LayoutLM v3 모델의 논문 제목은 LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking이다. (링크)
저자는 Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei 다.
이 논문은 LayoutLM v3으로 세 번째 버젼의 논문이다.
Abstract
Self-supervised learning은 문서 AI 분야에서 놀라운 성과를 거두었다. 대부분의 멀티모달 pre-trained models는 masekd language modeling의 objecttive를 기반으로 bidirectional representation을 text modality에 대해서 학습했으나 image modality에 대해서는 다르게 학습했다. 이러한 discrepancy 불일치는 멀티모달 representation learning에 있어서 어려움을 더하는데 본 논문에서 제시된 LayoutLMv3는 통일된 텍스트와 이미지 마스킹을 활용한 문서 AI Transformer 모델이다. 추가적으로 wrod-path alignment objective를 통해서 cross-modeal alignment를 학습하고 이를 통해서 텍스트 글자가 마스킹된 부분의 이미지를 예측한다. Text-centric과 image-centric라는 문서 AI의 두 가지 태스크에 대해서 모두 작동하는 general model 일반화된 모델이다. LayoutLMv3는 text-centric 태스크들; understanding, recipt understanding, document visual question answering 뿐만 아니라 image-centric 태스크들; document image classification, 그리고 domcunet layout analysis에 대해서도 SOTA 성능을 거두었다.
아래 Figure 1에서는 text-centric 태스크의 일종인 understanding과 image-centric 태스크의 하나인 layout analysis를 그림으로 보여주고 있다.

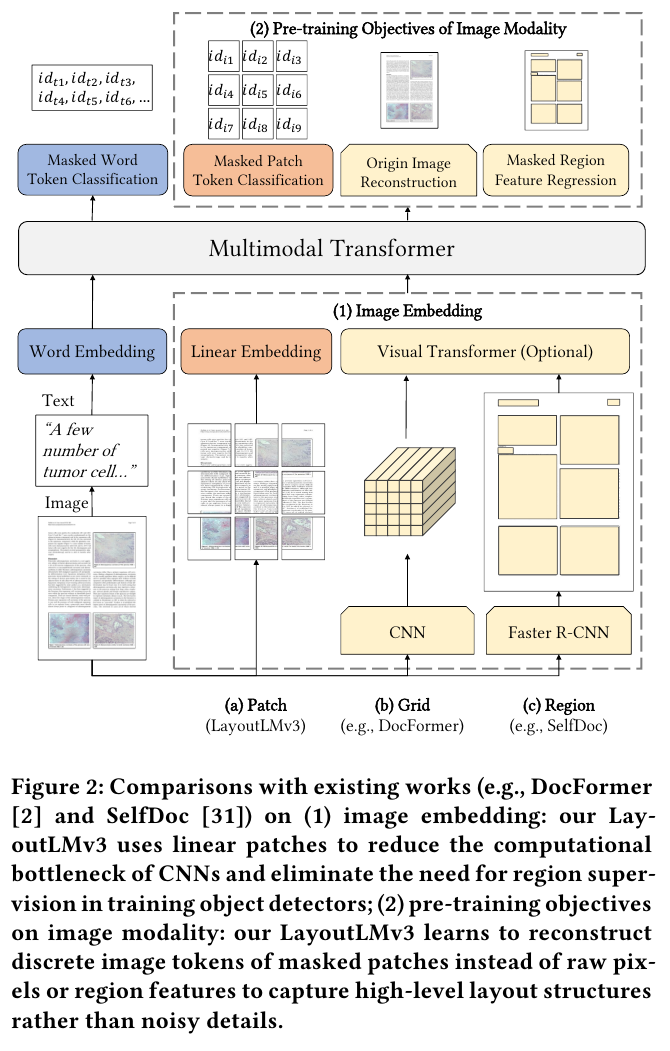
아래 Figure 2에서는 SelfDoc, DocFormer, LayoutLMv3의 아키텍처를 비교하고 있다.
(b)의 DocFormer는 Image에서 reconstruction을, (c)의 SelfDoc은 masked region feature regression을 수행하지만 LayoutLMv3에서는 이미지에 대한 masked patch token classification을 수행한다.
