LLM as a Judge는 Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena 논문에서 소개된 방법이다. (링크)
저자는 Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, Ion Stoica다.
LLM as a Judge의 핵심 개념은 간단하다. LLM으로 다른 LLM을 평가한다.
논 논문에서는 MT-bench와 Chatbot Arena (HF Chatbot Arena Leaderboard 링크) 으로 평가를 수행했다.
Chatbot Arena Leaderboard: (링크)
Abstract
강력한 성능의 LLM으로 보다 많은 open-ended 질문에 대한 평가를 수행한다.
LLM as a judge의 유용성과 한계점을 검토한다.
MT-bench로 멀티턴 질문 세트와 Chatbot Arena로 크라우드 소스 기반 배틀 플랫폼에서의 성능을 살펴본다.
GPT-5처럼 강력한 LLM들은 통제되고 크라우드 소스에 기반한 human preferences에 비견할만하다.
이는 80% 이상의 동의를 받았다. (achieving over 80% agreement).
Github page (링크)

Figure 1은 한 명의 유저와 2 개의 AI assistants의 대화다.
GPT-4가 두 AI 어시스턴트에 대해서 평가를 수행한다.
2. MT-Bench and Chatbot Arena
2.1. Motivation
현존하는 벤치마크의 구분
Core-knowledge benchmarks:
MMLU, HellaSwag, ARC, WinoGrande, HumanEval, GSM-8K, AGIEval
Instruction-following benchmarks:
Flan, Self-instruct, NaturalInstructions, Super-NaturalInstructions
Conversational benchmarks:
CoQA, MMDialog, OpenAssistant
2.2. MT-Bench
총 80개의 고품질의 멀티턴 질문을 포함한다.
멀티턴 대화, instruction-following, 상식과 어려운 질문에 대한 답변 능력을 평가한다.
총 8개의 Writing, roleplay, extraction, reasoning, math, coding, knowledge 1 (STEM), knowledge 2 (humanities, social science) 범주로 구성한다. 저자들은 개별 범주에 대해서 10개의 멀티턴 질문으로 디자인하는데 수작업으로 진행했다.
Table 1에 예시가 나와있다.

2.3. Chatbot Arena
유저는 두 개의 알 수 없는 모델과 동시에 상호작용하며 선호하는 답변에 투표한다.
한 달 동안 30K의 투표수를 모았다.
3. LLM as a Judge
3.1 Types of LLm-as-a-Judge
Pairwise comparison
하나의 질문에 두 개의 답변을 비교한다.

Single answer grading
하나의 답변에 대해 점수를 표기한다.

Reference-guided grading

레퍼런스로 사용한 답변을 준다.
3.2. Advantages of LLm-as-a-Judge
scalability와 explainability에서 장점을 지닌다.
사람이 개입할 필요가 줄어서 더 빠르고 규모가 큰 벤치마크가 가능하다.
3.3. Limitations of LLm-as-a-Judge
Position bias
후보 답변의 배치의 순서와 위치에 따라서 다르게 평가한다.


Verbosity bias
길고 장황한 답변을 선호하는 현상

Self-enhancement bias
모델 스스로가 답변한 내용을 더 선호하는 현상
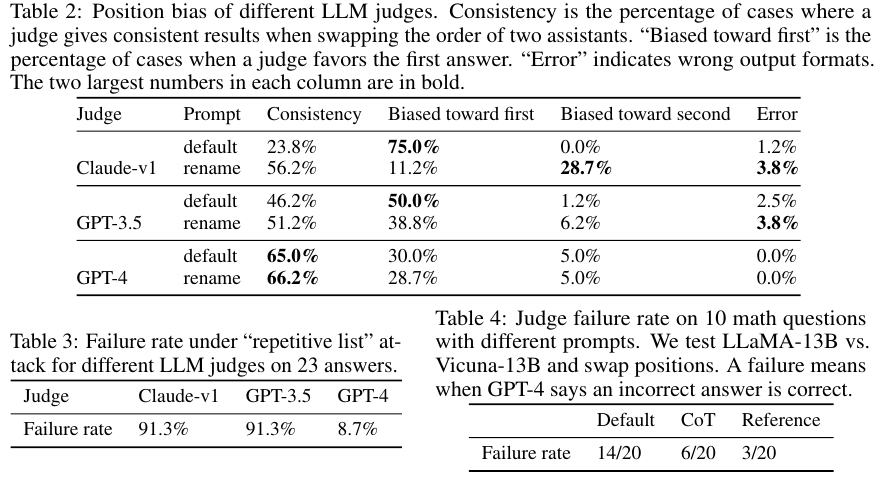
3.4. Addressing limitatoins
Swaping positions
처음 답변을 평가한 다음에, 두 답변의 위치를 변경한 후 다시 답변을 평가한다.
또 다른 방법으로는 답변의 위치를 랜덤하게 할당한다.
Few-shot judge

Chain-of-though and reference-guided judge

Fine-tuning a judge model
저자들의 경우에 Vicuna-13B를 평가자 모델로 선택하고 파인 튜닝했다.
Multi-turn judge
아래는 멀티턴 대화에 대한 평가 프롬프트의 예시다.

4. Agreement Evaluations
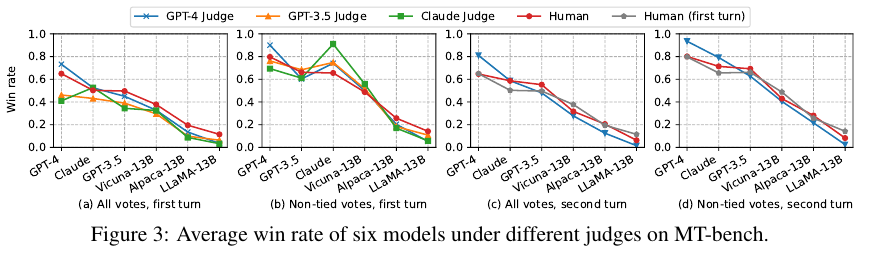

전반적으로 GPT-4가 사람과 유사하게 평가한다.
LLM을 평가자로 사용할 때의 잠재적인 약점을 잘 고려해서 사용해야 한다는 점을 명심해야 한다.
References:
https://tech.kakao.com/posts/690
https://devocean.sk.com/blog/techBoardDetail.do?ID=166628&boardType=techBlog
'NLP > NLP - Data & Eval' 카테고리의 다른 글
| RAGAS (2023) 논문 리뷰 (0) | 2025.04.17 |
|---|---|
| Pre-train 데이터 정리 (0) | 2025.04.11 |
| GLUE, SuperGLUE, KLUE, Huggingface LB (0) | 2024.03.04 |


