Plan and Solve의 논문 이름은 Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models다. (링크)
저자는 Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, Ee-Peng Lim다.
Abstract
LLM은 최근 NLP 태스크에 대해서 놀라운 성과를 거두었지만 multi-step reasonong tasks에서 문제 상황을 맞주했고 이를 해결하귀 위해서 few-shot Chain-of-Thought (CoT) 프롬프팅은 몇 개의 수작업으로 생성된 step-by-step 점진적인 추론의 시범 설명을 포함한다.
수작업을 제거하기 위해서 Zero-shot-CoT는 목표 문제 서술과 "Let's think step by step" 같은 입력을 함께 LLM에 넣는다.
Zero-shot-CoT은 성공적이었지만 3가지 위험이 존재한다. Calculation error, missing-step errors, and semantic misunderstanding error 계산 오류, 단계 누락 오류, 의미론적 오해 오류다.
Missing-step error를 해결하기 위해서 저자들은 Plan-and-Solve (PS) Prompting을 제안한다.
두 가지 구성요소로 이루어져있는데, 첫 번째 요소는 entire task 전체 태스크를 smaller subtasks 더 작은 하위태스크로 고안한다. 두 번째로는 쪼갠 하위태스크를 plan 계획에 따라서 실행하는 작업이다. 계산 오류에 대처하고 생성된 추론 단계의 향상을 위해서 PS prompting을 확장하는데 이는 디테일한 instructions 지시를 포함하는 PS+ prompting이다.
세 가지 추론 문제에 대해서 총 10개의 데이터셋에 대해서 실험을 했으며 기반이 되는 LLM은 GPT-3다.
2. Plan-and-Solve Prompting
Few-shot CoT와 비교한다.
구체적인 Plan-and-Solve, PS prompting와 Zero-shot-CoT의 비교는 아래 Figure 2에 나와있다.

2.1. Step 1: Prompting for Reasoning Generation
정확하지 않은 계산과 추론 과정의 누락으로 부터 생기는 오류를 방지하기 위해서 현재 단계에서는 다음의 두 가지 기준을 만족하는 템플릿을 구축한다.
- 템플릿은 LLM으로 부터 하위태스크를 결정하고 이를 완수해야 한다.
- 템플릿은 LLM이 계산과 중간 결과에 주의를 기울이고 최대한 올바르게 작동하도록 해야 한다.
첫 번째 기준을 만족하기 위해서 Zero-shot CoT를 따라서 입력 데이터 예시를 간단한 프롬프트에 집어넣는다.
"Q: [X]. A: [T]"
입력 슬롯 [X]는 입력 문제 서술이며 수작업으로 작성된 지시는 [T]에 들어가서 LLM으로 하여금 추론 과정을 생성하며 이 추론 과정은 계획과 계획을 완료하기 위한 단계를 포함한다.
Zero-shot-CoT에서 지시는 다음의 trigger instruction 촉발 지시 "Let's think step by step"을 포함한다.
하지만 Zero-shot PS prompting에서는 대신 "devise a plan"과 "carry out the plan"을 포함한다.
따라서 최종 프롬프트는 다음과 같다.
"Q: [X]. A: Let's first understand the problem and devise a plan to solve the problem.
Then, let's carry out the plan and solve the problem step by step."
Zero-shot-CoT처럼 PS prompting 역시 greedy decoding strategy (1 output chain)을 따라서 출력을 생성한다.
두 번째 기준을 만족하기 위해서 계획 기반 촉발 문장을 보다 디테일한 지시로 변경한다.
구체적으로 "pay attention to calculation"을 촉발 문장에 추가한다.
필요한 추론 단계의 누락을 방지하기 위해서 "extract relevant variables and their corresponding numerals"를 명시적으로 LLM에게 지시하여 입력 문제 서술에 연관된 정보를 무시하기 않도록 만든다.
저자들은 만약 LLM이 관련있거나 중요한 변수를 생략한다면 연관있는 추론 단계 역시 생략하는 경향이 있다는 가설을 세운다.
Figure 5에서 이에 대한 실증적 증거를 보여준다.
추가적으로 "calculate intermediate results" 프롬프트를 추가해서 LLM이 연관성이 있고 중요한 추론 단계를 생성하는 능력릉 향상시킨다.

Figure 3 (b)에 예시가 있는데 바로 "Combined weight of Grace and Alex = 125 + 498 = 623 pounds"다.
이 전략은 특정 묘사를 촉발 문장에 추가해서 복잡한 추론에서의 zero-shot 성능을 향상시키는 새로운 방법이다.
2.2. Step 2: Prompting for Answer Extraction
Zero-shot-CoT와 비슷하게 LLM이 최종적인 숫자 형태의 답변을 Step 1에서 추론을 거치면서 생성된 추론 텍스트에서 추출한다.
이 프롬프트에는 답변 추출 지시를 LLM에 의해 생성된 추론 텍스트의 뒤에 있는 첫 번째 프롬프트에 덧붙인다.
이를 통해서 LLM이 원하는 최종 답변을 생성하리라 기대한다.
Figure 3 (b)에서 Step 2에 사용된 프롬프트는 아래와 같다.
"Q: Grace weighs 125 pounds ... Variables: Grace: 125 pounds ... Answer: Combined weight of Grace and Alex = 125 + 498 = 623 pounds. Therefore, the answer (arabic numerals) is". 예를 들어서 LLM이 반환한 최종 답변은 "623"이다.
3. Experimental Setup
3.1 Benchmarks
Arithemetic Reasoning:
GSM8K
SVAMP
MultiArhith
AddSub
AQUA
SingleEq
Commonsense Reasoning:
CSQA
StartegyGQ
Symbolic Reasoning:
the Last Letter Concatenation
Coin Flip
3.2 Zero-shot and Few-shot Baselines
- zero-shot-CoT
- zero-shot-PoT
- Manual-CoT
- Auto-CoT
Auto-CoT를 따라서 public GPT-3를 활용한다.
다음에 대해서는 8개의 demenstration examples를 사용한다.
MultiArhith, GSM8K, AddSub, SingleEq, SVAMP
다음에 대해서는 4개다.
AQuA, Last Letters
다음에 대해서는 7개다.
CSQA
다음에 대해서는 6개다
StrategyQA
Manual-CoT를 따라서 모든 데이터의 방법에 대해서 accuracy를 보고한다.
4. Experimental Results

