_index_table"
answer = []
for query_token in query_tokens:
sql_query = f"""SELECT Doc FROM {table_name}
WHERE Term = "{query_token}";
"""
# query_token 주위에 ""으로 한번 묶어주어 스트링으로 인식시킨다.
cursor.execute(sql_query) # 실행
curr_answer = cursor.fetchall()
answer.append(curr_answer )
print("Qeury: {0}, and Answer:{1}".format(query_token,curr_answer))
>>
Qeury: caesar, and Answer:[('1',), ('2',)]
Qeury: brutus, and Answer:[('1',), ('2',)]
답변으로 가져온 튜플을 어떻게 처리해서 파이썬의 리스트나 집합으로 가져올 지 알기 위해서 answer의 내용들을 하나씩 출력하며 알아본다.
answer
>> [[('1',), ('2',)], [('1',), ('2',)]]
answer[0]
>> [('1',), ('2',)]
type(answer[0][0]), answer[0][0]
>>(tuple, ('1',))
answer[0][0][0]
>> '1'
answer안에 2개의 리스트가 있고, 그 리스트의 element는 tuple이다.
원하는 답인 Doc id는 튜플의 첫번째 element이므로 0으로 인덱싱을 하면 가져올 수 있다.
가져온 element들을 집합의 원소로 넣으면 중복되는 것 없는 문서 집합을 만들 수 있다.
이는 아래와 같이 구현할 수 있다.
# 정해진 토큰에 대한 Doc를 SQL에서 가져온다
# 그 다음 해당 리스트를 set으로 변환한다.
def make_answer_set(ans):
result = set([])
for a in ans:
result.add(a[0])
return result
make_answer_set(answer[0])
>> {'1', '2'}
make_answer_set 함수와 SELECT Doc을 포함하여 최종 결과를 도출해본다.
# ir DB의 en_inverted_index_table의 column data type 확인
conn = sqlite3.connect("ir.db") # DB와 연결
cursor = conn.cursor()
# Table Name
table_name = "en_inverted_index_table"
answer = set([])
for query_token in query_tokens:
# en_inverted_index_table란 테이블에서 Doc Column만 가져온다
# 이때 WHERE를 통해서 Term이 우리가 찾고자 하는 Token일 때로 조건을 준다.
sql_query = f"""SELECT Doc FROM {table_name}
WHERE Term = "{query_token}";
"""
# query_token 주위에 ""으로 한번 묶어주어 스트링으로 인식시킨다.
cursor.execute(sql_query) # 실행
curr_answer = cursor.fetchall()
curr_set = make_answer_set(curr_answer)
#print(curr_set)
if not answer:
answer = curr_set
else:
answer = answer.intersection(curr_set)
print("Qeury: {0}, and Answer:{1}".format(query_token,curr_answer))
print(f"Search Result: {len(answer)} Documents, and Documents are {list(answer)}")
>>
Qeury: caesar, and Answer:[('1',), ('2',)]
Qeury: brutus, and Answer:[('1',), ('2',)]
Search Result: 2 Documents, and Documents are ['2', '1']
맨 마지막 줄의 Search Result: 2 Documents, and Documents are ['2', '1'] 를 유저에게 전달해주면 된다.
한국어 역색인 Korean Inverted Index
한국어 역색인의 경우 박효신의 야생화 가사와 대한민국 헌법 1조를 문서로 삼았다.
한국어는 konlpy를 이용하여 토큰화할 수 있다.
다음 두 블로그의 글에 따르면 Komoran과 Mecab이 성능이 괜찮아서 많이 쓰인다고 한다.
따라서 본인도 Mecab와 Komoran 두 개를 선택했다.
https://iostream.tistory.com/144
https://i-am-wendy.tistory.com/27
Mecab은 은전한닢으로 리눅스에서만 작동하는데 WSL2를 활용해서 설치하고 작동시켰다.
Mecab 설치시에 만날 수 있는 오류는 JAVA_HOME의 설정 그리고 아래 블로그를 통해서 해결했다.
