YOLO v2의 논문 이름은 YOLO9000: Better, Faster, Stronger다. (링크)
저자는 Joseph Redmon, Ali Farhadi다.
DenseNet은 object detection에 사용되는 알고리즘이다.
Abstract
YOLO9000은 real-time object detection 시스템으로 9000개 넘는 오브젝트 카테고리를 탐지할 수 있다.
기존의 YOLO의 개선 버젼인 본 논문의 YOLOv2는 본 논문에서 소개한다. PASCAL VOC 2007, COCO에서 SOTA를 달성했다.
Object detection과 classification을 동시에 학습했다. COCO detection 데이터셋과 ImageNet의 classification 데이터셋을 동시에 학습했다.

2. Better
기존의 YOLO는 Fast R-CNN에 비해서 localisation error가 심했고 region proposal-based 보다 recall이 낮았다.
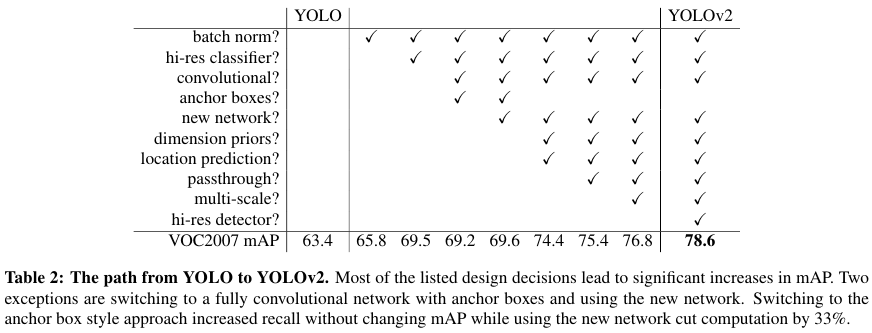
YOLO v2에서는 Table 2에 나온 다음의 개선점들을 통해서 빠르면서도 성능을 정확하게 만들었다.
Batch Normalization
BN은 모든 convolutional layers에 덧붙여서 mAP 기준 2%의 향상을 거두었다.
High Reslution Classifier
YOLOv2는 기존의 YOLO가 224 x 224를 학습한 것보다 더 큰 사이즈의 448 x 448 크기의 input data를 ImageNet에 대해서 10 epochs 만큼 학습했다.
Convolutional With Anchor Boxes
YOLO v1은 bounding boxes의 coordinates를 직접적으로 예측하는데 이때 convolutional feature extractor의 위에 있는 fully connected layer (FCL)를 직접 사용하여 달성한다.
반면에 Faster R-CNN에서는 hand-picked priors를 활용하여 bbox를 예측한다.
Faster R-CNN에서 conv layers인 RPN (region proposal network)는 anchor boxes에 대한 offsets와 confidences를 예측한다. 예측 레이어가 convolutional이기 때문에 RPN은 feature map 안에 있는 모든 위치 (every location)의 offsets만을 예측한다.
(offsets는 이전에도 적은 바 있는거 같지만 편차값이다. 즉 실제 anchor boxes의 좌표 값과 예측값의 편차다)
Offsets의 예측은 좌표의 예측보다 문제를 단순화시키므로 네트워크가 학습하기 용이하다.
저자들은 우선 YOLO에서 FCL을 제거한다. 그리고 anchor boxes를 사용해어 bbox를 예측한다. 우선 one pooling layer를 제거해서 conv layers의 outputs을 higher resolution으로 만든다. 또한 네트워크가 448 x 448 대신 416 input images에 작동하도록 축소한다. 이는 feature map이 홀수의 locations를 가져서 오직 하나의 단일한 center cell을 가지도록 만들게 하기 위함이다.
Factor 32를 사용하여 conv를 거치면 416 사이즈의 입력 이미지는 최종적으로 13 x 13 사이즈의 output feature map의 결과로 도출된다.
Anchor boxes를 움직일 때 class prediction과 spatial location을 분리한다. 대신 class prediction과 objectness를 모든 anchor box에 대해서 수행한다. YOLO와 동일하게 objectness prediction은 groundtruth와 proposed box의 IOU, 그리고 object가 주어졌을 때의 클래스에 대한 조건부 확률을 예측한다. p(class | object)를 예측한다.
Anchor boxes를 사용하지 않으면 mAP는 69.5이고 recall은 81%다. Anchor boxes를 사용하면 mAP는 69.2이고 recall은 88%다. mAP가 살짝 감소하더라도 recall의 향상이 더 크기 때문에 모델의 향상 가능성이 남아있다.
Dimension Clusters
사람이 직접 고르는 대신에 k-means 클러스터링을 통해서 좋은 bbox를 고른다.
유클리디안 거리를 사용하면 더 큰 박스가 더 작은 박스보다 더 큰 에러를 생성하므로 IOU를 이용한 거리를 도입한다.
d(box, centroid) = 1 - IOU(box, centroid)
이때 centroid는 k-means clustering의 개별 클러스터의 중심점이다.