2. LayoutLMv3
LayoutLMv3의 전반적인 구조는 아래 Figrue 3에 나와있다.

2.1. Model Architecture
Transformer에 들어가는 입력은 text embedding $\text{Y} = \text{y}_{1:L}$과 $\text{X} = \text{x}_{1:M}$의 concat이고 각각 $L$과 $M$의 sequence length를 갖는다.
Text Embedding
사전 학습된 RoBERTa의 word embeddings와 1D position embeddings과 2D position embeddings를 사용한다.
1D position embeddings는 text sequence에 대한 position을 나타내며, 2D는 문서 이미지 상에서의 postion 정보인데 이는 문서 이미지 상의 텍스트에 대한 bounding box (bbox)의 좌표다. LayoutLM과 마찬가지로 이미지의 크기에 따라서 normalized된 좌표 값을 가지며 x-axis와 y-axis 각각에 대한 embeddings를 별도로 갖는다. LayoutLMv1과 v2는 word-level input positions를 사용했지만 v3에서는 segment-level layout position을 사용한다. 이는 segment 상에서 같은 위치에 위치한 words 단어들이 서로 같은 semantic meaning을 갖기 때문이다.
Image Embedding
기존의 문서 AI는 CNN grid features를 사용하거나 Faster F-CNN 같은 object detector에 의존하여 region features를 추출한다. 하지만 이는 coputation bottleneck이며 region supervision이 필요하다. 본 논문에서는 대신 ViT와 ViTL에 영감을 받아서 document images를 patch 단위로 자른 다음 linear projection을 거쳐서 생성된 features를 사용한다.
Image $I \in \mathbb{R}^{C \times H \times W}$가 있을 때, P x P pathces로 분할한다.
이를 flatten하여 $D$-dim으로 변환하게 되면 그 sequence length $M$은 $HW$ / $P^2$이 된다.
2D position embeddings는 이전의 연구에서 개선이 없었기 때문에 대신 1D postion embedding을 더한다.
1D relative position과 2D relative position biases를 LayoutLMv2에서 한 것과 동일하게 적용한다.
2.2. Pre-training Obejctives
Obejctive 1: Masked Language Modeling (MLM)
BERT의 MLM과, LayoutLMv1과 v2의 MVLM에 따라서 30%에 해당하는 span masking 전략을 사용한다.
이때 span lengths는 Possion distribution ($\lambda = 3)$에 따라서 샘플링을 수행한다.
Objective function은 correct masked tokens $\text{y}_l$의 log-likelihood의 최대화다.
이대 corrupted sequences of image tokens는 $\text{X}^{M'}$, text tokens는 $\text{Y}^{L'}$로 나타내며, $M'$와 $L'$는 각각 masked positions를 나타낸다. Transformer 모델의 parameters를 $\theta$라고 할 때 다음의 cross-entropy loss를 최소화한다.
$L_{MLM}(\theta) = - \sum_{l = 1}^{L'} \text{log} p_{\theta} ( \text{y}_l | \text{X}^{M'}, \text{Y}^{L'} )$
Obejctive 2: Masked Image Modeling (MIM)
모델이 conextual text와 image representation에서 visual content를 해석하기를 장려하기 위해서 BEiT 논문 (링크)에서 사용한 MIM pre-training objectives를 모델에 적용한다. 40% 이미지 토큰에 대해서 blockwise 전략을 따라서 랜덤하게 마스킹을 수행한다. MIM obejctive는 masked image tokens $\text{x}_m$에 대한 reconstruction을 목적으로 하는 cross-entropy loss다.
$ L_{MIM}(\theta) = - \sum_{m = 1}^{M'} \text{log} p_{\theta} ( \text{x}_m | \text{X}^{M'}, \text{Y}^{L'} )$.
이미지 토큰의 라벨은 이미지 토크나이저로 부터 나오는데, 이는 dense image pixels를 visual vocabulary에 의해 discrete tokens 들로 변환한다. 따라서 MIM은 high-level layout structures를 활용한다.
