CoT는 Chain of Thought의 약자로 논문의 이름은 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models다. (링크)
저자는 Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou다.
LLM reasoning의 목적으로 prompting 혹은 prompt engineering으로 달성한 논문이다.
구글의 PaLM 부터 LLaMa 2, GPT-4 등등 수많은 LLM에서 사용한 프롬프팅 기법이다.
Abstract
CoT Chain of thought는 단계적으로 reasoning 추론을 이어나가면서 LLM의 복잡한 추론의 성능을 올리는 방법이다.
Arithmetic, commonsense, symbolic reasoning 산술, 상식, 기호 추론의 문제들에 테스트를 수행했다.

Figure 1을 보면 알 수 있겠지만 중간 단계에서 어떻게 추론을 하는지에 대한 예시를 구체적으로 적어준다.
아래의 Figure 3에서는 산술, 상식, 기호 추론의 문제 상황에 따른 CoT의 예시를 보여준다.
즉 <input, chain of thought, output>의 triple을 보여준다.
저자들은 GPT-3, LaMDA, PaLM, UL2 20B, Codex의 모델을 가지고 성능을 비교했다.
Ablation Study
수학 문제에서 다음의 경우를 비교했다.
- 수식만 생성하도록 지시
- 변수의 계산 값만을 생성
- 답변 후 이유를 설명
- CoT
Figure 5를 보면 CoT의 성능이 LaMDA과 PaLM 모두에 있어서 더 좋았다.
Figure 6을 보면 서로 다른 주석에 따라서 CoT의 성능이 변동성을 갖지만 일반적인 프롬프트 보다는 좋은 성능임을 알 수 있다.
Experimental Results
Figure 4, 7, Table 1은 CoT와 일반적인 프롬프트의 성능 비교를 보여준다.
성능 테이블은 워낙 많아서 다 붙여넣는건 좋지 않고 핵심적인 사양만 요약하고자 한다.
CoT in Larger Model
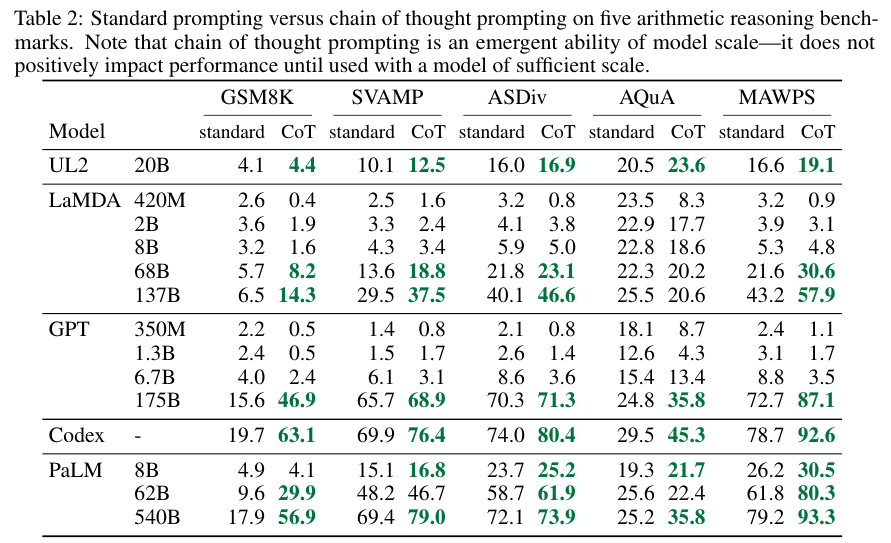
Table 2를 보면 알겠지만 모델의 사이즈가 작으면 오히려 일반적인 프롬프트의 성능이 더 좋은 결과가 나오기도 한다.
모델의 사이즈가 크면 클수록 CoT가 일반 프롬프트 보다 더 좋은 경향성을 보인다.
(AQuA 데이터에 대한 LaMDA 같은 예외 케이스가 있지만)
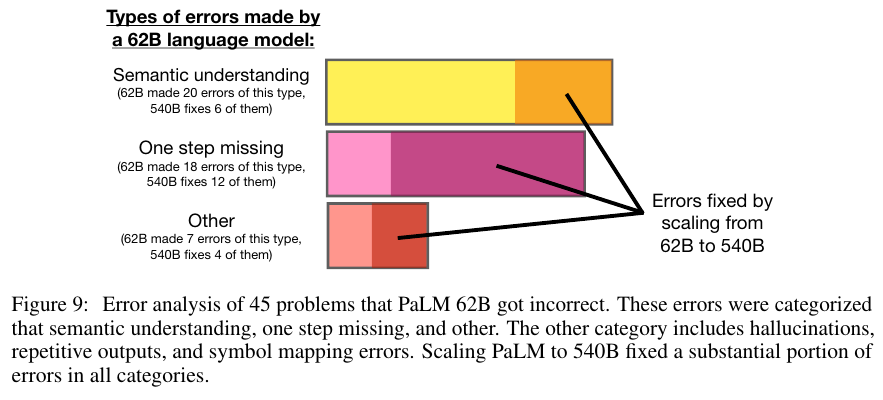
CoT의 적용에 있어서 발생하는 에러는 Semantic understanding, One step missing, Others로 구분할 수 있다.
이때 PaLM을 예로 들어서 모델을 62 B에서 540 B로 크기를 키웠더니 에러가 해결되었다고 한다.
아래 Figure 9와 Figure 10에 그 내용이 나와있다.

추가적으로 CoT, ToT, GoT 같은 내용 이외의 LLM reasoning을 모아둔 github 링크를 발견해서 공유하며 마무리한다. (링크)
'NLP > Prompt & Problem Solving' 카테고리의 다른 글
| ChartInstruct (2024) 논문 리뷰 (0) | 2025.04.27 |
|---|---|
| Tree-of-Thought ToT (2023) 논문 리뷰 (0) | 2025.04.27 |
| Lost in the Middle (2023) 논문 리뷰 (1) | 2025.04.27 |
| Plan and Solve (2023) 논문 리뷰 (1) | 2025.04.19 |
| CoT-SC (2022) 논문 리뷰 (0) | 2025.04.18 |



