DALL-E 모델의 논문 이름은 Zero-Shot Text-to-Image Generation다. (링크)
저자는 Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever다.
Github: 링크

Figure 2에서는 DALL-E 모델의 zero-shot의 예시를 보여준다.
2. Method
목적은 transformer을 학습해서 autoregressively 텍스트와 이미지 토큰을 단일한 데이터 흐름으로 모델링하는 것이다.
하지만 픽셀을 그대로 사용하는 것은 고해상도일 경우 과도한 양의 메모리를 요구한다. 따라서 우선 픽셀들 사이의 short-range dependencies를 우선적으로 likelihood objectives로 학습한다. 이를 통해서 low-frequency의 structure 대신 high-frequency details를 먼저 포착하도록 모델의 능력을 학습한다.
Stage 1. Discrete variational autoencoder (dVAE)를 학습해서 256 x 256 RGB 이미지를 32 x 32 크기의 이미지 토큰들로 이루어진 그리드로 압축한다. 각각은 총 8192개의 possible values를 가진다. 이를 통해서 transformer에 들어가는 context 사이즈를 192로 줄인다.
dVAE를 통한 압축 결과는 아래 Figure 1에 나와있는데 품질의 열화가 심하지 않다.

Stage 2. 256 BPE-encoded 텍스트 토큰을 32 x 32 = 1024 이미지 토큰과 concatenate up한다. 그 다음 autoregressive transformer을 학습해서 텍스트 토큰과 이미지 토큰의 joint distribution을 학습한다.
위 과정은 evidence lower bound (ELB)의 최대화를 통해서 달성한다.
Images $x$, captions $y$, tokens for the encoded RGB image $z$에 대한 joint dist는 다음과 같이 정의한다.
$p_{\theta, \psi}(x, y, z) = p_\theta(x | y, z) p_\psi (y, z)$다.
$ln \, p_{\theta, \psi}(x, y, z) \leq \mathbb{E}_{z \sim q_{\phi} (z | x)} ( ln \, p_\theta(x | y, z) ) - \beta D_{KL} ( q_{\phi} (y, z | x), p_\psi (y, z) )$.
$q_\phi$는 주어진 RGB 이미지 $x$에 대해서 dVAE 인코더가 생성한 32 x 32 이미지 토큰이다.
$p_\theta$는 dVAE 디코더가 주어진 이미지 토큰으로 생성한 RGB 이미지의 분포다.
$p_\psi$는 텍스트 토큰과 이미지 토큰의 joint distribuion modeled by transformer다.
실제로 적용할 때 $\beta = 1$이다.
2.1. Stage One: Learning the Visual Codebook
$q_\phi$는 categorical distribution이므로 ELB 최적화가 어렵다.
저자들은 Gumbel-Softmax relaxation를 활용해서 $q_\phi$을 $q_\phi^\tau$로 대체하고 temperature $\tau$를 0으로 만들고 likelihood $p_\theta$를 log-laplace distribution으로 평가한다. (Appendix A를 참조.)
2.2. Stage Two: Learning the Prior
텍스트-이미지 페어에 대해서 소문자화한 캡션에 대해서 BPE-encode를 적용했다.
Vocab size는 16,384이며 이미지는 32 x 32 = 1024 tokens로 vocab size는 3192다.
Text caption의 길이를 256으로 제한했다.
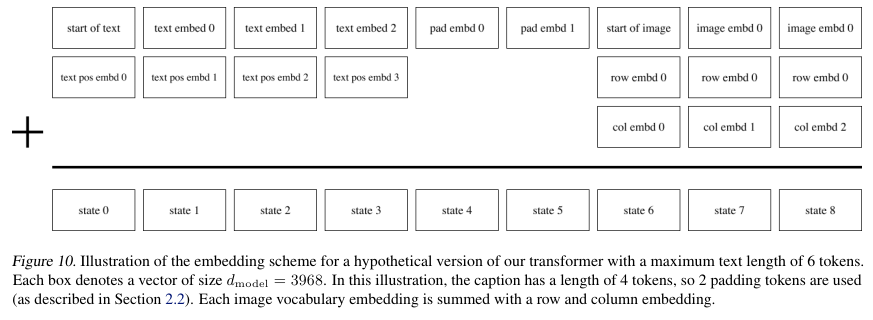
텍스트 토큰 끝과 이미지 토큰 시작점 사이의 padding의 위치가 애매했지만, 이를 logit에 대해서 $-\infty$로 설정하여 해결했다.
그리고 loss는 Cross entropy loss를 최적화했다.
구체적인 내역은 아래 Figure 10에 나타나있다.
2.3. Data Collection
Conceptual Captions와 MS-COCO를 학습 데이터로 사용함과 더불어서 저자들은 JFT-300M이라는 데이터를 새로 생성했다.
2.4. Mixed-Precision Training

Figure 4에 묘사되었듯이 float32와 float16을 사용하는 mixed precision을 사용했다.
2.5. Distributed Optimization

12B 모델을 학습하기 위해서 16-bit precision으로 저장되었을 때 24 GB의 메모리가 필요하다.
이는 NVIDIA V100 GPU의 16 GB를 넘기 때문에 parameter sharding 방법을 사용했다.
2.6. Sample Generation
Generating Diverse High-Fidelity Images with VQ-VAE-2 (링크) 논문과 유사하게 contrastive model인 CLIP 모델 (블로그 링크)을 활용해서 샘플을 뽑을 다음 rerank를 수행했다. 주어진 캡션과 후보 이미지에 대해서 contrastive model이 score를 매기는 방법으로 얼마나 캡션과 이미지가 잘 부합하는지 평가했다. Figure 6에 샘플의 수 N과 top $k$ 이미지의 수에 따른 영향을 보여준다. 최종적으로 N = 512, temperature reduction t = 1로 결정했다.

3. Experiments



Figure 3과 8은 DALL-E 모델의 생성 결과고 Figure 7은 DF-GAN과 DALL-E의 생성에 대한 사람의 평가 결과다.
여담
DALL-E 논문을 리뷰하기 전에 여러가지를 찾아봤는데 DALL-E 2가 흥미로워서 역시 공부해봐야겠다.
Stable Diffusion의 경우도 noise를 집어넣고 이를 복원하는 프로세스를 가진 기본 diffusion 모델의 구조만 이해했는데 더 파봐야겠다.
ELBO와 관련되어 잘 설명한 글: 링크
References:
https://littlefoxdiary.tistory.com/74
https://modulabs.co.kr/blog/variational-inference-intro
'Multimodal' 카테고리의 다른 글
| Flamingo (2022) 논문 리뷰 (0) | 2025.05.05 |
|---|---|
| Donut (2022) 논문 리뷰 (0) | 2025.05.03 |
| LLaVA (2023) 논문 리뷰 (0) | 2025.04.26 |
| BLIP (2022) 논문 리뷰 (0) | 2025.04.26 |
| LayoutLM v3 (2022) 논문 리뷰 (1) | 2025.04.25 |



