MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (링크)에서 소개된 MobileNet은 휴대용 기기에서 사용하기 위해 고안한 작은 규모의 NN이다.
저자는 Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam다.
Abstract
모바일 기기나 임베디드 비전 어플에서 사용할 효율적인 모델인 MobileNets를 제시한다.
Depth-wise separable convolutions를 통해서 가벼운 DNN을 소개한다.
두 개의 단순한 global hyperparameters를 통해서 latency와 accuracy의 트레이드 오프를 다룬다.
Object detection, finegrain classification, face attributes 그리고 arge scale geo-localization의 다양한 태스크들에 대해서도 실험을 마쳤다.

Figure 1은 MobileNet의 목적과 가능한 태스크들을 시각화한다.
3. MobileNet Architectures
MobileNet은 Depthwise separable convolutions에 기반한다.
이는 다음의 Figure 2의 (b)와 (c)를 보면 알 수 있다.
표준적인 conv layer는 input feature map DF×DF×M F를 입력으로 받아서,
output feature map DF×DF×M G를 생성한다.
이때 DF는 width와 height가 같은 정사각형 spatial feature map이다.
N은 output channel (output depth)의 수다.
Channel의 수가 곧 depth다.
Convolution kernel의 크기를 K라고 할 때 다음 개수만큼 파라미터를 가진다.
DK×DL×M×N이다.
DK는 kernel의 width와 height를 나타낸다.
M은 input channel의 수, N은 output channel의 수다.
위에서 언급한 표준적인 컨볼루션에 의해 생성된 Output feature map은 다음처럼 계산된다.
Gk,l,n=∑i,j,mKi,j,m,n⋅Fk+i−1,l+j−1,m
그리고 computational cost는 아래처럼 계산된다.
DK⋅DK⋅M⋅N⋅DF⋅DF.
Input channels의 수가 M일 때 kernel size는 DK⋅DK고 feature map은 DF⋅DF다.
본 논문에서는 출력 (output) 채널의 수와 커널 사이즈 사이의 상호작용을 깨뜨려서 depthwise separable convolution을 활용한다.
Depthwise separable convolution은 두 가지 레이어로 구성된다.
Depthwise convolutions와 pointwise convolutions다.
Depthwise convolution은 input channel 마다 하나의 filter를 갖는다.
이는 아래와 같이 계산된다.
ˆGk,l,m=∑i,jˆKi,j,n⋅Fk+i−1,l+j−1,m
ˆK는 depthwise convolution의 커널 사이즈로 DK timesDK×M이고,
m 번째 필터로, ˆK가 F의 m 번째 채널에 적용되어 출력 feature map인 ˆG의
m 번째 채널의 결과다.
Depthwise convolution의 computational cost는 따라서,
DK⋅DK⋅M⋅DF⋅DF.
표준적인 컨볼루션에 비해서 훨씬 효율적이다.
Pointwise convolution은 1 x 1 convolution으로 채널들의 linear combination을 수행한다.
왜냐면 Depthwise convolution은 입력 채널을 필터링만 하기 때문이다.
Depthwise convolutions와 pointwise convolutions의 결합을 Depthwise separable convolution라고 한다.
Computational cost는 아래와 같다.
$ D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot N \cdot D_F \cdot D_F $.
표준적인 convolution의 computational cost와 비교하면 아래와 같다.
DK⋅DK⋅M⋅N⋅DF⋅DFDK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF.
= $ \frac{1}{N} + \frac{1}{{D_K}^{2}} $
3.2. Network Structure and Training
구체적인 MobileNet의 구조는 Table 1에 소개되어 있다.
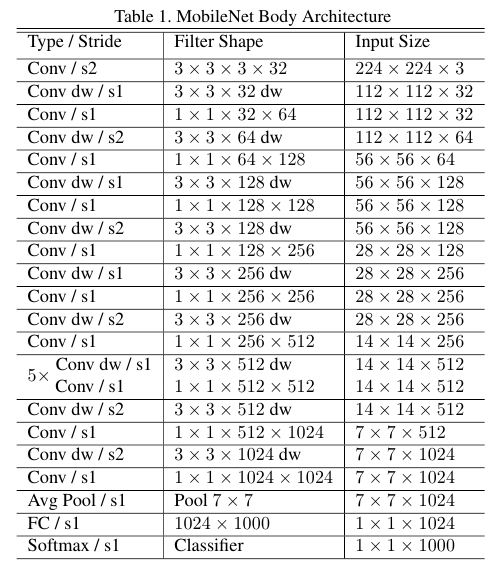
Batch norm와 ReLU를 모든 depthwise conv와 1 x 1 conv 뒤에 적용한다.
아래의 Figure 3와 같은 형식이다.

