Faster R-CNN의 논문 이름은 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks이다.
저자는 Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun이다. (링크)
Faster R-CNN은 이름에서 짐작할 수 있듯이 Fast R-CNN을 개선한 모델이다. Fast R-CNN의 저자인 Ross Girshick 도 참여한 논문이다.
Abstract
SOTA (최근의) object detection networks는 region proposal을 통해서 object locations의 대상을 추측한다. SPPnet이나 Fast R-CNN은 detection 과정에서의 소요 시간을 감소시켰다. 이 논문에서는 RPN (Region Proposal Network)를 도입하여 full-image convolutional features를 detectoion network와 공유하여 cost-free region proposals를 가능하게 만들었다. RPN은 fully conv network이며 object bounds와 objectness score at each position을 동시에 예측한다. Fast R-CNN처럼 end-to-end 형식으로 region proposals를 생성한다. RPN와 Fast R-CNN을 하나의 네트워크로 병합하였다. PASCAL VOC 2007, 2012, MS COCO datasets에 대해서 높은 accuracy를 선보였으며 단지 300개의 propsals per image를 통해서 달성했다. ILSVRC와 COCO 2015 대회에서 Faster R-CNN와 RPN은 몇몇 트랙에서 1위를 달성했으며 코드도 공개적으로 사용할 수 있게했다.
1. Introduction
최근의 object detection은 region proposals methods의 성공에 힘입어서 발전했다. 전형적인 region proposal methods는 inexpensive features와 경제적인 추론에 기반한다. Seletive search가 대표적인 방법 중 하나로 가공된 low-level features에 기반한 superpixels를 greedily merge함으로써 작동한다. EdgeBoxes는 최근 속도와 proposal quality 사이의 tradeoff 사이에서 가장 나은 성능을 보여준다.
이 논문에서는 알고리즘적인 변화, 즉 deep conv neural network를 활용한 proposal 계산을 도입한다. 굉장히 우아하고 효율적인 알고리즘이기 때문에 proposal computation이 거의 cost-free다. 이는 Region Proposal Networks (RPNs)다.
RPNs는 다양한 scale과 aspect ratio를 다루면서 효율적인 region proposals를 예측하기 위해서 고안되었다. 기존의 pyramid 구조와는 다르게 anchor boxes라는 새로운 개념을 도입하고 multiple scales and aspect ratio에 대한 레퍼런스로 삼는다. 이 multiple references 구조는 아래의 Figure 1 (c)에 나와있다.

Fast R-CNN과 RPNs를 통합하기 위해서 다음의 트레이닝 방법을 선택했다. Region proposal task를 위한 파인 튜닝과 object detection을 위한 파인 튜닝을 번갈아 가면서 수행했다. Object detction을 파인 튜닝 할 때는 region proposal을 fix하고, region proposal을 파인 튜닝할 때는 object detection을 고정하는 방식이다.
Matlab과 Python 코드를 깃허브에 공개하였다. 또한 ILSVRC와 COCO 2015 대회들에서 1위를 달성했는데, 구체적인 부문은 다음과 같다. ImageNet detection, ImageNet localization, COCO detection, 그리고 COCO segmentation이다.
2. Related Works
Object Proposals
Deep Networks for Object Detection
이 부분은 생략
3. FASTER R-CNN
3.1. Region Proposal Networks
Region Proposal Networks (RPN)은 어떤 사이즈의 이미지가 들어오든간에 직사각형의 object proposals의 세트를 아웃풋으로 리턴한다. 이때 각각의 proposals를 모두 objectness score를 포함한다. 이전에 RoI proposal과 CNN이 하나로 통합된 unified system이라고 했는데 그 이유를 밑의 Figure 2에서 확인할 수 있다.

저자들은 ZF Net과 VGG-16 구조를 활용하여 실험을했다. ZF는 5 sharable conv layers를, VGG-16에서는 13 sharable conv layers를 조사했다고 한다. Region proposals를 생성하기 위해서 마지막 shared conv layer에 대해서 small network를 slide해서 feature map을 학습한다. 이를 통해서 lower-dimensional feature를 two sibiling fully-connected layers; box-regression layer (reg)와 box-classiciation (cls)에 넣는다. 이 mini-network의 구조는 아래의 Figure 3에서 그림으로 표현되었다. 개별 n x n (n = 3) conv layer 다음에는 1 x1 conv layers가 뒤따라온다. reg과 cls 모두 3x3 conv layer와 1x1 conv layer의 동일한 구조를 지니는데 각각은 서로 다른 파라미터를 지닌다.
