DeepLab의 논문 이름은 Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRF으로 Atrous Convolution (aka Dilated Convolution)으로 유명한 논문이다. (링크)
저자는 Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille다.
DeepLab v2는 DeepLab v1의 개정증보판이라고 보면된다.
따라서 자세한 내용은 이전에 정리한 DeepLab v1의 내용과 거의 동일하다.
차이점은 ASPP (Atrous Spatial Pyramid Pooling)이다.
ASPP (Atrous Spatial Pyramid Pooling)
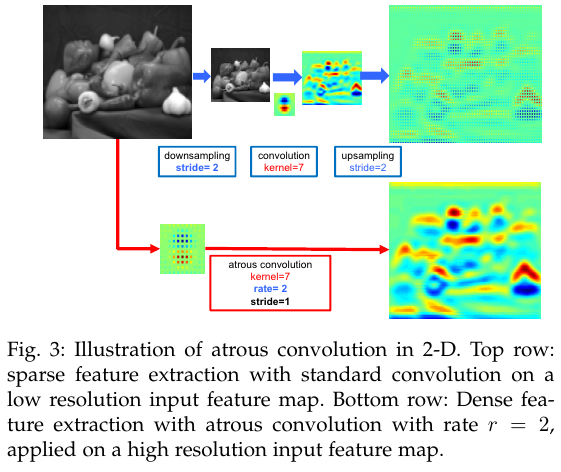
우선 Fig 3에서는 Atrous convolution이 더 큰 사이즈의 피쳐에서 object를 더 잘 포착함을 보여준다.

Fig 4에서는 Atrous Conv를 rate를 다르게 하여 서로 다른 크기의 receptive fields를 동시에 활용하는 방안을 제시했다.
다양한 크기의 receptive fields로 multi-scale features를 활용이 가능하게 된다.
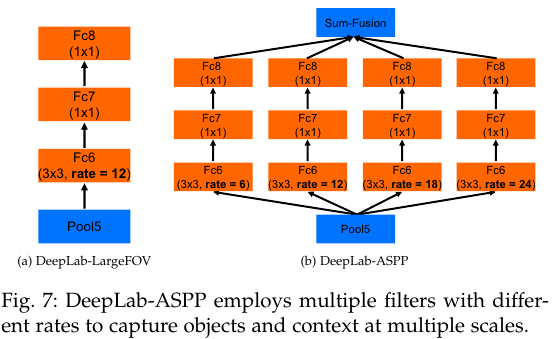
기존의 DeepLab v1은 DeepLab-LargeFOV로 하나의 Atrous convolution만을 사용한다.
반면에 DeepLab-ASPP는 여러개를 사용한다.

Table 3를 보면 atrous를 여러개 사용한 ASPP-S와 ASPP-L이 단일 atrous를 사용한 LargeFOV 보다 좋은 성능을 보인다.
References:
https://noru-jumping-in-the-mountains.tistory.com/15
https://noteforstudy.tistory.com/entry/Deeplab-v2-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
'Computer Vision' 카테고리의 다른 글
| EfficientNet (2019) 논문 리뷰 (0) | 2025.04.08 |
|---|---|
| MobileNet (2017) 논문 리뷰 (0) | 2025.04.08 |
| RetinaNet Focal Loss (2017) 논문 리뷰 (0) | 2025.04.07 |
| DeepPose (2014) 논문 리뷰 (0) | 2025.04.07 |
| FaceNet (2015) 논문 리뷰 (0) | 2025.04.07 |