Tensorflow와 RMSprop으로 학습했다.
3.3. Width Multiplier: Thinner Models
Width multiplier α를 도입하여 더 작고 계산 비용 효율적인 모델을 만들고자 한다.
입력 채널 수와 출력 채널 수를 조정한다.
이며, 일반적인 설정 값은 1, 0.75, 0.5, 0.25다.
은 기본 MobileNet이며, 은 축소된 MobileNet이다.
DK⋅DK⋅αM⋅DF⋅DF+αM⋅αN⋅DF⋅DF.
α2에 비례하여 계산 비용과 파라미터 수를 줄이는 효과가 있다.
3.3. Resolution Multiplier: Reduced Representation
두 번째 하이퍼파라미터는 resolution multiplier ρ다.
이를 통해서 입력 해상도를 조절한다.
DK⋅DK⋅αM⋅ρDF⋅ρDF+αM⋅αN⋅ρDF⋅ρDF.

Table 3에서는 표준적인 컨볼루션과 Depthwise Separable Conv, 그리고 Width Multiplier와 Resolution Multiplier를 적용했을 때의 파라미터 수를 비교한 결과다.
4. Experiments

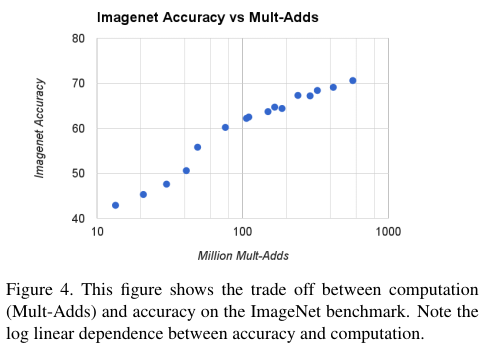

크기별 모바일넷의 성능 비교 표들이다. 이미지 분류 태스크에 대해서 0.75는 1.0과 큰 차이가 없음을 알 수 있다.

테이블 8을 보면 훨씬 적은 파라미터를 가지고도 ImageNet에 대한 분류 문제에서 비슷한 성능을 달성했음을 알 수 있다.

Face Attributes classification에 대한 결과다. 모델의 크기를 많이 줄여도 성능이 준수하게 유지된다.
YFCC100M 데이터에 대한 실험 결과다.


COCO 데이터데 대한 object detection 결과다. 급격하게 줄어든 모델 사이즈에 비해서 준수한 성능을 보여주고 있다.

FaceNet에서 distill한 결과는 위 Table 14에 나와있다.
'Computer Vision' 카테고리의 다른 글
| YOLO v2 (2016) 논문 리뷰 (0) | 2025.04.08 |
|---|---|
| EfficientNet (2019) 논문 리뷰 (0) | 2025.04.08 |
| DeepLab v2 (2016) 논문 리뷰 (0) | 2025.04.08 |
| RetinaNet Focal Loss (2017) 논문 리뷰 (0) | 2025.04.07 |
| DeepPose (2014) 논문 리뷰 (0) | 2025.04.07 |



