OpenAI에서 Why language models hallucinate (OpenAI 블로그 링크)라는 논문을 발표했다.
아직 논문을 본격적으로 읽은 것은 아니지만 핵심을 번역해보자면 다음와 같다.
문제:
Hallucination (환각)은 정답이 아니지만 그럴듯해 보이는 거짓말이다.
문제의 원인:
현재의 평가 방법들은 "모르는 것을 모른다" 라고 하는 것 보다는 "그럴듯한 답변을 생성"하면 더 좋은 성능으로 평가한다.
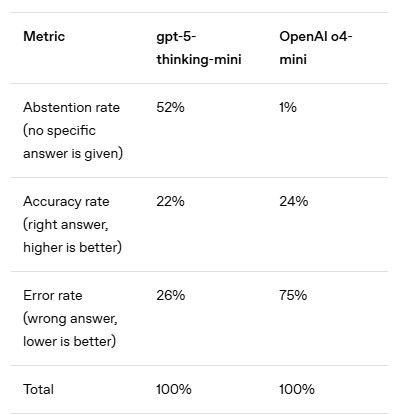
GPT-5-Thinking-Mini는 4-o-mini 보다 정답률은 낮지만, Abstention rate (기권율)과 Error rate (오류율)이 훨씬 더 낮다.
우리가 사용하는 텍스트 자료에는 일반적인 머신러닝 문제와 다르게 참 / 거짓 라벨이 붙어있지 않다.
따라서, 정답으로 주어진 텍스트만 가지고 전체 분포를 학습해야 한다. 즉 거짓을 모르는 상태로 모든 분포를 추측해야한다.
결론:
주장: 환각은 정확성을 개선함으로써 제거된다. 왜냐하면 100% 정확한 모델은 절대 환각을 일으키지 않기 때문이다.
발견: 정확성은 결코 100%에 도달할 수 없다. 모델의 크기, 검색 및 추론 능력에 관계없이 일부 실제 질문은 본질적으로 답할 수 없기 때문이다.
주장: 환각은 피할 수 없다.
발견: 그렇지 않다. 언어 모델은 불확실할 때 기권할 수 있기 때문이다.
주장: 환각을 피하려면 더 큰 모델에서만 달성 가능한 일정 수준의 지능이 필요하다.
발견: 작은 모델이 자신의 한계를 아는 것이 더 쉬울 수 있다. 예를 들어, 마오리어 질문을 받았을 때 마오리어를 전혀 모르는 작은 모델은 단순히 "모르겠다"고 말할 수 있지만, 마오리어를 조금 아는 모델은 자신의 확신 정도를 결정해야 한다. 논문에서 논의되었듯이, "보정(calibrated)"되는 데는 정확해지는 것보다 훨씬 적은 계산이 필요하다.
주장: 환각은 현대 언어 모델의 신비로운 결함이다.
발견: 우리는 환각이 발생하는 통계적 메커니즘과 평가에서 보상을 받는 방식을 이해한다.
주장: 환각을 측정하려면 좋은 환각 평가만 있으면 된다.
발견: 환각 평가는 이미 발표되었다. 그러나 좋은 환각 평가는 겸손을 페널티로 삼고 추측에 보상하는 수백 개의 전통적인 정확성 기반 평가에 거의 영향을 미치지 않는다. 대신, 모든 주요 평가 지표가 불확실성 표현 (expressions of uncertainty) 에 보상하도록 재작업되어야 한다.
앞으로 자연어에서의 Uncertainty에 대한 연구가 활발히 진행되려나 싶은 논문이다.
전에 봤던 불확실성 관련 논문은 ODIN (블로그 링크) 같은 컴퓨터 비전 뿐인데 NLP 분야도 봐야하나 싶기도 하다.
개인적으로 흥미로운 지점은 아예 작은 모델은 확실히 모르기 때문에 모른다고 답하기 쉽고,
애매하게 아는 모델은 자신의 불확실성을 평가해야 하기 때문에 오히려 기권하기 어렵다는 지점이다.
인간의 더닝-크루거 현상 애매함의 봉우리가 생각나기도 하고 그렇다.
흥미로워서 시간이 될 때 논문을 자세히 봐야겠다.
'NLP > LLM' 카테고리의 다른 글
| 41가지 로컬 LLM 벤치마크를 실행 결과 (1) | 2025.09.02 |
|---|---|
| LLM의 컨텍스트 윈도우와 관련된 글 (1) | 2025.09.01 |
| Mamba (2023) 논문 리뷰 (2) | 2025.08.26 |
| 도메인 특화 LLM 리서치 (4) | 2025.08.12 |
| MUVERA와 Mercury 리서치 (1) | 2025.07.15 |