WSL Ubuntu 22.04 버젼 자체를 하도 예전에 설치해서 어떻게 JAVA가 설치되었는지는 기억이 나지 않으나,
ls -l /usr/lib/jvm을 통해 확인할 수 있는 java-1.11.0-openjdk-amd64로도 잘 작동함을 확인했다.
SetuptoolsDepreciationWarning: Invalid version: '0.996/ko-0.9.2' 에러의 경우 아래 블로그를 통해 해결이 가능하다.
https://datanavigator.tistory.com/54
이걸 하면서 겸사겸사 update-alternatives도 확인했다.
update-alternatives를 쓰면 cuda도 11.8과 12.1을 번갈아가며 쓸 수 있는 등 굉장히 좋은 툴이라는걸 알았다.
이와 관련된 자세한 사항은 이 링크를 보면 된다.
https://stackoverflow.com/questions/45477133/how-to-change-cuda-version
# 박효신의 야생화 가사와 대한민국 헌법 1조
documents = ["잊혀질 만큼만 괜찮을 만큼만 눈물 머금고 기다린 떨림 끝에 다시 나를 피우리라",
"대한민국은 민주공화국이다. 대한민국의 주권은 국민에게 있고, 모든 권력은 국민으로부터 나온다."]
from konlpy.tag import Komoran
from konlpy.utils import pprint
komoran = Komoran()
pprint(komoran.pos(documents[0]))
>>
[('잊히', 'VV'),
('어', 'EC'),
('지', 'VX'),
('ㄹ', 'ETM'),
('만큼', 'NNB'),
('만', 'JX'),
('괜찮', 'VA'),
('을', 'ETM'),
('만큼', 'NNB'),
('만', 'JX'),
('눈물', 'NNG'),
('머금', 'VV'),
('고', 'EC'),
('기다리', 'VV'),
('ㄴ', 'ETM'),
('떨리', 'VV'),
('ㅁ', 'ETN'),
('끝', 'NNG'),
('에', 'JKB'),
('다시', 'MAG'),
('나', 'NP'),
('를', 'JKO'),
('피우', 'VV'),
('리라', 'EC')]
from konlpy.tag import Mecab
from konlpy.utils import pprint
mecab = Mecab()
pprint(mecab.pos(documents[0]))
>>
[('대한민국', 'NNP'),
('은', 'JX'),
('민주', 'NNG'),
('공화국', 'NNG'),
('이', 'VCP'),
('다', 'EF'),
('.', 'SF'),
('대한민국', 'NNP'),
('의', 'JKG'),
('주권', 'NNG'),
('은', 'JX'),
('국민', 'NNG'),
('에게', 'JKB'),
('있', 'VV'),
('고', 'EC'),
(',', 'SC'),
('모든', 'MM'),
('권력', 'NNG'),
('은', 'JX'),
('국민', 'NNG'),
('으로부터', 'JKB'),
('나온다', 'VV+EF'),
('.', 'SF')]
Mecab은 '잊혀질'을 'VV+EC+VX+ETM'의 복합적으로 PoS(품사)를 반환하고,
Komoran은 '잊혀질'을 '잊히' + '어' + '지' + 'ㄹ'로 분해하고, 각각의 품사를
'VV', 'ECS', 'VXV', 'ETD'로 리턴한다.
'잊혀질'의 단어 뜻을 충분히 포함하고 있도록
분해하는 Komoran이 역색인에는 더 적합하다고 생각해서 Komoran을 선택한다.
이번에는 한국어 불용어 처리인데 nltk처럼 간단한 방법이 없어서 여러가지를 검색해보았다.
https://junior-developer.tistory.com/8
https://ahnsun98.tistory.com/35#google_vignette
https://www.ranks.nl/stopwords/korean
에서 한국어 불용어를 찾을 수 있었는데, https://ahnsun98.tistory.com/35#google_vignette의 stopwords가 좋은듯 싶어서 여기 블로그의 불용어 리스트를 다운 받아서 사용했다.
