CAM은 Class Activation Mapping의 약자로 논문의 제목은 Learning Deep Features for Discriminative Localization이다. (링크)
저자는 Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba다.
CAM에서는 Weakly supervised 방법으로 이미지의 오브젝트를 히트맵 Heatmap 형식으로 표기한다.
Abstract
Global average pooling (GAP)를 다시 활용하여 CNN에 있어서의 localization 능력을 이미지 레벨에서 효과를 달성한다.
ILSVRC 2014에서 top-5 error를 37.1%를 달성했는데 이는 fully supervised CNN의 top-5 error인 34.2%에 근사했다.

2. Class Activation Mapping
Class activation mapping (CAM)은 global average pooling (GAP)를 CNN 내에서 사용한다.
백본 아키텍쳐로 GoogLeNet을 사용한다.
주어진 이미지에 대해서 $f_k(x, y)$는 spatial location $(x, y)$에 존재하는 unit $k$의 activation을 표현한다.
Unit $k$에 대한 gap의 결과는 $F^k$로 표기하며 이는 $ \sum_{x, y} f_k (x, y) $으로 계산한다.
주어진 class $c$에 대해서 softmax의 결과인 $S_c$인데 이는 $ \sum_{k} w_k^{c} F_{k} $으로 구할 수 있다.
$ w_k^{c}$는 unit $k$에서 class $c$에 대한 weight 가중치다.
$w_k^{c}$는 class $c$에 대한 $F^k$의 importance를 나타낸다.
$P_c$는 $ \frac{ exp(S_c) }{ \sum_{c} exp(S_c)} $로 계산한다.
$ F^k $ = $ \sum_{x, y} f_k (x, y) $ 이므로
$ S_c $ = $ \sum_k w_k^{c} \sum_{x, y} f_k (x, y) $
= $ \sum_k \sum_{x, y} w_k^{c} f_k (x, y) $
Class activation map for class $c$는 $M_c$이며 이는 다음과 같이 정의된다.\
$M_c (x, y)$ = $ \sum_k w_k^{c}f_k (x, y) $
따라서 $ S_c $ = $ \sum_{x, y} M_c (x, y) $ 다.
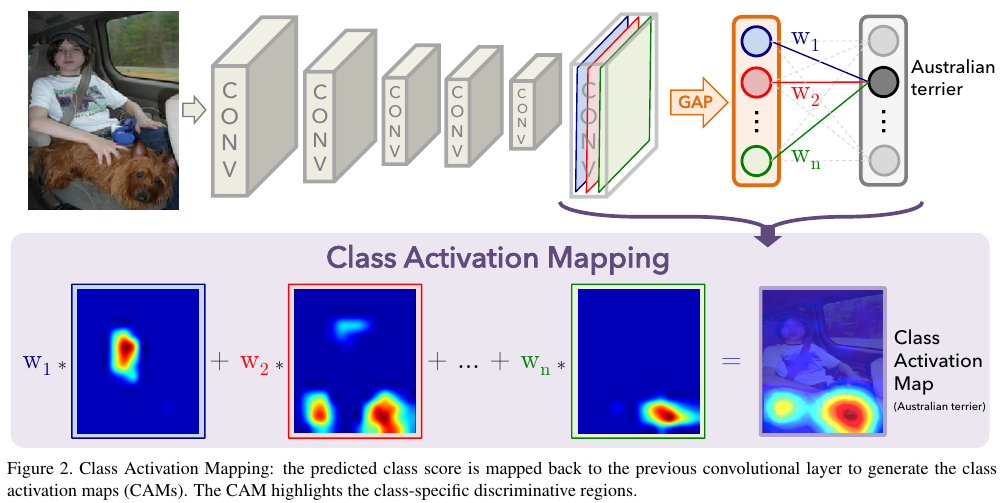
GAP를 구하는 수식은 복잡해 보일 수도 있지만 Figure 2를 보면 사실 간단하다.
거의 맨 마지막에 class의 개수 만큼의 채널이 있다. 그리고 해당 채널의 행렬의 모든 값을 평균내어서 하나의 scalar 값으로 리턴한다는 뜻이다.