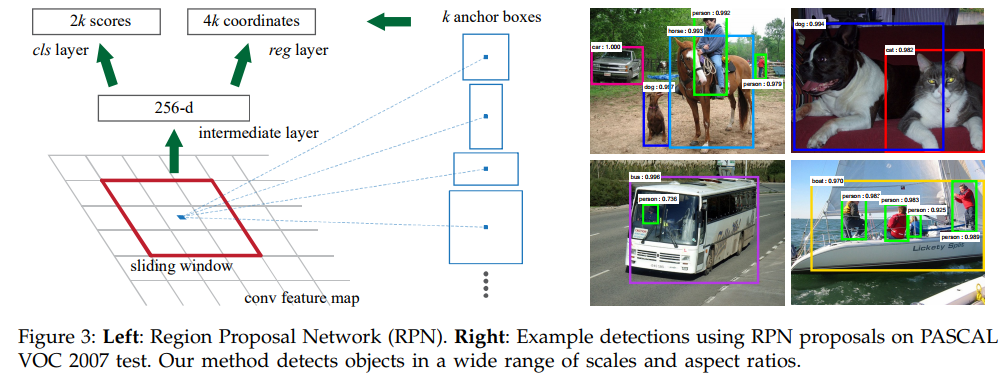
3.1.1. Anchors
개별 sliding-window locaion에 대해서, 복수의 region proposals를 동시에 예측한다. 이때 예측 가능한 proposals의 최대 수는 k로 나타낸다. 이때 reg layer는 총 4k의 outputs를 가지는데 각각인 k boxes의 좌표 (coordinates)를 encoding한다. 그리고 cls layer는 개별 proposal에 대한 object의 예측 확률 스코어를 2k개 예측한다. k proposals는 k references boxes에 비례해서 생성되는데 본 논문에서는 이를 anchor라고 명명한다. 개별 anchor는 sliding window의 중앙에 위치한다. 개별 anchor는 cale과 aspect ratio의 특성을 지니는데 본 논문의 기본값으로는 3개의 scales, 3개의 aspect ratio를 사용한다. 따라서 총 9개의 anchors를 개별 sliding position에 대해서 사용했다. Convolutional feature map의 size W x H (보통 ~2400)에 대해서 총합 WHk개의 anchors가 존재한다.
Translation-Invariant Anchors
본 논문의 접근법의 중요한 특성 중 하나는 translation invariant하다는 의미다. 이는 anchors와 anchors에 비례하는 proposals 계산 함수 양쪽에 대해서 적용된다. 비교를 위해서 MultiBox 방법은 살펴보자면 이 방법은 k-means를 이용하여 800 anchors를 만들기 때문에 NOT translation invariant다. 따라서 MultiBox는 object가 translated 되면 동일한 proposal을 생성한다고 보장할 수 없다.
Translation-invariant property는 모델 사이즈를 감소시킨다. MultiBox가 (4+1) x 800-dimensional FC output layer를 가지는데 비해서 본 논문에서 제시하는 방법은 (4+9) x 9-dimensional (k = 9 anchors)의 크기를 가진다. 결과적으로 output layer는 2.8 x $10^4$ parameters를 가지는데 (VGG-16에 대해서는 512 x (4 + 2) x 9), MultiBox의 6.1 x $10^6$ (GoogLeNet을 사용한 1536 x (4 + 1) x 800)보다 자리수가 2자리나 차이난다 (원문은 two orders of magnitude fewer than). Feature projection layers도 고려해도 아직도 자리수가 한 자리가 차이가난다. 파라미터 수가 훨씬 적기 떄문에 오버피팅의 위험이 보다 적다고 기대할 수 있다.
Multi-Scale Anchors as Regression References
저자들이 제시하는 anchors 디자인에서는 multiple scales (and aspect ratio)를 다룰 수 있다.
기존 피라미드와 cnn은 각기 다른 스케일에 맞게 리사이즈하고 각각을 개별적으로 계산해서 피쳐를 구한다. 이는 굉장히 시간적으로 소모가 오래걸린다. 다른 방법은 슬라이딩 윈도우를 사용하는 방법인데 이는 각각의 스케일에 대한 피쳐를 학습하지 않고 jointly 동시에 학습한다. 앵커의 피라미드에 기반하기 때문에 비용효율적이다. 앵커박스를 레퍼런스로 쓰는 reg와 cls 구조다. 이 구조는 싱글 스케일의 이미지, 피쳐, 필터를 쓰는데도 멀티플과 마찬가지로 좋음을 보였다.
