Reddit의 Local LLaMA를 보다가 흥미로운 결과가 있어서 공유한다.
I locally benchmarked 41 open-source LLMs across 19 tasks and ranked them (레딧 링크, Github 링크)
LLM 벤치마크 선정은 해당 깃허브 (링크)를 참조했다고 한다.
해당 프로젝트는 머신 런타임으로는 18일 8시간이 걸렸으며, RTX 5090 GPU 시간으로는 14일 23시간이 걸렸다고 한다.
19가지 벤치마크
19가지 벤치마크는 다시 크게 3가지 범주로 나누었다.
Reasoning & Math, Commonsense & Natural Language Inference, 그리고 Knowledge & Reading이다.
각 범주의 구체적인 항목은 다음과 같다.
Reasoning & Math
Tasks: gsm8k(exact_match,strict-match), bbh(exact_match,get-answer), arc_challenge(acc_norm,none), anli_r1(acc,none), anli_r2(acc,none), anli_r3(acc,none), gpqa_main_zeroshot(acc_norm,none)
Commonsense & Natural Language Inference
Tasks: hellaswag(acc_norm,none), piqa(acc_norm,none), winogrande(acc,none), boolq(acc,none), openbookqa(acc_norm,none), sciq(acc_norm,none), qnli(acc,none)
Knowledge & Reading
Tasks: mmlu(acc,none), nq_open(exact_match,remove_whitespace), drop(f1,none), truthfulqa_mc1(acc,none), truthfulqa_mc2(acc,none), triviaqa(exact_match,remove_whitespace)
Performance of Models on Benchmarks
선택한 모델들은 다음과 같다.
- google_gemma-3-12b-it
- Qwen_Qwen3-14B (8bit)
- openchat_openchat-3.6-8b-20240522
- Qwen_Qwen3-8B
- Qwen_Qwen2.5-7B-Instruct
- Qwen_Qwen2.5-14B-Instruct (8bit)
- 01-ai_Yi-1.5-9B
- Qwen_Qwen2.5-7B-Instruct-1M
- meta-llama_Llama-3.1-8B-Instruct
- 01-ai_Yi-1.5-9B-Chat
- mistralai_Ministral-8B-Instruct-2410
- meta-llama_Meta-Llama-3-8B-Instruct
- Qwen_Qwen3-4B
- NousResearch_Hermes-2-Pro-Mistral-7B
- mistralai_Mistral-7B-Instruct-v0.3
- google_gemma-3-4b-it
- 01-ai_Yi-1.5-6B-Chat
- 01-ai_Yi-1.5-6B
- Qwen_Qwen2-7B-Instruct
- deepseek-ai_DeepSeek-R1-0528-Qwen3-8B
- meta-llama_Llama-3.2-3B-Instruct
- Qwen_Qwen2.5-3B-Instruct
- Qwen_Qwen2.5-Math-7B
- deepseek-ai_deepseek-llm-7b-chat
- deepseek-ai_DeepSeek-R1-Distill-Llama-8B
- meta-llama_Llama-2-13b-hf
- meta-llama_Llama-2-13b-chat-hf
- deepseek-ai_DeepSeek-R1-Distill-Qwen-7B
- Qwen_Qwen2.5-1.5B-Instruct
- Qwen_Qwen3-1.7B
- Qwen_Qwen2.5-Math-7B-Instruct
- meta-llama_Llama-2-7b-chat-hf
- meta-llama_Llama-2-7b-hf
- deepseek-ai_deepseek-llm-7b-base
- deepseek-ai_deepseek-math-7b-rl
- meta-llama_Llama-3.2-1B-Instruct
- google_gemma-3-1b-it
- deepseek-ai_DeepSeek-R1-Distill-Qwen-1.5B
- Qwen_Qwen2.5-Math-1.5B-Instruct
- Qwen_Qwen3-0.6B
- Qwen_Qwen2.5-0.5B-Instruct
Gemma 3, Qwen 2.5, 3이나 Llama 3.2, Mistral, DeepSeek 등의 모델들은 익숙한데 OpenChat, 01.AI, NousResearch 모델은 생소했다.