평균 IOU를 이용해 비교했을 때 k가 5일 때 model의 복잡도와 high recall 사이의 트레이드오프 사이에서 적절하다고 간주하여 선택했다.
Direct location prediction
Anchor boxes를 이용할 때 학습 초기에 모델이 불안정 (instability)한 현상이 발견되었다.
이는 bbox의 location (x, y)를 직접 예측하기 때문에 생긴다.
Region proposal network에서는 $t_x$와 $t_y$와 center 좌표인 $(x, y)$를 예측한다.
이때 $x = (t_x * w_a) - x_a$ 그리고
$y = (t_y * h_a) - y_a$로 계산한다.
예측 $t_x$ = 1은 box를 오른쪽으로 anchor box의 width (너비) 만큼 오른쪽으로 이동한다.
반면에 $t_x$ = -1은 box를 anchor box의 hieght (높이) 만큼 왼쪽으로 이동한다.
이 방식은 이미지 위의 모든 공간에 이동할 수 있기 때문에 선택지도 많다.
또한 random initilization 때문에 위 과정을 거친 offsets의 예측은 시간이 오래 걸린다.
반면에 YOLO는 그리드 셀의 위치에 상대적인 location 좌표를 예측한다.
이는 groud turh 값들이 0과 1 사이에 떨어지도록 제한한다. 로지스틱 activation funcion를 사용하여 네트워크의 예측이 이 범위 내에 떨어지도록 만든다. 로지스틱 함수는 σ()로 표기한다.
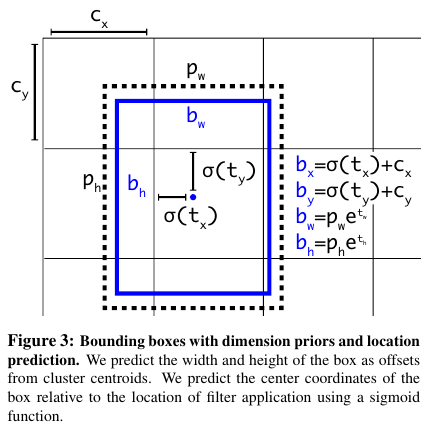
위의 Figure 3에 나온 방법대로 YOLO에서는 bbox를 예측한다.
네트워크는 output feature map의 하나 하나의 셀에 대해서 5개의 bbox를 예측한다.
네트워크는 각 경계 박스에 대해 5개의 좌표 $t_x, t_y, t_w, t_h, t_o$를 예측한다.
셀이 이미지의 왼쪽 상단 모서리 (top left corner)에서 편차가 ($c_x, c_y$)로 계산되고 bbox 사전 정보 (prior)에서 제시한 너비와 높이가 $p_w, p_h$이면 예측은 다음의 식과 같다:
$b_x = σ(t_x) + c_x$
$b_y = σ(t_y) + c_y$
$b_w = p_w \, e^{t_w}$
$b_h = p_h \, e^{t_h}$
Pr(object) ∗ IOU($b$, object) = σ($t_o$)
네트워크가 더 쉬운 작업을 학습하기 때문에 네트워크가 보다 안정적이다.
Dimension clusters를 통해서 anchor box가 있는 YOLO보다 bbox의 직접 예측 성능이 5% 향상되었다.
Fine-Grained Features
YOLO의 예측은 13 x 13 feature map에서 이루어진다.
큰 object의 경우 충분할 수 있지만, 더 작은 object에 대해서는 부족할 수 있다.
(큰 object의 경우 더 작은 사이즈로 압축해도 구분이 되지만, 더 작은 물체의 경우엔 보다 큰 이미지여야 세세한 내용이 이미지에 나타나고, 이를 통해서 구분될 수 있다는 이야기로 이해했다. )
따라서 Ealier layer에서 26 x 26 resolution의 feature을 passthrough하여 사용한다.
Higer feature와 lower feature를 concat해서 사용하는데 이를 통해서 저해상도와 고해상도의 서로 다른 channels 정보를 활용한다.
Multi-Scale Training
오리지널 YOLO는 448 x 448을 input resolution으로 사용하고 YOLO v2는 416 x 416을 사용한다.
입력 이미지 크기를 고정하는 대신에 이를 약간씩 변화시킨다.
매 10 배치마다 네트워크는 무작위로 downsample을 수행한다. 이는 Factor 32를 사용한다.
이는 32의 배수 중에서 하나를 뽑아서 이미지의 크기를 resize한다.
{320, 352, ..., 608} 중에서 하나를 매 10배치 마다 뽑는다.
그 다음 이미지 크기를 재조정한다.
가장 작은 이미지 크기는 320 x 320이고 가장 큰 경우는 608 x 608이다.
Experiments