3.1.2. Loss Function
개별 앵커에 object인지 아닌지를 라벨링하여 binary classification을 수행했다
Positive labels의 경우 두가지로 수행한다. Anchor들을 기준으로 해서 groudtruth로 첫번째는 수치가 0.7 이상인 경우, 두번째는 겹치는 iou가 가장 높은 경우다. 두번째 조건이 있는 경우는 0.7미만의 수치만 가지는 경우가 있기 때문이다. 하나의 gt가 여러개의 positive anchors를 가질수있다. Negative labels는 iou가 0.3 이하인 경우에 대해 배정했다. Pos label은 1이고 negative labrl은 0이다. 위의 cls loss 그리고 후술될 reg loss의 weighted sum이 최종 손실함수다. reg loss는 bbox의 center x, y coordinates와 height, width의 차이로 결정된다. 기존 box regression과 다르게 3x3 feature map으로 모두 같다. 사이즈의 다양성을 위해서 k개의 regressors를 두고 각각은 하나의 스케일과 aspect ratio를 담당하며 각각은 weights를 공유하지 않는 별개의 regressor다.
3.1.3. Training RPNs
엔드투엔드 (end-to-end)로 sgd를 이용해 학습한다. 256개의 미니배치를 뽑는데 pos와 neg의 비율이 1대1이 되도록한다. 만약 pos가 128개 이하면 neg로 나머지를 채운다. 이니시얼라이제이션은 N(0, 0.001)을 이용했다. Lr은 첫 60k mini batch에 대해서는 0.001이며 다음번 20k에 대해서는 0.0001로 설정했다. 이는 pascal voc 데이터에 적용한 수치다. 모멘텀은 0.9이고 weight decay는 0.0005다. 학습은 Caffee로 진행했다.
3.3. Sharing Features for RPN and Fast R-CNN
지금까지는 region proposal generation에 대한 네트워크 학습에 대해서 이야기했다면 지금부터는 이 proposals로 어떻게 region-based object detection에 사용할 CNN을 학습할지에 대해서 이야기한다. Detection network로는 Fast R-CNN을 사용하였으며 Figure 2에서 확인할 수 있듯이 RPN과 Fast R-CNN은 서로 convolutional layers를 공유한다.
RPN과 Fast R-CNN을 서로 독립적으로 학습하며 각각은 서로 다른 방법으로 conv layers를 조정한다. 이를 위한 테크닉을 개발했고 후술한다. 이는 총 3가지 가능한 방법이 있다.
(1) Alternating training. RPN을 먼저 학습하고, 여기서 도출된 proposals를 이용하여 Fast R-CNN을 학습한다. Fast R-CNN에 의해 조정된 네트워크는 다시 RPN의 초기화에 사용된다. 이 과정을 반복한다.
(2) Approximate joint tranining. 이 방법에서는 RPN과 Fast R-CNN을 하나의 네트워크로 합하여 동시에 학습한다. SGD iteration에서 포워드 과정에서 region proposals를 만들고, Fast R-CNN detector를 학습할 때는 pre-computed proposals를 고정하고 학습한다. Back propogation에서는 RPN loss과 Fast R-CNN loss를 모두 활용해서 업데이트한다. Approximate라는 이름이 붙은 이유는 proposal boxes' coordinates 역시 network responses에서 나오고 여기서 발생하는 derivatives를 무시하기 때문이다. 저자들의 실험에 의하면 이 방법이 alternating training과 비교했을 때 유사한 성능을 내면서도 25~50% 시간이 덜 걸린다는 것을 확인했다.
(3) Non-approximate joint tranining. 이 방법에서는 (2)와는 다르게 bounding box에서 발생하는 gradients 역시 포함한다. 따라서 differentiable ROI pooling layer이 필요하게 된다. 이는 nontrivial problem이고 그 해결은 RoI warping layer를 도입함으로써 가능하다. 이는 본 논문의 주제가 아니므로 넘어간다.
4-Step Alternating Training
1. ImageNet-pre-trained model을 이용해서 initialize하고 end-to-end region proposals task를 위해 파인튜닝을 한다.
2. 1단계에서 생성된 RPN을 활용하여 detection network인 Fast R-CNN을 학습한다. 이 detection network 역시 ImageNet-pre-trained model으로 초기화한다.
3. Detection network를 활용하여 RPN training을 초기화한다. 하지만 여기서는 shared conv layers를 고정하고 RPN에 대한 unique layers만 파인튜닝한다. 따라서 현재 두 네트워크는 conv layers를 공유한다.
4. Shared conv layers를 고정한 상태로 Fast R-CNN의 unique layers를 파인튜닝한다.
최종적으로 두 네트워크를 합친다.
