BLIP 모델의 논문 제목은 BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation이다. (링크)
저자는 Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi다.
Abstract
Vision-Language Pre-training (VLP)는 vision-language tasks에서 성능의 향상을 보여왔다. 하지만 현존하는 많은 방법들은 understanding-based tasks 혹은 generation-based tasks 어느 한쪽에서만 향상을 보이고 있다. 뿐만 아니라 대부분의 성능 향상은 웹에서 가져온 noisy image-text pairs를 사용하여 데이터의 크기를 늘리는 방식이기 때문에 supervision의 측면에서 suboptimal이다. 따라서 해당 논문에서 제시한 BLIP은 vision-language의 이해와 생성 양쪽으로 전환할 수 있으며 bootstrapping 부트스트래핑 방법으로 captioner가 노이지한 캡션을 지우고 새로 생성하는 방식을 사용했다. 이를 통해서 image-text retireval, image captioning, VQA 등의 분야에서 SOTA를 달성했다.
Captioner의 동작의 예시는 다음의 Figure 1과 같다.

3. Method

BLIP 모델의 구조는 위 Figure 2와 같다.
3.1. Model Architecture
ViT를 image encoder로 사용했다. 이미지를 패치로 나눈 다음 sequence of embeddings로 만든다. 그리고 [CLS] 토큰을 global feature로 사용한다.
저자들은 이해와 생성의 능력을 모두 가진 통합된 모델을 위해서 Multimodal mixture of encoder-decoder (MED)를 추가한다. 이는 다음의 세 가지 기능으로 동작한다.
(1) Unimodal encdoer:
텍스트와 이미지를 따로 따로 인코딩한다. BERT와 같다.
(2) Image-grounded text encoder:
추가적인 cross-attention (CA)를 self-attention (SA) 레이어와 feed-forward network (FFN) 레이어 사이에 삽입해서 visual information을 추가한다. 이를 위해서 텍스트의 위로 [Encode] 라는 특수한 토큰을 사용한다. [Encode] 토큰의 output은 이미지-텍스트 페어의 multimodal representation으로 사용한다.
(3) Image-grounded text decoder:
Bidirectional SA 레이어를 Causal SA 레이어로 대체해서 만든다. [Decode] 토큰을 sequence의 앞에 넣어서 문장이 시작되는 것을 알린다. 그리고 end-of-sequence 토큰을 이용해 sequence의 끝임을 알린다.
3.2. Pre-training Objectives
Pre-train 과정에서 ITC, ITM, LM이라는 세 가지 loss를 사용한다.
Image-Text Contrastive Loss (ITC)
ITC는 unimodal encoder를 화성화한다. Visul transformer와 text transformer가 positive 이미지-텍스트 쌍을 similar representations 비슷하게 표현을 갖도록 하고, negative 쌍에 대해서는 비슷하지 않도록 만든다.
Image-Text Matching Loss (IMC)
이미지-텍스트의 멀티모달 표현을 학습하며 시각과 언어 사이의 fine-grained alignment를 포착한다.
Binary classification task이며 ITM head (Linear layer)를 통해서 이미지-텍스트 페어가 positive (matched)인지 negative (unmatched) 인지를 예측한다. Align before fuse: Vision and Language representation learning with momentum distillation 논문 (링크) 에 나온대로 Hard negative mining strategy를 따랐다.
Language Modeling Loss (LM)
LM은 image-grounded text decoder를 활성화하며 주어진 이미지에 대한 텍스트 설명 생성에 초점을 맞춘다.
Autoregressive의 측면에서 log likelihood의 최대화를 이용해서 cross entropy를 최적화한다.
Label smoothing 0.1을 적용한다.
3.3. CapFit
Annotation cost 때문에 고품질의 데이터는 COCO 등의 제한된 크기의 데이터만 존재한다.
이를 해결하기 위해서 Captioning and Filtering (CapFilt)를 제안한다.
자세한 방법은 아래 Figure 3와 같다.

Captioner는 주어진 웹 이미지에 대한 설명을 생성하고 filter는 노이지한 이미지-텍스트 페어를 제거한다.
Captioner와 Filter 모두 동일한 pre-trained MED 모델로 부터 나오며 각각 별도로 COCO 데이터 셋에 대해서 파인 튜닝한다.
Captioner를 LM objective의 측면에서 학습되며 주어진 이미지에 대한 캡션을 디코딩한다.
Filter는 imgae-grounded text conder다. ITC와 ITM 목적함수를 통해서 텍스트가 이미지와 매치되는지를 학습한다.
필터는 오리지널 텍스트와 Captioner가 만든 synthetic texts 합성 텍스트 모두를 제거하며, 이때의 제거 기준은 LM 헤드가 텍스트가 이미지와 unmatched라고 판단했을 때다.
최종적으로 필터링된 이미지-텍스트 쌍을 사람이 annotated한 쌍들과 묶어서 새로운 데이터셋을 만들고 이를 새로운 모델의 pre-train에 사용한다.
4. Expreiments and Discussions
ViT-B / 16와 ViT-L / 16에 대해서 학습을 수행한다.
ViT-B에 대해서는 20 epochs, 배치 사이즈 2880, AdamW를 사용한다.
Weight decay는 0.05, learning rate는 warmed-up을 3e-4까지, 그리고 linear decay로 rate of 0.85까지 조정한다.
ViT-L에 대해서는 20 epochs, 배치 사이즈 2400, AdamW를 사용한다.
Weight decay는 0.05, learning rate는 warmed-up을 2e-4까지, 그리고 linear decay로 rate of 0.85까지 조정한다.
이미지는 랜덤 크롭으로 224 x 224를 pre-train 단계에서 사용하며 fine-tuning에서는 이미지 크기를 384 x 384로 확대한다.
COCO와 Visual Genome, 그리고 Conceptual Captions, Conceptual 12M, SBU captions, LAION의 데이터를 이용해서 pre-train을 수행했다.


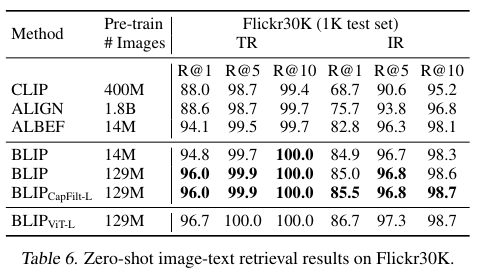
Table 6를 보면 CLIP 보다 좋은 성능인 점이 눈에 띈다.
'Multimodal' 카테고리의 다른 글
| DALL-E (2021) 논문 리뷰 (1) | 2025.05.03 |
|---|---|
| LLaVA (2023) 논문 리뷰 (0) | 2025.04.26 |
| LayoutLM v3 (2022) 논문 리뷰 (1) | 2025.04.25 |
| LayoutLM v2 (2020) 논문 리뷰 (1) | 2025.04.24 |
| LayoutLM v1 (2019) 논문 리뷰 (0) | 2025.04.16 |



