GPT-1이 제시된 논문은 Improving Language Understanding by Generative Pre-Training라는 이름이다. 가장 유명한 Decoder only 모델 중 하나이며 OpenAI의 GPT 시리즈 중 첫 모델인 기념비적인 논문이다. (링크)
해당 논문의 저자는 Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever다.
뒤에 나오겠지만 12-layers의 stack으로 이루어진 decoder only 모델이라 대략 110M 정도의 현재로 보면 작은 모델이다.
구성요소를 대략적으로 요약하면 12-layer, 768-hidden, 12-heads, 110M parameters이다. BERT base와 동일한 config다.
Abstract
최근 NLU (Natural Language Understanding)은 넓은 범위의 다양한 태스크가 존재한다. Textual entailment, question answering, semantic similarity assessment, document classification 등이다. 라벨이 되지 않은 텍스트 코퍼스는 풍부하지만 라벨링된 데이터는 희소하다. 여기서 저자들은 generative pre-training을 통해서 다양한 라벨되지 않은 데이터를 개별 specific task에 맞게 discriminative fine-tuning을 수행한다. 이를 통해서 12개의 태스크 중에서 9개의 태스크에서 성능 향상을 보였다. Stories Cloze Test (commonsense reasoning), RACE (QA), MultiNLI (textual entailment) 분야에서 성능이 향상되었다.
3. Framework
기본적으로 Transformer의 decoder 구조를 사용했다.
Unsupervised pre-training

일반적인 next token prediction을 활용해서 pre-train 단계에서 학습을 수행한다.
Supervised fine-tuning
추가적인 output layer인 $W_y$를 통해서 최종 예측 결과인 $y$를 도출한다.
이때 $x^i$는 하나의 시퀀스 안에 있는 input token들이다.

모든 input sequences와 predictions에 대해서 다음의 loss를 추가적으로 설정한다.

최종 loss인 $L_3$는 두 loss의 가중합이다.

GPT Architecture
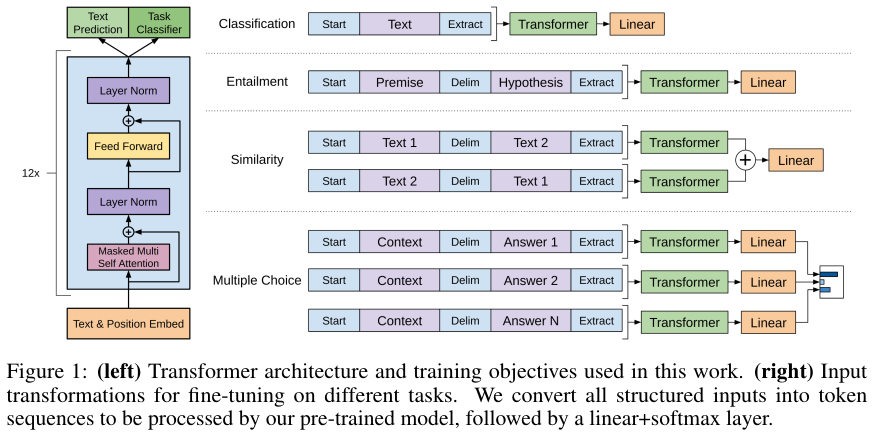
Transformer decoder layer를 12개 쌓았다.
Task-specific input transformations
Textual entailment: premise p와 hypothesis h 사이에 delimiter token $을 넣는다.
Similarity: 두 개의 문장을 delimiter인 $을 넣어서 가능한 모든 방식으로 합친다. 즉 "A $ B"와 "B $ A"를 각각 모델에 넣은 다음 더하여서 output layer에 보낸다.
Question Answering and Commonsense Reasoning: context document z, question q, a set of possible answers {$a_k$}가 있다. [z; q; $; $a_k$]로 문장들은 concat하여 k개의 input을 구성한다. 그런다음 모두 모델에 넣어서 representation을 구하고 이를 output layer에 넣는다. Output layer에서 나온 결과를 softmax로 normalized하여 개별 답변에 대한 최종 확률 분포를 구한다.
4. Experiments
Unsupervised pre-training
BooksCorpus를 데이터로 사용한다
Model Specifications
model dim은 768, layers의 수는 12, head의 수는 12다. Optimizer는 Adam이며, max learning rate는 2.5e-4다.
Lr은 처음 2000 steps에서는 linear하게 증가하며 2000 이후에는 cosine schedule을 활용하여 서서히 0으로 만든다.
Mini batch 사이즈는 64이며, contiguous sequence는 512 토큰이다. LayerNorm을 사용하며, weight initilization은 N(0, 0.02)으로 수행한다.
BPE를 활용하여 토크나이징을 수행하였으며 Vocab 사이즈는 40,000이다.
또한 L2 regularization을 사용하여 이때의 파라미터 $w$는 0.01이다.
Activation은 GELU (Gaussian Error Linear Unit)을 사용한다.
GELU
GELU는 다음과 같이 정의된다.
GELU(x)=x∗Φ(x)
이때 Φ(x)는 Cumulative normal distrubition이다.

ReLU나 Leaky ReLU와 거의 유사하지만 값이 0보다 작아지면서 점점 음의 값을 가지다가,
일정 값 이하로 내려가면 결과값이 0으로 수렴한다.
Supervised fine-tuning
GLUE 를 비롯한 여러 데이터를 활용했다.

NLI
SNLI, QNLI, MNLI, SciTail, RTE
Question answering and commonsense reasoning
RACE, CNN, SQuaD, Story Cloze Test
Semantic Similarity
Microsoft Paraphrase corpus (MRPC), the Quora Question Pairs (QQP), the Semantic Textual Similarity benchmark (STS-B)
Classification
The Corpus of Linguistic Acceptability (CoLA), The Stanford Sentiment Treebank (SST-2)
실험 결과는 아래와 같다.

BiLSTM이나 ELMo 보다 좋은 성능임을 확인할 수 있다.
References:
https://ffighting.net/deep-learning-paper-review/language-model/gpt-1/
https://pytorch.org/docs/stable/generated/torch.nn.GELU.html
'NLP' 카테고리의 다른 글
| RoBERTa (2019) 논문 리뷰 (0) | 2024.11.07 |
|---|---|
| BART (2019) 논문 리뷰 (0) | 2024.11.04 |
| BERT (2018) 논문 리뷰 (0) | 2024.06.25 |
| Transformer (2017) 논문 리뷰 (0) | 2024.06.25 |
| GRU 모델 설명 (0) | 2024.04.11 |