# 해당 블로그의 불용어를 다운 받고 불러온다
stopwords = []
with open('stopword.txt', 'r') as f:
lines = f.readlines()
for line in lines:
stopwords.append(line.strip())
# 구두점 제거를 위해 불용어에 포함시킨다
import string
for p in string.punctuation:
stopwords.append(p)
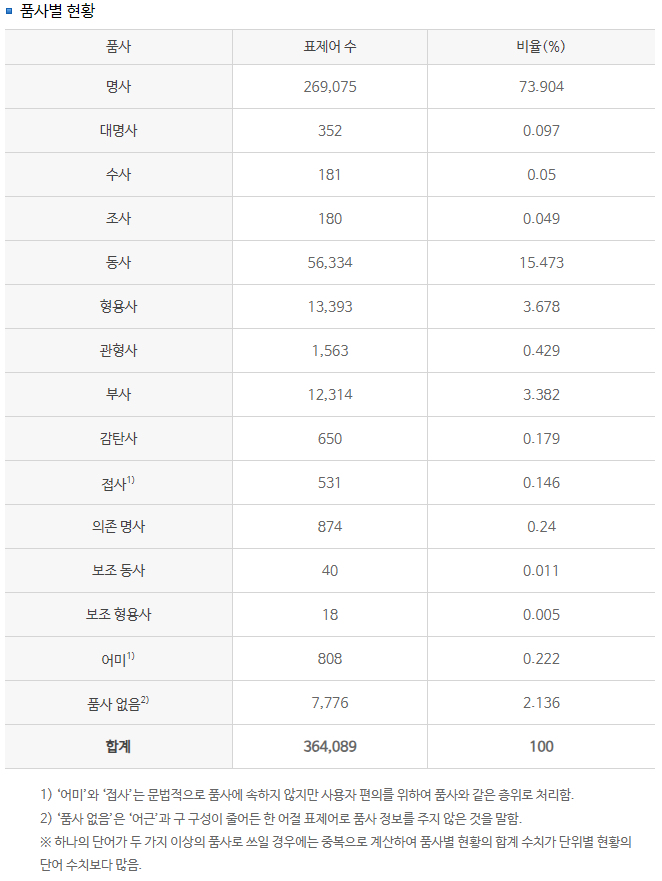
국립국어원 사전통계에 따르면
한국어는 대부분 명사, 동사가 대부분이므로 이 둘을 뽑는다.
추가적으로 내용적으로 유의미한 형용사도 포함한다.
명사와 동사가 약 89%, 형용사까지 합치면 약 92%다.
https://stdict.korean.go.kr/statistic/dicStat.do
위 링크에서 확인할 수 있다.
def preprocess(orig_sentence, tokenizer, stopwords):
filtered_sentence = []
sentence = tokenizer.pos(orig_sentence)
# 일반명사, 고유명사, 동사, 형용사
pos_set = ['NNG', 'NNP', 'VV', 'VA']
for w in sentence:
t, p = w
if p in pos_set:
if t not in stopwords:
filtered_sentence.append(t)
return filtered_sentence
terms = []
for document in documents:
term = preprocess(document, mecab, stopwords)
print(term)
terms.append(term)
>>
['괜찮', '눈물', '머금', '떨림', '끝', '피']
['대한민국', '민주', '공화국', '대한민국', '주권', '국민', '있', '권력', '국민']
for document in documents:
term = preprocess(document, komoran, stopwords)
print(term)
terms.append(term)
>>
['잊히', '괜찮', '눈물', '머금', '기다리', '떨리', '끝', '피우']
['대한민국', '민주공화국', '대한민국', '주권', '국민', '있', '권력', '국민', '나오']
Komoran과 Mecab의 결과를 비교하면 Mecab에서는 잊히, 괜찮, 기다리, 나오 가 사라졌음을 확인할 수 있다.
정보의 손실은 검색 결과에 중대한 영향을 미치리라고 생각하기 때문에, 손실을 최소화하는 코모란을 선택해서 진행한다.