3.3. Implementation Details
Train과 test에 있어서, region proposal과 object detection 모든 작업에 대해서 single scale 이미지를 사용했으며 re-scaled image의 shorter side는 600 픽셀이다. Multi-scale feature extraction은 accuracy의 향상이 있을 수 있지만 speed-accuracy trade-off가 있음이 밝혀졌다.
Anchors의 경우 3 scales를 사용했는데, box의 크기가 각각 $128^2$, $256^2$ , $512^2$ pixels를 가지며 3 aspect ratio를 가지는데 각각 1:1, 1:2, 2:1이다. Hyper-parameters를 특정 데이터에 대해 신중하게 선택되었다기 보다는 ablation study를 수행해서 얻었다.
3. EXPERIMENTS
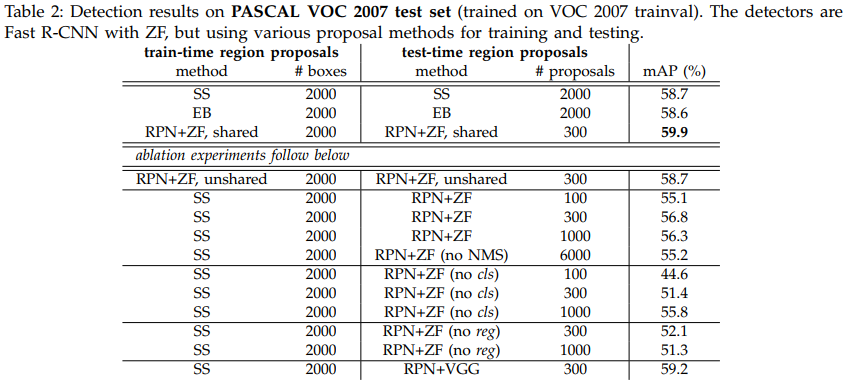
Table 2에 나온 SS는 Selective Search, EB는 EdgeBoxes를 의미한다.
RPN과 ZF net을 사용했을 때가 SS나 EB 보다 좋은 성능을 보임을 알 수 있다.

Table 3는 RPN과 VGG를 PASCAL VOC 2007에 적용한 결과, Table 4는 PASCAL VOC 2012에 적용한 결과다.
Table 5는 전체 object detection 시스템의 작동 시간을 보여주는데 ZF net을 활용한 RPN + Fast R-CNN으로 이미지 마다 300개의 region proposals만 제시하기 때문에 17 fps를 달성했다.
Analysis of Recall-to-IoU
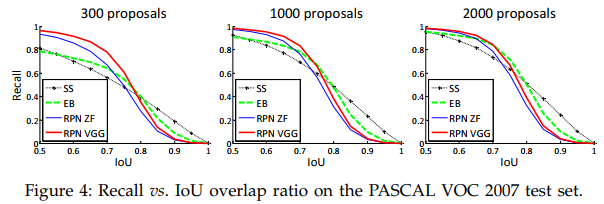
Proposals의 개수가 2000에서 1000으로, 300으로 줄어들 때 RPN은 Recall과 IoU이 약간만 감소하지만,
SS와 EB는 Recall이 급격하게 감소함을 확인할 수 있다.

One-Stage Detection vs. Two-Stage Proposal + Detection.
Table 10을 보면 one-stage 보다는 two-stage의 결과가 좋다. 또한 더 적은 region proposals에 1 scale로도 mAP 성능이 더 좋음을 확인할 수 있다.
4.2. Experiments on MS COCO

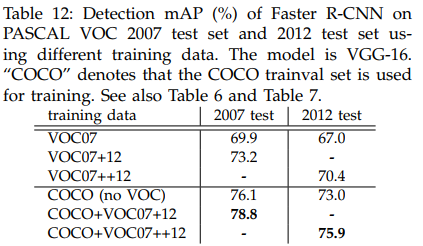
Table 11과 12를 보면 Faster R-CNN이 SOTA인 Fast R-CNN보다 좋은 mAP를 보임을 알 수 있다.
'Computer Vision' 카테고리의 다른 글
| DeepLab v1(2016) 논문 리뷰 (0) | 2025.04.06 |
|---|---|
| FCN (2015) 논문 리뷰 (0) | 2025.04.06 |
| ResNet (2016) 논문 리뷰 (0) | 2024.04.15 |
| Fast R-CNN (2015) 논문 리뷰 (0) | 2024.04.14 |
| SPPNet (2014) 논문 리뷰 (0) | 2024.04.09 |



