YOLO는 You Only Look Once: Unified, Real-Time Object Detection으로 가장 유명한 논문 중 하나일 것이라 생각한다. (링크)
저자는 Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi다.
반쯤 방치된 블로그도 살리고 컴퓨터 비전 분야 복습도 할 결심을 하게 해준 논문의 첫번째 버젼이다.
최근에 YOLO가 v10까지 나온걸 발견해서 이전에 공부한 내용을 옮겨 적기 시작했기 때문이다.
논문 제목에서도 알 수 있듯이 object detection 알고리즘이다.
Abstract
YOLO는 object detection을 일종의 regression 문제로 해석하여 spatially separated bounding boxes와 연관된 클래스의 확률을 풀었다. 단 한번의 평가로 bounding box와 classification을 해결한다.
통합된 과정이기 때문에 매우 빠르기 때문에 초당 45개의 프레임을 처리한다. Fast YOLO라는 더 작은 모델은 초당 155 프레임을 처리하면서 다른 리얼 타임 디텍터의 2배의 mAP를 달성했다. 또한 DPM과 R-CNN보다 좋은 성능을 보인다.
2. Unified Detection

YOLO는 input image를 리사이즈 한다. Conv net을 작동시킨다. Model의 confidence에 따라서 detection 결과를 반환한다.
보다 자세한 과정은 다음과 같다.

1. Input image를 S x S grid로 분할한다.
어떤 오브젝트가 grid cell의 중앙에 위치한다면 해당 그리드 셀은 detecting object을 책임진다.
2. 각각의 grid cell은 B bounding boxes (이하 bbox)를 예측하고 각 박스에 대해서 confidence socre를 가진다.
Confidence score는 얼마나 해당 object를 얼마나 정확하게 예측하는지를 나타내는 지표다.
Confidence score를 Pr(Object) * $\operatorname{IOU}_{pred}^{truth}$로 정의했다.
만약에 오브젝트가 없다면 confidence scores는 0이다.
오브젝트가 있다면 confidence score는 predicted box와 ground truth 사이의 IOU (intersection over union)다.
각각의 bbox는 다음의 5개의 예측으로 구성된다. $x, y$는 bbox의 중앙 (center)의 좌표이며, $w$는 bbox의 width, $h$는 height다. 그리고 마지막은 confidence다.
각각의 또한 C conditional class probabilities를 가지는데 이는 Pr($\operatorname{Class}_{i} | \operatorname{Object} $)다.
이 확률은 개별 grid cell이 해당 object를 condition으로 가질 때의 확률이다.
B개의 bbox의 개수에 상관없이 하나의 grid cell에 대해서 오직 하나의 class probabilities set을 가진다.
3. Test time에는 각각의 conditional probabilities를 곱한다.
Pr($ \operatorname{Class}_{i} | \operatorname{Object} $) * Pr(Object) * $ \operatorname{IOU}_{pred}^{truth} $
= Pr($ \operatorname{Class}_{i} $) * $\operatorname{IOU}_{pred}^{truth} $
이는 결국 class-specific confidence scores of each box라는 결과를 만든다.
위 결과는 해당 클래스가 해당 bbox에 나타날 확률과 bbox가 얼마나 해당 object에 적합한지를 보여준다.
PASCAL VOC에서 S = 7, B = 20으로 설정했으며 C = 20이고 최종 예측은 7 x 7 x 30 tensor가 된다.
Network Architecture
YOLO의 구체적인 네트워크 아키텍처는 아래와 같다.

Training
Input size는 448 x 448이다.
bbox의 width와 height는 image의 width와 height에 따라서 normalize하여 0과 1사이의 값을 갖는다.
그리고 actvation function으로는 Leaky ReLU (Rectified linear activation)을 사용했으며 0이하의 계수는 0.1이다.
즉, if $x$ > 0, $\phi(x)$ = $x$ and $0.1 x$ otherwise.
그리고 loss function은 아래와 같다.
Hyperparameteres인 $\lambda_{coord}$ = 5, $\lambda _{noobj}$ = 0.5의 값을 갖는다.

bbox가 object과 동일하도록 하는 coordinate 예측 관련 loss들과 class에 대한 예측, 그리고 class의 confidence에 대한 예측을 모두 최적화한다.
Limitations
Small objects, 새와 같은 경우에는 어려움을 겪는다.
새롭거나 특이한 asepect ratios에서도 작동이 쉽지 않다.
작은 bbox의 적용과 detection에 단점이 있다.
4. Experiments
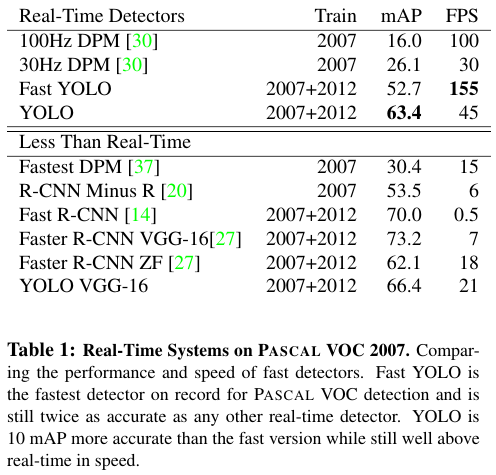
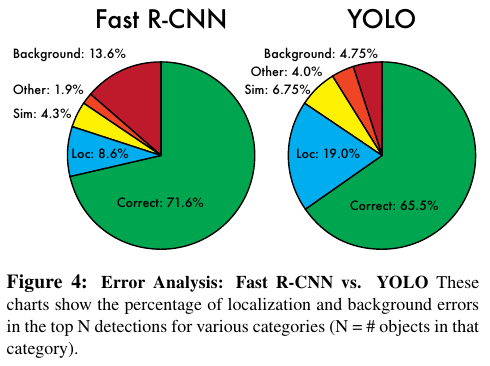
속도 측면에서는 굉장한 향상이 있지만 mAP 측면에서는 Fast R-CNN 보다 다소 부족한 모습을 보인다.
References:
https://dotiromoook.tistory.com/24
'Computer Vision' 카테고리의 다른 글
| SSD (2016) 논문 리뷰 (0) | 2025.04.07 |
|---|---|
| CAM (2015) 논문 리뷰 (0) | 2025.04.07 |
| U-net (2015) 논문 리뷰 (1) | 2025.04.06 |
| DeepLab v1(2016) 논문 리뷰 (0) | 2025.04.06 |
| FCN (2015) 논문 리뷰 (0) | 2025.04.06 |