이는 DALL-E 논문 (링크)에 나온 방법을 따른다.
Obejctive 3: Word-Patch Alignment (WPA)
MLM과 MIM에서는 text와 image modalities 사이의 alignment learning이 명시적으로 나와있지 않다.
따라서 WPA를 통해서 text words와 이미지 image patch 사이의 fine-grained alignment learning을 도모한다.
Unmasked text token과 이에 해당하는 image tokens 역시 unmasked라면 aligned로 라벨링한다. 그외의 경우에는 unaligned로 라벨링한다. WPA loss 계산시에 masked text tokens를 배제하는데 이는 모델의 masked text words와 그에 해당하는 이미지를 학습하지 않게 하기 위함이다. Two-layer MLP head를 사용해서 contextual text와 image를 input으로 하고 output으로 binary aligned / unaligned labesl를 생성하고 이를 cross-entropy loss를 계산한다.
$L_{WPA}(\theta) = - \sum_{l = 1}^{L - L'} \text{log} p_{\theta} ( \text{z}_l | \text{X}^{M'}, \text{Y}^{L'} )$
이때, $L - L'$는 unmasked text tokens의 수이며, $z_l$은 binary label of language token in the $l$ position이다.
3. Experiments
3.1. Model Configurations
Transformer의 encoder 구조를 사용했으며 Base와 Large 모델이 있다.
Base는 12-head self-attention, hidden size $D$가 768, FFN에서 3,072의 크기를 갖는다.
Large에서는 24-head self-attention, hidden size $D$가 1,024, FFN에서 4,096의 크기를 갖는다.
토크나이저로는 BPE를 사용했으며 maximum sequence length는 512다.
[CLS]를 문장의 맨 앞에, [SEP]를 문장의 맨 뒤에 위치시킨다. 문장의 길이가 512 이하인 경우 [PAD] 토큰을 이용해서 문장의 길이를 512로 맞춘다.
Bbox의 좌표는 스페셜 토큰에 대해서 모두 0이다.
이미지 임베딩이 대해서는 $C \times H \times W$ = 3 x 224 x 224이며, P = 16이고, M = 196이다.
Mixed-precision을 사용했으며 CogView에 따라서 self-attention을 계산할 때 다음의 계산을 적용한다.
softmax($\frac{Q^TK}{\sqrt{d}}$) = softmax( ($\frac{Q^TK}{\alpha \sqrt{d}}$ - max( $\frac{Q^TK}{\alpha \sqrt{d}}$ ) ) $\times \alpha $)
이때 $\alpha$는 32다.
3.2. Pre-training LayoutLMv3
IIT-CDIP Text Collection 1.0에 대해서 pre-train을 수행했다.
Image tokens에 대한 Vocab size는 8,192로 설정했다.
Base의 경우 Adam을, batch size를 2,048을, weight decay를 1e-2, ($\beta_1, \beta_2$) = (0.9, 0.98)을 사용했다.
linearly warm up lr을 처음 4.8%의 스텝에 대해서 수행했다.
Large의 경우 lr을 5e-5, warm-up ratio를 10%로 설정했다.
3.3. Fine-tuning on Multimodal Tasks
[T] text modality
[T+L] text and layout modalities
[T+L+I(R)] text, layout, and image modalities with Faster R-CNN region features
[T+L+I(G)] text, layout, and image modalities with CNN grid features
[T+L+I(P)] text, layout, and image modalities with linear patch features
다른 모델들과 실험 결과는 다음의 Table 1과 2에 나와있다.


대부분의 경우에서 LayoutLMv3가 가장 좋은 성능을 달성했음을 알 수 있다.
'Multimodal' 카테고리의 다른 글
| LLaVA (2023) 논문 리뷰 (0) | 2025.04.26 |
|---|---|
| BLIP (2022) 논문 리뷰 (0) | 2025.04.26 |
| LayoutLM v2 (2020) 논문 리뷰 (1) | 2025.04.24 |
| LayoutLM v1 (2019) 논문 리뷰 (0) | 2025.04.16 |
| CLIP (2021) 논문 리뷰 (0) | 2025.04.11 |



