EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (링크)에서 소개된 EfficientNet은 효율적인 NN 구조를 탐색하는 논문이다.
저자는 Mingxing Tan, Quoc V. Le다.
Abstract
CNN은 스케일을 키울수록 정확도가 올라가는 경향을보였다. 본 논문에서는 네트워크 구조의 depth, width, resolution 사이의 밸런스를 조심스럽게 맞추면서 좋은 성능을 내도록 한다. MobileNet이나 ResNet보다 효율적인 성능을 냈음을 보인다.

Figure 1을 보면 대체로 모델 크기가 커질수록 좋은 성능임을 알 수 있다.
3. Compound Model Scaling
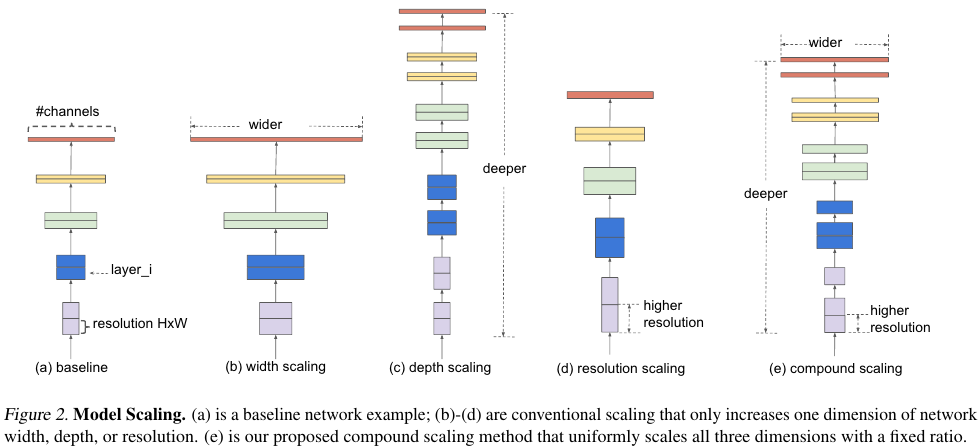
본 논문에서는 width, depth, resolution 즉 깊이, 너비, 입력 이미지의 해상도의 측면에서 체계적 연구를 수행한다.
A ConvNet Layer $i$ 은 다음과 같은 함수로 정의된다.
$Y_i = F_i (X_i )$, where $F_i$ is the operator, $Y_i$ is output tensor, $X_i$ is input tensor, with tensor shape <$H_i , _ i , C_i $> (배치 차원은 제외), where $H_i$ and $W_i$ are spatial dimension and $C_i$ is the channel dimension.
A ConvNet $N$은 다음의 컨볼루션 레이어들의 합성 함수다.
$N = F_k \odot F_2 \odot F_1 (X_1) = {\odot}_{j=1...k} F_j (X_1) $.
$N = \underset{\odot}{j=1...,s} F_{i}^{L_i} (X_{<H_i, W_i, C_i>}) $.
$ F_{i}^{L_i} $는 레이어 $F_{i}$가 stage $i$에서 $L_i$ 번 반복된다는 뜻이다.
최종적으로 최적화의 문제는
Accuracy($N(d, w, r)$)을 최대화 하는 $d, w, r$을 찾는데에 있다.
Memory($N$)은 target memory보다 작거나 같게,
FLOPS ($N$)은 target flops보다 작거나 같게 만들고 싶다.
$d, w, r$은 각각 scaling networks의 coefficients 계수다.

Figure 3를 보면 널리 알려진 바와 같이 계수가 클수록 더 많은 FLOPs를 요구하며 성능이 향상됨을 알 수 있다.