Overall Rank
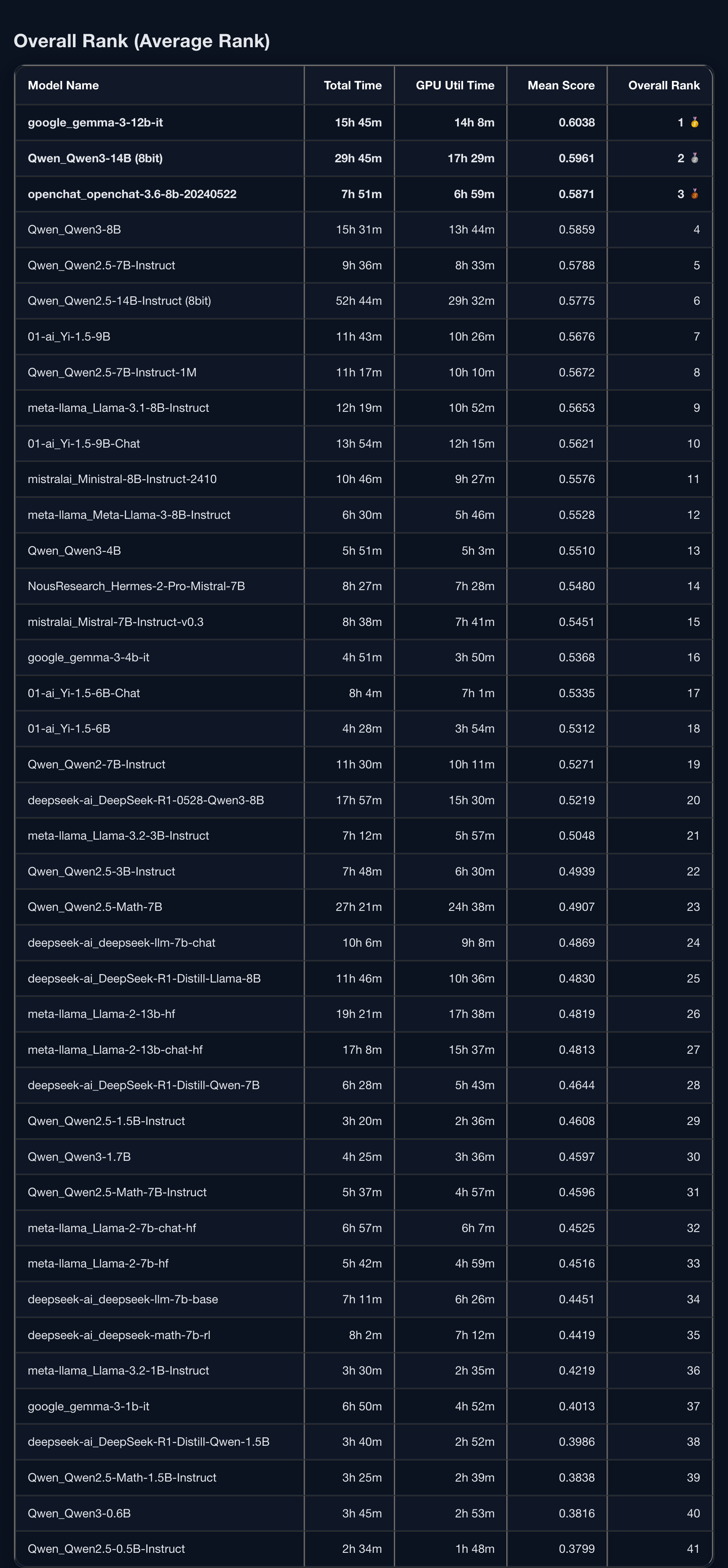
Gemma3 12B나 Qwen3 14B는 좋다고 알음알음 풍문으로 들었는데 OpenChat이나 01.AI의 모델도 제법 성능이 좋게 나온게 흥미롭다.
5B 이하의 모델로는 Qwen3 4B와 Gemma 3 4B IT가 괜찮구나 하고 참고하면 좋을듯하다.
더 작은 모델이 필요하다면 LLaMa 3.2 3B IT와 Qwen 2.5 3B IT를 쓰면 될듯하다.
'NLP > LLM' 카테고리의 다른 글
| 왜 언어 모델이 환각을 일으키는가? (업데이트 예정) (1) | 2025.09.09 |
|---|---|
| LLM의 컨텍스트 윈도우와 관련된 글 (1) | 2025.09.01 |
| Mamba (2023) 논문 리뷰 (2) | 2025.08.26 |
| 도메인 특화 LLM 리서치 (4) | 2025.08.12 |
| MUVERA와 Mercury 리서치 (1) | 2025.07.15 |