YOLOv2 그리고 입력 이미지의 크기가 544 x 544 크기인 경우 mAP가 가장 좋다.
Table 3를 보면 입력 이미지가 커질수록 mAP는 증가하지만 FPS는 숫자가 작아짐을 알 수 있다.
속도와 정확도는 서로 트레이드 오프 관계다.

YOLOv2 544의 성능이 대체로 SOTA인 SSD512, ResNet과 비슷하다.

COCO에 대해서는 YOLOv2의 성능이 다소 부족함을 알 수 있다.
3. Faster
Darknet-19
YOLOv2에 기반한 새로운 classification model을 제안한다.
Network in Network에 기반해서 global average pooling (GAP) 그리고 1 x 1 filters를 사용한다.
그리고 Batch normalization을 사용해서 학습의 안정화, 수렴 속도의 증가, 모델의 regularization을 달성하낟.
구체적인 구조는 다음의 Table 6에 나와있다.

Training for Classification
ImageNet의 1000개의 클래스 예측에 대해 학습한다.
160 epochs, SGD, lr은 0.1, polynomial rate decay with power of 4, weight decay는 0.0005, momentum은 0.9다.
입력 이미지는 224 x 224지만 fine tune할 때는 448 x 448의 더 큰 이미지를 활용한다.
Fine tuning에서는 10 epochs를 학습하며 lr은 1e-3이다.
Top-1 accuracy는 76.5%, top-5 accuracy는 93.3%다.
Training for Detection
마지막 conv layer를 삭제하고 3 x 3 conv 3개 with 1024 filters를 더하고 마지막에 1 x 1 conv layer를 덧붙여서 detection에 필요한 output의 개수를 맞춘다.
VOC에 대해서 5개의 박스와 5개의 좌표를 예측하고 총 20개의 클래스가 있으므로 박스 마다 125개의 필터가 필요하다.
추가적으로 passthrough에 필요한 3 x 3 x 512 layer는 뒤에서 두번째 위치에 놓는다.
이를 통해서 fine-grained features를 얻는다
160 epochs, SGD, lr은 $$10^{-3}에서 시작해서 60과 90 epochs에서 각각 10으로 나눈다.
그리고 weight decay는 0.0005, momentum은 0.9다.
VOC와 COCO 데이터 모두 동일하게 위에서 언급된 학습 전략을 선택한다.
4. Stronger
Conditional proability의 측면에서 클래스를 예측한다.
여러 클래스를 더 큰 범주로 묶은 다음에 이를 계층적으로 분류한다.



ImageNet와 COCO의 데이터를 섞어서 함께 더 큰 범주들로 묶은 다음 학습해서 예측하는 경우가 Figure 6이다.

최상과 최악의 결과는 위 Table 7과 같다.
Loss function
위 두 링크를 통해서 YOLO v2의 loss에 대한 코멘트를 짤막하게 남긴다.
x, y, h, w 그리고 classification prob, confidence (IOU)의 차이를 모두 SSE (Sum of Squrares Error)의 측면에서 계산하고
이를 통해서 정답에 근접하도록 loss 함수를 설정한다.
특이한 점은 object가 검출되지 않는 지점에 대해서도 loss를 설정하고 학습한다는 점이다.
이는 object 위에 있지 않은 cell들에 대해서도 모델이 학습을 하도록 만들기 위함이다.
'Computer Vision' 카테고리의 다른 글
| ViT Vision Transformer(2021) 논문 리뷰 (1) | 2025.04.08 |
|---|---|
| YOLO v3 (2018) 논문 리뷰 (0) | 2025.04.08 |
| EfficientNet (2019) 논문 리뷰 (0) | 2025.04.08 |
| MobileNet (2017) 논문 리뷰 (0) | 2025.04.08 |
| DeepLab v2 (2016) 논문 리뷰 (0) | 2025.04.08 |