$d$와 $r$을 동시에 변경했을 때는 FLOPs와 정확도가 어떻게 변하는지를 나타낸 그림이다.
Compound scaling method
$d, w, r$ 계수들을 계산하는 compound coefficient $\phi$를 새롭게 제시한다.
$\phi$를 통해서 다른 세 가지 계수를 모두 조정한다.
구체적인 식은 다음과 같다.
$d = \alpha^{\phi}$
$w = \beta^{\phi}$
$r = \gamma^{\phi}$
such that
$\alpha \beta^{2} \gamma^{2} \approx 2 $
$\alpha \geq 1, \beta \geq 1, \gamma \geq 1 $
Total FLOPS는 대체적으로 $2^{\phi}$로 계산할 수 있다.
4. EfficientNet Architecture
STEP 1: $\phi$ = 1로 fix. 그 다음 $\alpha, \beta, \gamma$에 대해서 grid search를 수행한다.
EfficientNet-B0을 예로 들면 최상의 값은 $\alpha = 1.2, \beta = 1.1, \gamma = 1.15$다.
STEP2: $\alpha, \beta, \gamma$를 고정하고 $\phi$를 탐색해서 EfficientNet-B1 부터 B7까지를 찾는다.
5. Experiments
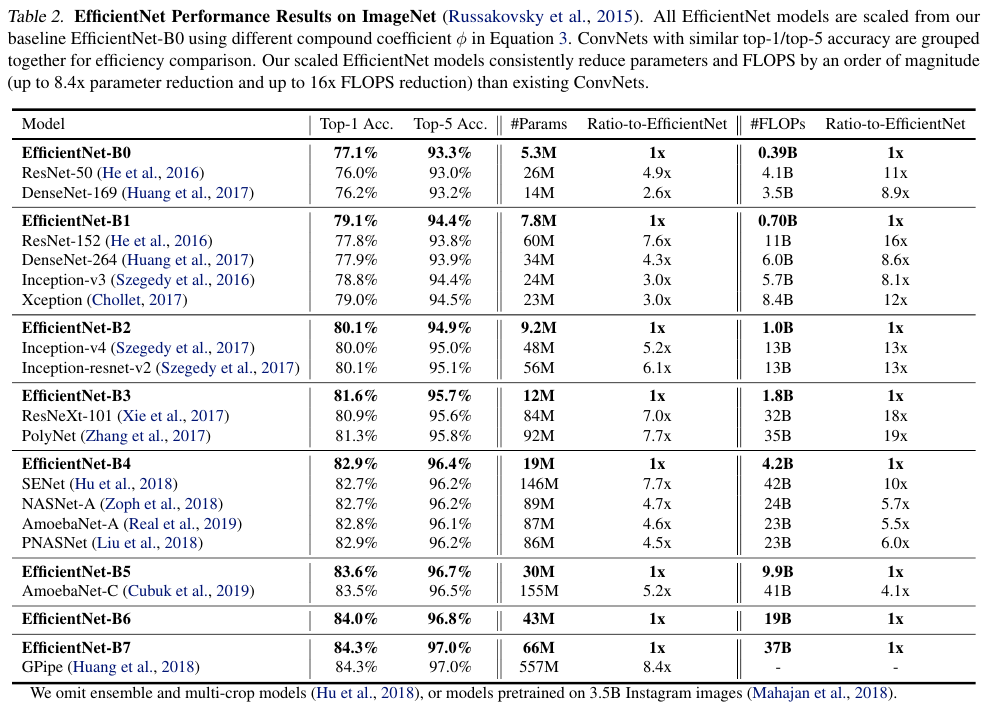
Table 2에서는 더 적은 파라미터로도 SOTA 성능을 달성했음을 보인다.

Table 3에서는 작은 모델인 MobileNet이나 ResNet 구조를 EfficientNet에서 제시한 방법대로 스케일업 했을 때에도 충분히 성능이 보장됨을 보여준다.

Table 5와 Figure 6에서는 ImageNet에서 학습한 다음 새로운 데이터에 대해서 finetune하는 방식의 transfer learning의 성능을 보여준다. SOTA에 근접하는 성능을 더 작은 파라미터로도 달성했음을 보여준다.

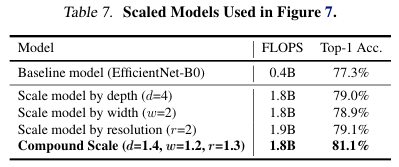
Figure 7와 Table 7에서는 CAM 방식의 weakly supervised localization을 수행한 결과인데 compound scaling이 깊이, 너비, 해상도의 단일 스케일링 보다 더 좋은 성능임을 보여준다.
References:
https://hoya9802.github.io/deep-learning/flops/
'Computer Vision' 카테고리의 다른 글
| YOLO v3 (2018) 논문 리뷰 (0) | 2025.04.08 |
|---|---|
| YOLO v2 (2016) 논문 리뷰 (0) | 2025.04.08 |
| MobileNet (2017) 논문 리뷰 (0) | 2025.04.08 |
| DeepLab v2 (2016) 논문 리뷰 (0) | 2025.04.08 |
| RetinaNet Focal Loss (2017) 논문 리뷰 (0) | 2025.04.07 |