CAM의 결과를 보면 object가 있을만한 부분에 빨간색으로 표시되어 사람이 알아보기 쉬움을 알 수 있다.
논문에서는 GAP와 Global max pooling (GMP)과도 비교한다.
여기에서 가져온 global max pooling의 그림을 보면 알겠지만 GMP는 전체 행렬에서 가장 큰 하나의 scalar 값을 가져온다.
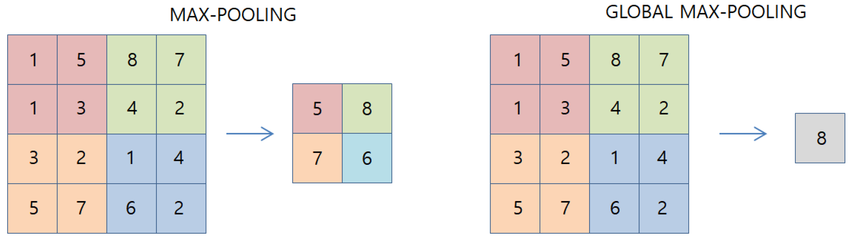
GMP는 GAP와 다르게 하나의 cell, image의 경우 patch나 pixel이 되는데 해당 정보만 담고 나머지는 버리기 때문에 feature의 손실이 크다.
3. Results
CAM 논문의 경우 weakly-supervised 방법이고 AlexNet이나 OverFeat, GoogLeNet은 fully-supervised 방법이다.
Weakly-supervised란 bounding box 없이 이미지 전체에 대한 클래스 정보만 이용한다는 뜻이다.
CAM에서 인용한 논문인 Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps (링크)를 보면 알 수 있다.
반대로 Fully-supervised는 bounding box와 그에 대한 클래스 정보가 포함되어 있다.
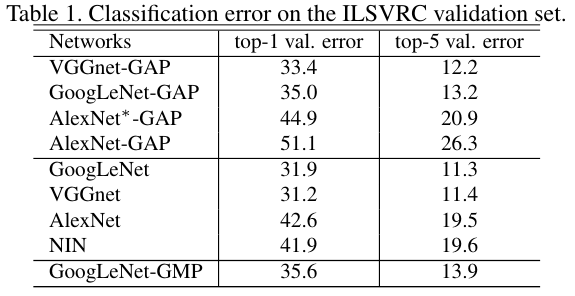
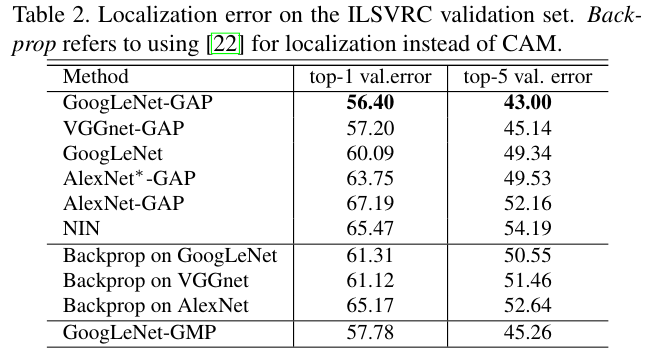

사람이 알아보기 쉬운 설명 가능성이 있지만 Fully-supervised에 비해서 성능은 비교적 낮음을 알 수 있다.
Refernces:
https://simpling.tistory.com/30
'Computer Vision' 카테고리의 다른 글
| DenseNet (2017) 논문 리뷰 (0) | 2025.04.07 |
|---|---|
| SSD (2016) 논문 리뷰 (0) | 2025.04.07 |
| YOLO v1 (2015) 논문 리뷰 (0) | 2025.04.06 |
| U-net (2015) 논문 리뷰 (0) | 2025.04.06 |
| DeepLab v1(2016) 논문 리뷰 (0) | 2025.04.06 |