코모란을 통한 토크나이저 후 테이블을 만들고 Term에 대해서 정렬한 결과는 다음과 같다.
df_ko = make_table(terms)
df_ko = df_ko.sort_values(by=['Term', 'Doc'])
df_ko
>>
Term Doc
6 괜찮 1
10 국민 2
12 권력 2
5 기다리 1
7 끝 1
14 나오 2
0 눈물 1
11 대한민국 2
3 떨리 1
2 머금 1
9 민주공화국 2
13 있 2
4 잊히 1
8 주권 2
1 피우 1
이제 postings list를 만들고 CSV로 저장한다.
# Postings_list 만들기
ko_inverted_index_table = make_dict_postings(df_ko)
# CSV로 저장
ko_inverted_index_table.to_csv("ko_inverted_index_table.csv", index=False)
SQLite3를 활용하여 DB로 저장
이번에는 SQL 쿼리문으로 테이블을 생성하고 row별로 저장하는 프로세스다.
실제 작업에서는 이미 만들어져있는 테이블에 저장할 일이 많으리라 예상되므로 의미가 있다고 본다.
사실 Term-Doc Table에 Prime Key (기본 키)는 중복되어 저장되는 Term이 되면 안되지만 실습 삼아서 설정해보았다.
doc id는 NUM으로 설정해도 되지만 그냥 VARCHAR, 가변 string으로 저장했다.
# ir DB의 en_inverted_index_table의 column data type 확인
conn = sqlite3.connect("ir.db") # DB와 연결
cursor = conn.cursor()
# Create Table
table_name = "ko_inverted_index_table"
# Table이 없으면 생성
sql_query = f"""CREATE TABLE IF NOT EXISTS {table_name}
(term VARCHAR(1000) NOT NULL,
doc VARCHAR(1000) NOT NULL,
PRIMARY KEY (term));"""
cursor.execute(sql_query) # 실행
conn.commit() # DB에 반영
# Insert the values to table
for idx, row in df_ko.iterrows():
# Row 마다 실행하고 반영
new_term, new_doc = row
sql_query = f"""
INSERT INTO '{table_name}' (Term, Doc)
VALUES ('{new_term}', '{new_doc}');
"""
cursor.execute(sql_query) # 실행
conn.commit() # DB에 반영
conn.close() # DB 연결 종료
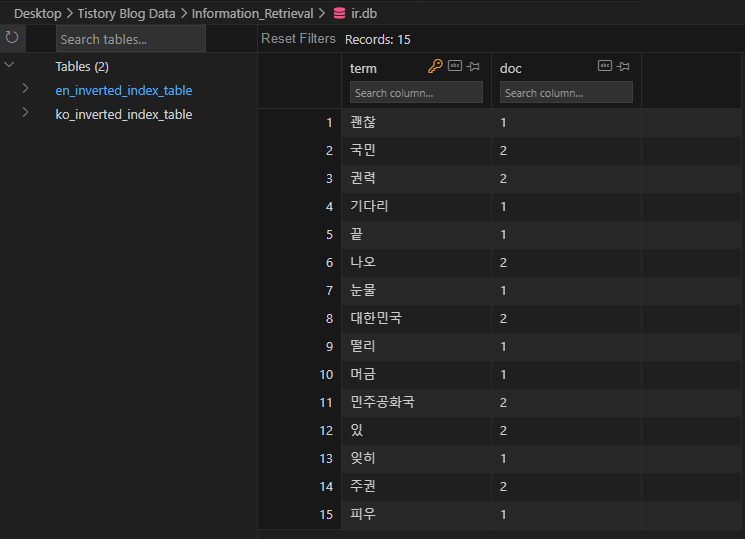
DB에 저장한 결과는 아래와 같다.
References:
https://www.geeksforgeeks.org/removing-stop-words-nltk-python/
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html
https://stackoverflow.com/questions/16601445/how-do-you-add-new-documents-to-an-inverted-index
'Information Retrieval' 카테고리의 다른 글
| Boolean Search, Queries, Index and Inverted Index (0) | 2024.04.14 |
|---|---|
| Information Retrieval and Recommender Systems (0) | 2024.04.09 |
| Information Retrieval 소개 (0) | 2024.04.09 |


