자연어처리는 컴퓨터가 자연언어 (한국어, 영어, 일본어 등의 자연적으로 생성된 언어)를 이해하고 분석하고 생성할 수 있도록 만드는 기술이다.
언어학의 하위 분야 중에서 전산언어학 (computational linguistics)에서는 컴퓨터 기술을 적극적으로 활용한다. 기존에는 규칙 기반 혹은 통계 기반에서 분석을 했으나 2010년대부터는 딥러닝을 적극적으로 도입했다.
언어학의 연구 분야들은 여러가지가 있지만 AI 분야에서 주의 깊게 봐야할 분야를 대략적으로 분류하면 다음과 같다.
언어학의 분야
형태를 연구하는 음운론(Phonology), 형태론(Morphology) , 통사론(Syntax)
내용을 연구하는 의미론(Semantics)
언어의 사용을 연구하는 화용론(Pragmatics)
형태론 (Morphology) 은 언어에서 의미를 갖는 가장 작은 단위인 형태소(morpheme)을 연구하는 분야로 의미 혹은 문법적 기능의 최소 단위다. 형태소를 다룰 때는 하나의 형태소가 여러 개의 변이 형태를 가질 수 있는 이형태(allomorph)에 주의해야 한다. 영어의 경우 walk를 walk, walked 등 여러가지 형태를 갖음을 의미한다. 심층 구조(Deep structure)와 표층 구조(Surface Structure)와 구조적 모호성(Structural Ambiguity)도 주의해야 한다. 구 구조규칙(Phrase Structure Rules), 어휘 규칙(Lexical Rules), 변형 규칙(Transformational Rules)도 여기에서 연구되는 내용이다. 품사(Part of Speech, PoS)도 형태론에서 연구하는 분야로 단어를 문법적 성질에 따라서 몇 갈래로 나눈 것이다. 품사 분류의 기준으로는 기능(Function)과 형식(Form), 의미(Meaning)의 셋을 든다. 주된 기준은 기능과 형식이며 의미는 보조적인 기준인 경우가 보통이다.
의미론(Semantics) 은 단어, 구, 문장의 의미를 연구하는 분야다. 개념적 의미(conceptual meaning)과 연상적 의미(associative meaning), 의미상의 어색함(oddness), 의미자질(semantic features), 의미역(semantic roles), 행위자(agent), 대상자(theme), 동의관계(synonymn), 반의관계(antonym), 상하관계(hyponymy), 동음이철어(homophones), 동음이의어(homonyms), 다의어(polysemy), 연어(collocation) 등을 연구한다.
화용론(Pragmatics)은 화자, 청자, 시간, 장소, 상황 등의 대화의 문맥(context)를 고려하여 연구하는 언어학의 분야다. 같은 문장이라도 상황의 맥락에 따라서 다른 의미를 가진다. 문맥에는 물리적인 문맥(physical context), 언어적인 문맥(linguistic context), 직시 표현(deixis, deictic expression), 지시(reference), 추론(inference), 대용어(anaphora), 전제(presupposition), 화행(speech act) 등을 연구한다.
통사론(Syntax)은 문장의 구조를 연구하는 분야다. 단어(Word), 어절, 구(Phrase), 절(Cluase), 높임법, 시제 등등 다양한 구조를 분석한다.
이외에도 어휘론(Lexicology)이라는 낱말들이 모인 집합 속에서 낱말들 사이의 형태적, 의미론적 관계를 연구하는 분야도 알아둘만하다.
보다 자세한 언어학적 내용은 이 포스트 https://arsetstudium.tistory.com/20의 내용을 참조하면 될듯하다.
NLP 응용 분야
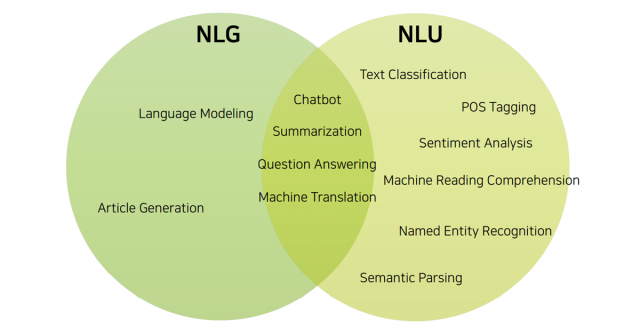
NLU (Natural Language Understanding)
컴퓨터가 자연어를 이해하게 만드는 부분이다.
Morpheme Analyzer:
형태소 분석으로, POS 태깅, 어근 추출, 어간 추출(Stemming), 표제어 추출(Lemmatization) 등.
POS (Part Of Speech) Tagging:
품사를 파악하고 분류한다
Information Extraction:
비구조적 데이터인 문장에서 구조적 데이터인 트리플(triple)을 추출한다. (주어, 관계, 목적어)와 같은 관계를 의미한다.
NER (Named Entity Recognition):
개체명 인식으로 고유명사나 특정 분야나 전문 분야의 용어를 인식한다.
BIO System과 BIESO 시스템이 있다. BIO가 더 많이 쓰인다.
BIO는 Begin, Inside, Outside로 구성되며,
BIESO는 Begining, Intemediate, End, Single Word Entity, Outside로 구성된다.
Text Classificastion:
스팸메일 필터링, 대화 의도 파악 후 분류, 이름을 통한 상품 분류, 혐오표현 분류 등이 이에 속한다.
Sentiment Analysis:
감성 분석은 문장 또는 지문의 감성을 분석하는데 긍정, 부정 등이 대표적이다.
MRC (Machine Reading Comprehension):
주어진 지문(Context)를 이해하고, 주어진 질의(Query/Question)의 답변을 추론하는 문제이다.
Semantic Parsing:
문장의 의미를 알아낸다.
NLG (Natural Language Generation)
컴퓨터가 자연어를 생성하는 부분이다.
Language Modeling:
다음 단어나 문장을 예측하는 모델이다. 과거에는 확률 기반의 모델이 주류였다.
Article Generation:
문서를 생성한다.
NLG and NLU
자연어 이해와 생성이 동시에 필요한 분야다.
Dialogue System and Chatbot:
음성, 이미지, 텍스트 형태의 인풋을 받아들여 발화 정보를 이해하고 그에 맞는 자연어 답변을 생성한다.
아웃풋 역시 음성, 이미지, 텍스트의 다양한 형태가 가능하다.
Summurization:
문서를 요약해준다. 추상적 요약과 추출적 요약 두 가지가 있다.
QA (Question Answering):
기존 검색(Information Retrieval)이 적절한 문서를 찾아준다면 QA는 질문의 의미를 파악해서 구체적인 답변까지 알려준다. ChatGPT나 Copilot이 그러한 예시다.
Machine Translation:
컴퓨터가 언어를 번역한다
References:
[업스테이지] AI 심화 학습 - NLP
자연어 처리 바이블 (임희석)
https://media.fastcampus.co.kr/knowledge/ai/nlp-korean-4reasons/
https://velog.io/@khs0415p/NLP-Machine-Reading-Comprehension
'NLP' 카테고리의 다른 글
| GRU 모델 설명 (0) | 2024.04.11 |
|---|---|
| LSTM 모델 설명과 PyTorch Implementation (0) | 2024.04.09 |
| 딥러닝 기반 NLP 모델들 (0) | 2024.03.06 |
| LLM Models and Applications (0) | 2024.02.23 |
| 눈여겨 볼만한 NLP 모델들 (0) | 2024.01.31 |