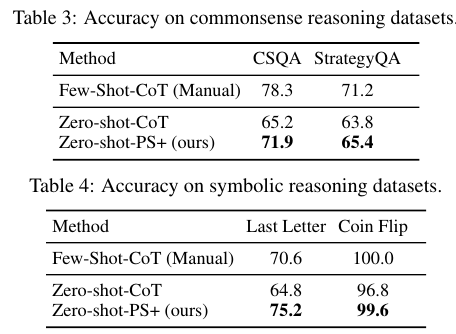
Table 2, 3, 4에서는 Plan and Solve가 기존의 방법들에 비해서 대체로 좋은 성능임을 보여준다.
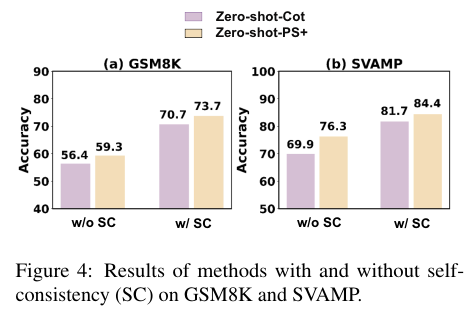
Figure 4에서는 PS prompting에 Self-consistency (SC)를 활용한 성능이 더 좋음을 보여준다.
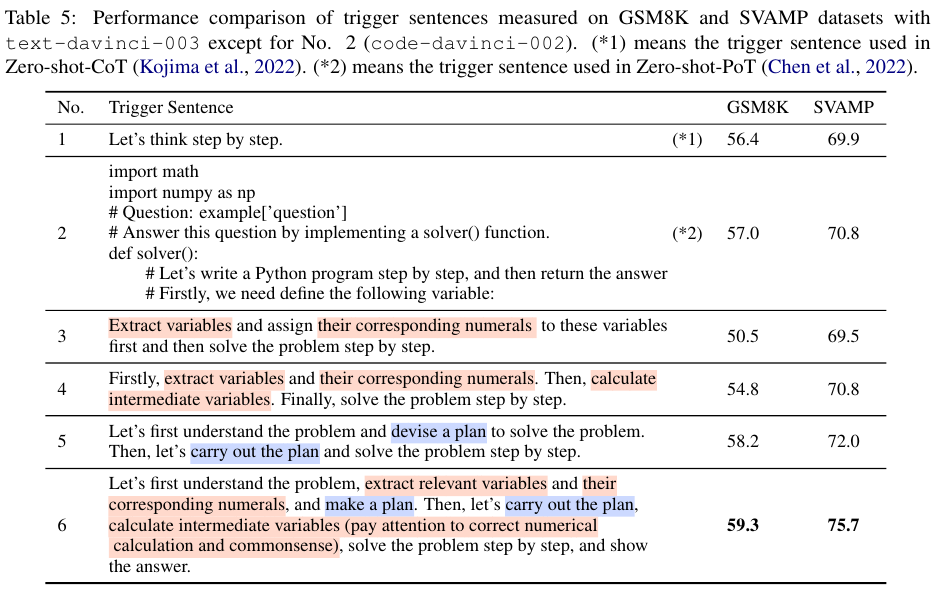
Table 5에서는 trigger sentence를 어떻게 구성하느냐에 따라 어떻게 성능이 다른지에 대한 비교 결과를 보여준다.
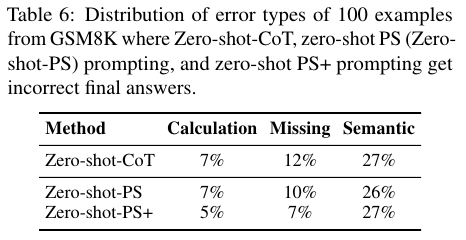
Table 6에서는 계산 오류, 누락 오류, 의미 오류의 관계를 보여주는데 고품질의 추론이 더 작은 계산 오류의 결과를 도출함을 알 수 있다.
다음의 Table 7, 8, 9는 데이터셋 별 프롬프트의 예시를 일부 보여준다.

'NLP > Prompt & Problem Solving' 카테고리의 다른 글
| ChartInstruct (2024) 논문 리뷰 (0) | 2025.04.27 |
|---|---|
| Tree-of-Thought ToT (2023) 논문 리뷰 (0) | 2025.04.27 |
| Lost in the Middle (2023) 논문 리뷰 (1) | 2025.04.27 |
| CoT-SC (2022) 논문 리뷰 (0) | 2025.04.18 |
| CoT Chain-of-Thought (2022) 논문 리뷰 (0) | 2025.04.16 |



